Глубокое обучение применяется к физике и жидкостям
Глубокое обучение применяется к физике и жидкостям' can be condensed to 'Глубокое обучение - физика и жидкости'.
Численные моделирования уже много лет используются для понимания поведения физических систем: как жидкости взаимодействуют с конструкцией, как геометрия деформируется под напряжением или как распределяется тепло в условиях нагрева. Применяемые в самых различных областях, таких как аэрокосмическая, автомобильная, энергетика и т. д., эти расчеты позволяют проектировать прототипы и обеспечивать безопасные процессы, не строя их. Тем не менее, они могут быть вычислительно затратными и занимать много часов, дней или даже недель. Вот где проявляется мощь Машинного Обучения, и в частности Глубокого Обучения, сокращая время обработки до нескольких минут!
Численные моделирования динамики жидкостей
Обычное численное моделирование может описывать физические системы путем решения набора уравнений в частных производных (УЧП), которые обычно имеют следующий вид:
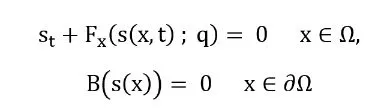
𝐹 представляет собой дифференциальный оператор на области Ω ∈ ℝ , границы 𝜕Ω и параметры 𝑞 . Решение 𝑠(𝑥, 𝑡) системы зависит от пространственных координат и времени, где индексы обозначают частные производные. Набор уравнений может быть решен путем дискретизации физической области на малые части (конечные элементы или конечные объемы), чтобы получить линеаризованную систему. Такой подход находит особое применение в гидродинамике.
- Исследование мира искусственного интеллекта Руководство для начинающих
- Google AI представляет WeatherBench 2 фреймворк машинного обучения для оценки и сравнения различных моделей прогнозирования погоды
- Построение и обучение больших языковых моделей для кода глубокое погружение в StarCoder
В гидродинамике система главным образом представлена уравнениями Навье-Стокса, набором законов, не имеющих аналитического решения, для описания поведения каждой жидкости на основе массового и силового балансов. В более простой двухмерной форме они могут быть описаны следующим образом:
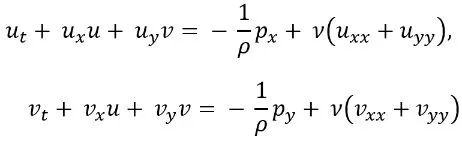
Где 𝑢 – скорость по оси 𝑥, 𝑣 – скорость по оси 𝑦, 𝑝 – давление, 𝜌 – плотность и 𝜈 – вязкость.
Численные моделирования динамики жидкостей (Computational Fluid Dynamics, CFD) заключаются в решении дискретизированной линеаризованной системы вместе с граничными условиями, такими как давление и скорость на границах области, с использованием итеративных многосеточных методов решения. Прямые методы нецелесообразны для применения в реальных приложениях, где обращение матрицы для трехмерной декартовой и равномерно разнесенной сетки (i³ элементов) имеет сложность i⁷.
Даже с эффективными решателями, работающими в параллельной вычислительной среде HPC, вычислительная стоимость таких операций может занимать много часов и стать вредными для динамического инженерного процесса. Решение? Как мы все чаще видим, Искусственный Интеллект!
Суррогатные модели
Когда возможная связь между входными и выходными данными присутствует, Искусственный Интеллект выступает в роли кандидата для моделирования такого поведения. Этот сценарий идеально подходит для CFD, где геометрическая настройка, параметризованная сеткой и ее элементами, в дополнение к граничным условиям, может быть связана с выходными данными: физическими полями (давление, скорость и т. д.) в каждой точке сетки. Построенные модели могут выступать в качестве безсеточных решателей, которые могут заменить традиционные симуляторы с более низкой вычислительной стоимостью.
В общем случае мы хотим выяснить связь между параметрами УЧП (𝑥, 𝑞, 𝑡): 𝑋 ∈ ℝⁿ и их решением 𝑠(𝑥, 𝑡): 𝑌 ∈ ℝⁿ . Другими словами, мы стремимся найти предсказательную функцию 𝐺: (𝑥, 𝑞, 𝑡) → 𝑠(𝑥, 𝑡) , где 𝑡 иногда оказывается постоянным (анализ в установившемся состоянии). Таким образом, мы можем представить различные способы сделать это.
Упрощенные модели
Самый простой подход к моделированию связи – упрощение путем сокращения размерности данных. Этот метод может быть применен как к входным, так и к выходным данным. Например, вместо использования полных координат точек сетки мы можем представить описанную выше геометрию сокращенным набором параметров, обозначаемым как 𝑘 ∈ N | 𝑘 < n. Шестеренка имеет определенное количество зубьев, примитивный радиус, ширину и т. д.
Для выходных данных жизнеспособным выбором является глобальная метрика производительности, обозначаемая как s(𝑘) ∈ N. Примеры – силы, действующие на прототип, коэффициенты сопротивления и подъемной силы и т. д.
Плюс упрощений заключается в том, что это позволяет нам применять более простые и быстрые модели искусственного интеллекта. Даже линейная/полиномиальная регрессия может использоваться без особых проблем для изучения функции 𝐺: k → 𝑠(k).
Недостатком является то, что при сокращении размерности таким образом происходит существенная потеря информации, и модели становятся менее обобщающими при работе с данными, выходящими за пределы пространства проектирования.
Объемные модели
Вместо сокращения размерности данных мы можем выбрать работу с исходной объемной сеткой (𝑌 ∈ ℝⁿ), что вводит большую сложность и требует использования методов глубокого обучения.
При работе с неструктурированной сеткой обычным подходом является интерполяция ее на равномерную структурированную сетку. Важные характеристики, такие как свободное течение и давление, могут быть встроены в каждый воксель, позволяя делать соответствующие прогнозы. В результате области, не содержащие жидкость, представлены как пустые значения, кодирующие геометрию.
Это воксельное представление облегчает использование техники, широко применяемой в задачах распознавания изображений: свертка. Сверточные нейронные сети (CNN) могут извлекать локальные и глобальные характеристики с помощью своего фильтрующего подхода. Различные масштабы извлечения характеристик могут быть достигнуты путем интеграции различных стадий, что приводит к все более сложным моделям, включая U-сети и автоэнкодеры/декодеры.
Вместо преобразования неупорядоченных данных в упорядоченную форму вокселей/изображений, другое решение заключается в активном кодировании координат. Это позволяет описывать данные в табличном формате, где каждой точке соответствует соответствующий индекс симуляции/примера. Как мы увидим в следующем разделе, это то, что делает pytorch geometric!
Хотя в теории возможно обучать и применять модель к каждой точке, этот подход обычно не удается улавливать взаимосвязи между узлами, которые являются важными для определения локальной информации. Появляются графовые нейронные сети, представляющие собой другой класс моделей, разработанных для преодоления этого ограничения.
Геометрические модели
В CFD нас часто интересует определение физических полей не в объеме, а на поверхности. Это приводит к обсуждению стратегий построения моделей. В то время как метод вокселизации, описанный ранее, показал многообещающие результаты, его применение для представления разреженных облаков точек, соответствующих геометрии, требует создания равномерной структурированной сетки. Однако это становится неэффективным для сложных геометрий, поскольку это либо приводит к излишним вычислительным затратам из-за учета нерелевантной информации вокруг формы, либо к потере ценной информации из-за грубой сетки.
Более эффективное решение предлагается областью геометрического глубокого обучения, которая в основном известна своими успехами в распознавании объектов и семантической сегментации. Этот подход тесно связан с графовыми нейронными сетями и непосредственно обрабатывает облако точек – неупорядоченное множество точек – описывая данные в виде таблицы координат и индексов, как мы упоминали в предыдущем разделе. К счастью, именно то, что у нас есть с неструктурированной сеткой!
Для описания данных в таком формате мы можем использовать pytorch geometric, расширение передовой платформы pythorch, созданное для графовых нейронных сетей и геометрических моделей. Оно также содержит серию графовых наборов данных, которые мы можем использовать, например, AirfRANS⁴, набор данных 2D NACA крыльев для RANS-симуляций. Давайте кратко рассмотрим, как это выглядит в коде:
from torch_geometric.datasets import AirfRANSfrom matplotlib import pyplot as pltdataset = AirfRANS(root='/tmp/AirfRANS', task='full', train=True) # Скачиваниеexample = dataset[0]fig, ax = plt.subplots(figsize=(12,5))ax.set_aspect('equal', adjustable="datalim")# Разброс облака точек с использованием координат x, y и давления в качестве цветаim = ax.scatter(*example.pos.T, s=0.5, c=example.y[:, 2]) fig.colorbar(im, ax=ax)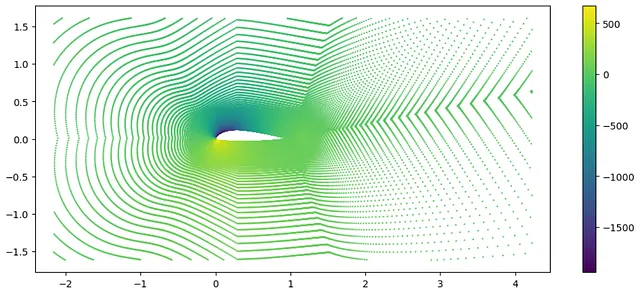
Зная характер набора данных, возникает вопрос: как мы можем обучать модели с его помощью? Мы преобразуем его в указанную выше форму с небольшой помощью Pytorch Geometric. DataLoader позволяет нам проходить через набор данных в мини-пакетах благодаря атрибуту batch, вектору, который сопоставляет каждый узел его соответствующему графу в пакете. Это является ключевым для использования агрегирующих функций в каждой симуляции, о чем мы скоро расскажем.
from torch_geometric.loader import DataLoader# Мы не разделяем тренировочные и тестовые наборы данных, а только анализируем загрузчикdataloader = DataLoader(dataset, batch_size=2) # Пакет из 2 симуляцийfor data in loader: # Цикл по набору данных, возвращающий пакеты print(data), print(data.batch) break>>> DataBatch(x=[351974, 5], y=[351974, 4], pos=[351974, 2], surf=[351974], name=[2], batch=[351974], ptr=[3])>>> tensor([0, 0, 0, ..., 1, 1, 1])После определения описания данных, какие модели подходят? Pytorch geometric предлагает широкий спектр предварительно разработанных нейронных слоев и операций, которые могут быть очень полезными. Одной из самых традиционных является, возможно, PointNet¹. Одна из первопроходцев в этой области, эта архитектура, предложенная в 2017 году, внесла два важных преимущества, которые до сих пор остаются очень важными.
Ключевым фактором успеха Pointnet является его операция пулинга. Сжимая информацию целой симуляции в один вектор, он улавливает глобальные идеи и позволяет переход от нескольких точек к единственному глобальному значению. Это эффективно решает проблему, например, применения модели к одной точке и невозможности изменения размеров модели. Другими словами, мы будем рассматривать набор данных 𝐷 = {Dᵢ | i ∈ N, 1 ≤ i ≤ m}, где m – это общее количество симуляций. Мы можем определить для каждой симуляции Dᵢ набор точек X = {Xⱼ(pⱼ, fⱼ) | j ∈ N , 1 ≤ i ≤ n}. Сцепленный вектор признаков (pⱼ, fⱼ) ∈ ℝʰ | h ∈ N. Таким образом, пулинг выполняет следующее преобразование:
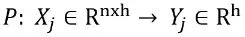
Это необходимо для задач классификации, где облако точек должно быть сведено к единичному значению или вектору. Еще одним преимуществом пулинга является внедрение глобальной информации в каждую точку, полезное для задач сегментации. Глобальный информационный вектор может быть объединен с векторами признаков каждой точки, увеличивая его размерность. Таким образом, модель, применяемая к каждой точке, будет иметь не только свою точечную информацию, но и общую представление обо всем примере. Формально, если z – это общее количество точек в неструктурированном наборе данных, то серия операций, выполняемых архитектурой Pointnet, может быть описана следующим образом:
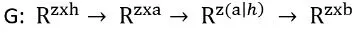
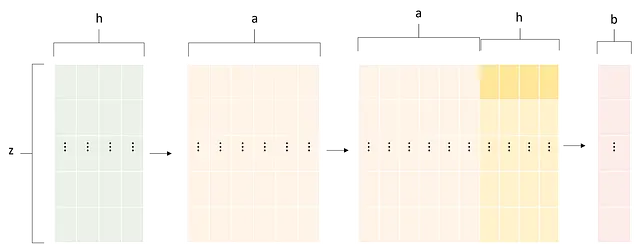
Где одна и та же MLP применяется к каждой точке/строке, а столбцы представляют признаки.
В последовательности были предложены более сложные модели. Например, Pointnet++² предложил идею использования Pointnet на разных уровнях иерархии. Этот подход не только объединяет глобальные признаки, но также включает векторы, представляющие явления меньшего масштаба. Это особенно ценно при решении проблем CFD. Например, при моделировании всего самолета возникают различные явления в различных геометрических компонентах. Крылья отличаются от турбин. Даже на более мелком масштабе существуют вариации между задней и передней частью крыла, что приводит к характерным распределениям давления.
Графовые нейронные сети обобщают вышеупомянутые концепции, изображая данные в виде ребер и вершин, отражая отношения между узлами. Таким образом, они эквивалентны сверточным нейронным сетям в том смысле, что они агрегируют локальные признаки, но вместо использования обычной сетки они могут быть непосредственно применены к неупорядоченному набору точек.
Типичная графовая нейронная сеть кодирует узел в виде вершин (vⱼ = Xⱼ), имея его координаты в качестве признаков. Ребро представляет связь между узлами и кодирует, например, расстояние между конкретным узлом и его соседями (или более сложные формулы), например, E = {(vᵢ, vⱼ) | ‖pᵢ, pⱼ‖₂ < r}, где p – это координаты, v – вершины соседей i и j в пределах расстояния r.
После вычисления этого графа он проходит через итеративные обновления для передачи локальной информации, создавая нелинейность и все более сложные вложения. Чем больше обновлений производится, тем больше узлы получают информацию из более дальних частей графа. Различные графовые архитектуры могут быть построены путем определения функции обновления, количества обновлений, способа начального построения графа, способа вычисления соседей и множества других возможных промежуточных процедур (например, остаточных соединений или даже механизма внимания). Простая процедура обновления использует агрегирующие функции следующим образом:
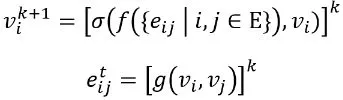
Где 𝑓 – это агрегирующая функция вершины в окрестности, обновляемая нелинейной функцией 𝜎, и 𝑔 – функция для обновления ребер, например, евклидово расстояние, которое мы определили выше.
Обобщаемая модель также должна обладать индуктивными характеристиками, такими как инвариантность к повороту, трансляции и перестановке. Классической графовой архитектурой является GraphSage³. Его низкая вычислительная сложность позволяет эффективно обучать геометрические данные с большим успехом. Он использует указанную выше формулу, указывая f как простую операцию конкатенации, за которой следует умножение на матрицу весов Wᵏ. Предлагаемые агрегаторы, в свою очередь, являются средним или максимальным пулингом, а соседи равномерно выбираются с фиксированным размером из всего набора.
Помимо описанных более простых моделей, в последние годы были разработаны более сложные и современные графовые архитектуры, которые являются перспективным направлением исследований.
Представление физики
Теперь, когда мы определили подходящие модели, возникает вопрос: как эффективно включить уникальные характеристики физических систем? Один из часто используемых подходов заключается в применении физических законов с помощью мягких ограничений или методов штрафов. Конкретно, физически информированные нейронные сети (PINN) реализуют эту стратегию, налагая штраф на модель с использованием остатка ОДУ, тем самым обеспечивая их точное соблюдение. Когда речь идет о ЧДМ, это уравнения Навье-Стокса. Частные производные в каждом уравнении могут быть рассчитаны из прогноза модели с использованием автоматического дифференцирования с помощью фреймворка глубокого обучения. Аналогичным образом, как граничные условия Дирихле, так и граничные условия Неймана могут быть включены с использованием той же методологии. В результате такой подход приводит к уточненному формату функции потерь:
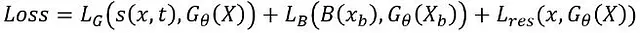
Где LG и LB представляют, соответственно, потери данных и граничных условий, образуя функцию с двумя аргументами; Lᵣₑₛ – функция остатка ОДУ; Xb и xb – входные данные модели и ОДУ на точках граничных условий; B извлекает сами значения граничных условий; G𝜃 – прямая функция сети с параметрами 𝜃.
Таким образом, модель учитывает как баланс давления, так и баланс скорости, и лучше обобщается на невидимые данные.
Выражение функции потерь подчеркивает, что PINNs могут использоваться в контролируемом подходе, основанном на данных и физике. Тем не менее, термин LG является необязательным, и сеть может быть обучена в неконтролируемом режиме. Это приведет к значительно большему пространству решений. Поскольку начальные предсказания по своей сути являются случайными, оптимизация сети представляет собой сложную задачу, и определение подходящей целевой функции остается открытым вопросом в области машинного обучения. Можно представить различные решения, от альтернативных функций потерь и стратегий оптимизации до применения жестких ограничений на граничные условия, где компонент сети должен непосредственно соответствовать указанным значениям.
Сигналы высокой частоты
Геометрические модели глубокого обучения сталкиваются с проблемой медленной сходимости и трудностями в обучении функций высокой частоты. Это явление особенно заметно в гидродинамике, особенно при работе с турбулентными потоками. Для решения этой проблемы предлагаются стратегии в рамках области неявных нейронных представлений.
Эти преобразования основаны на том, что глубокие сети имеют предвзятость к изучению функций с низкой частотой. В результате эти техники могут быть полезны для улучшения представления функций высокой частоты. Примером является расширение с помощью фурье-функций:
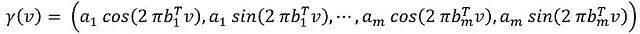
Использование этой техники с нейронными сетями облегчает обучение функций высокой частоты в низкоразмерных пространствах проблем, таких как геометрические контексты. Изменение параметра частоты позволяет управлять спектром частот, которые модель может улавливать.
На практике превосходные результаты достигаются при установке aⱼ = 1 и выборе bⱼ из случайного распределения. Точная настройка может выполняться на стандартное отклонение этого распределения, обычно гауссовское. Более широкое распределение ускоряет сходимость для компонентов высокой частоты, что приводит к улучшенным результатам (особенно в задачах, связанных с изображениями, что приводит к более четкому определению). С другой стороны, чрезмерно широкое распределение может привести к появлению артефактов на выходе (шумное изображение), что представляет собой компромисс между недообучением и переобучением.
Более современный подход может быть достигнут с использованием синусоидальных сетей представления (SIREN). Они предлагают периодические активационные функции в форме:
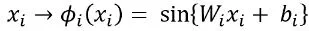
Помимо улучшения представления высокой частоты, SIREN также являются дифференцируемыми. Это происходит потому, что производная от SIREN сама является SIREN, аналогично тому, как производная синуса является косинусом: синус с сдвигом фазы. Не все обычные функции активации обладают этим свойством; например, ReLU имеет разрывную производную и нулевую вторую производную везде. Некоторые другие функции действительно обладают этим желательным свойством, такие как Softplus, Tanh или ELU; однако их производные могут быть плохо определены и не могут хорошо представлять искомые мелкие детали.
Поэтому они отлично подходят для представления обратных задач, таких как уравнения в частных производных, которые нас так интересуют. Кроме того, было доказано, что SIREN сходятся быстрее, чем другие архитектуры.
Для достижения задуманных результатов важна подходящая схема инициализации. Эта инициализация сохраняет распределение активации во всей сети, чтобы обеспечить независимость конечного вывода от количества слоев. Решение заключается в применении равномерной схемы инициализации следующим образом:
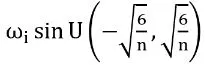
, чтобы вход в каждую единицу был нормально распределен с стандартным отклонением 1. Кроме того, первый слой сети должен охватывать несколько периодов на интервале [-1, 1], что можно достичь, используя ω₀ = 30 в sin(ω₀ ⋅ 𝑊𝑥 + 𝑏) ; это значение должно изменяться в зависимости от частоты моделируемой функции и количества наблюдений. Ограничение использования одной частоты позже было устранено с помощью так называемых модулированных SIREN.
Заключение
Надеюсь, теперь у вас более ясное представление о том, как глубокое обучение может создавать заменяющие модели для численных симуляций, даже при работе с неструктурированными и зашумленными данными. Улучшение способности сети к обобщению можно достичь с помощью различных техник. Они варьируются от включения физики основных уравнений в частных производных (УЧП) до использования неявного нейронного представления и других, которые мы не имели возможности исследовать. Это динамичное исследовательское направление готово значительно расшириться в следующие годы, становясь более надежным. Несмотря на свое название, этот подход не стремится заменить численные симуляции. Вместо этого он предлагает более быструю альтернативу, используя сами симуляции и даже экспериментальные данные. Если мы можем объединить симуляции динамики жидкости, физические уравнения и глубокое обучение, почему ограничиваться только одним из них?
Ссылки
[1]: PointNet
C. R. Qi, H. Su, K. Mo, L. J. Guibas, PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation, arXiv:1612.00593 [cs]ArXiv: 1612.00593 (Apr. 2017). URL http://arxiv.org/abs/1612.00593
[2]: PointNet++
C. R. Qi, L. Yi, H. Su, L. J. Guibas, PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space, arXiv:1706.02413[cs] ArXiv: 1706.02413 (Jun. 2017). URL http://arxiv.org/abs/1706.02413
[3]: GraphSage
W. L. Hamilton, R. Ying, J. Leskovec, Inductive Representation Learning on Large Graphs, arXiv:1706.02216 [cs, stat]ArXiv: 1706.02216 (Sep. 2018). URL http://arxiv.org/abs/1706.02216
[4]: AirfRANS
F. Bonnet, A. J. Mazari, P. Cinnella, P. Gallinari, Airfrans: High fidelity computational fluid dynamics dataset for approximating reynolds averaged navier-stokes solutions (2023). arXiv:2212.07564.
[5]: Point-GNN
W. Shi, R. R. Rajkumar, Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud (2020) IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 1708–1716.
[6]: Scientific Machine Learning through Physics-Informed Neural Networks: Where we are and What’s next
S. Cuomo, V.S. Di Cola, F. Giampaolo, Scientific Machine Learning Through Physics–Informed Neural Networks: Where we are and What’s Next. J Sci Comput 92, 88 (2022). https://doi.org/10.1007/s10915-022-01939-z
[7]: Learning differentiable solvers for systems with hard constraints
G. Negiar, M.W. Mahoney, A.S. Krishnapriyan, Learning differentiable solvers for systems with hard constraints (2022). ArXiv, abs/2207.08675.






