Исследование больших языковых моделей – Часть 2
Исследование больших языковых моделей - Часть 2' - 'Researching large language models - Part 2
Эффективное использование LLMs: поиск информации, персональные ассистенты, причинно-следственные агенты, объяснимость и иерархическое управление на основе развертывания.
Эта статья написана в основном для самостоятельного изучения. Она охватывает широкий диапазон и идет в глубину. Вы можете пропустить некоторые разделы в зависимости от ваших интересов или найти область, которая вас интересует.
Ниже приведены некоторые вопросы, которые меня заинтриговали или возникли в процессе настройки LLMs. Статья является попыткой ответить на них и поделиться этой информацией с другими любознательными.
Поскольку LLMs основаны на нейросетях с функцией потерь, не является ли весь тренировочный процесс LLMs обучением с учителем? Почему он обычно называется обучением без учителя? Можно ли обучить LLM в очень коротком предложении, чтобы показать, как работает тренировка LLM на практике? Что такое Маскированный и Причинный языковые модели? Можете ли вы объяснить интуицию за Архитектурой Трансформера на одной картинке? Что именно подразумевается под обучением без учителя в LLM? Почему главный архитектор ChatGPT — Илья Суверскер считает обучение без учителя священной Граалью машинного обучения? Что подразумевается под Эмердженсом/Пониманием LLMs?
Какие применения у LLMs? Почему LLMs наиболее подходят в качестве производительных ассистентов? Что такое Векторная БД/Шаблон встраивания информации? Могут ли LLMs использоваться для чего-то, кроме текстовых задач? Что такое причинное мышление? В чем проблема с LLMs? Почему люди вроде Яна ЛеКуна считают текущие LLMs безнадежными? Могут ли LLMs быть объяснимыми, и как их можно эффективно использовать, если они этим не являются?
- Изучение больших языковых моделей – Часть 3
- Обучение с подкреплением SARSA и Q-обучение – Часть 3
- Идеальная пара adidas и Covision Media используют искусственный интеллект и NVIDIA RTX для создания фотореалистичного 3D-контента
Почему необходимо настраивать/переобучать LLMs? Почему сложно обучать LLMs? Как квантование и LoRA помогают в обучении больших LLMs? Как работают квантование и LoRA? Какой эффективный способ настраивать предварительно обученные LLMs? Что такое Научная настройка? Что такое Самоинструкт? Как можно создать качественный набор данных для обучения Научной настройки?
Остается без ответа. Можете ли вы показать, как LLMs различной способности могут быть иерархически структурированы для создания сложной автоматизации с причинно-следственным мышлением? Почему мы стремимся создать искусственный интеллект, подобный человеческому, с помощью LLMs или нейронных сетей? Почему это кажется странно похожим на создание птичьего полета задолго до изобретения самолета с фиксированным крылом?
Поскольку статья довольно длинная, я разделил ее на три части для лучшей читаемости.
Часть 1 будет обсуждать эволюцию тренировки LLMs. Цель состоит в том, чтобы создать контекст, чтобы мы могли понять магию, или более технически – эмердженс, которая начинает происходить, когда размер модели превышает порог и когда ее обучают огромными данными. Разделы с подробным анализом их также позволяют легко следовать большинству программистов.
Часть 2 будет кратко обсуждать популярные применения LLMs, персональных ассистентов и чат-ботов с настраиваемыми данными с помощью шаблонов поиска информации (поиск векторного пространства с дополнением LLM). Мы также рассмотрим идеи о том, как модель мышления и NLU могут стать более мощными применениями. В этом контексте мы рассмотрим одно основное ограничение модели LLM, сопоставив преимущества обучения с учителем с недостатками моделей LLM — отсутствием объяснимости или сложностью определения фактов по сравнению с галлюцинациями. Мы рассмотрим, как такие системы были очень эффективно использованы в компьютерных системах с помощью иерархии управления, ненадежные системы становятся надежными благодаря более высокому уровню управления — примером является наше ежедневное использование ChatGPT и как это можно распространить на другие случаи использования.
Часть 3 будет обсуждать некоторые концепции, связанные с обучением LLMs на пользовательских доменах. Мы нацеливаемся на понимание области в этой части и на то, насколько оно более мощное, чем простые шаблоны поиска информации векторного пространства. Это легко сделать в игрушечных примерах, но на практике не очень просто с реальными данными. Мы рассмотрим, как техники квантования открыли очень большие LLMs миру и как это, в связке с концепциями сокращения параметров обучения, демократизировало настройку LLMs. Мы рассмотрим основную технику эффективной настройки — Научную настройку, и как решить самую большую практическую проблему Научной настройки — отсутствие набора качественных инструкционных данных с учетом всех концепций, которые мы рассмотрели до сих пор.
Будущие разделы будут обсуждать концепцию использования понимания LLMs и использования иерархии управления для усиления систем искусственного интеллекта/машинного обучения.
Одно из основных применений – это повышение производительности – умный помощник.
Это важный и широко используемый шаблон для LLM. В статье “Экономический потенциал генеративного искусственного интеллекта – следующая производительностная граница” (июнь 2023 года) McKinsey & Company приводятся прогнозы о том, как этот аспект LLM, применяемый в различных форматах, может изменить текущую работу в разных секторах и добавить трлн долларов к мировой экономике.
Прежде чем мы перейдем к конкретике, хотелось бы упомянуть о недавней беседе, в которой автор говорит о том, как можно создавать более надежные системы на основе менее надежных систем – цитируя известную конструкцию стека TCP/IP. Здесь используется многоуровневая архитектура, в которой ненадежные/пропускающие пакеты уровни IP становятся надежными благодаря уровню TCP, который отслеживает потери пакетов и выполняет их повторную передачу.
Тип использования помощника также многоуровневый, где слабости LLM, такие как галлюцинации, преодолеваются более высоким и лучшим управлением (обычно человеком)
Это может быть также более когнитивной моделью по сравнению с менее развитыми моделями. Именно это делает этот случай использования таким широко распространенным и надежным. Программисты, использующие Github Co-pilot, являются классическим примером. Вывод модели сопровождается лучшим управлением, которое может эффективно использовать вывод, извлекать положительные моменты и настраивать или отбрасывать отрицательные (ошибки, галлюцинации). Чем более опытен человек, тем более эффективно он/она может использовать эти модели. Высокая эффективность такого подхода в качестве помощника по программированию или помощника в определенной области хорошо известна с самого начала его внедрения. То же самое относится к случаю, когда такие помощники разрабатываются для других областей, например, недавнему примеру Med-Palm2 от Google и его необычайной способности помогать врачам в медицинской сфере.
Необходимость в лучшем управлении неявно связана с концепцией объяснимости.
Объяснимость и ее влияние.
Мы упомянули здесь случай использования помощника, многоуровневый подход и Med_Palm2. В этом неявно присутствует концепция объяснимости.
Объяснимость сейчас является слабостью LLM.
Вот мнение Янна ЛеКана. Он говорит об этом довольно откровенно:
Авторегрессионные LLM на самом деле плохи! Они хороши в качестве помощников. Они не могут предоставлять фактические и последовательные ответы (из-за галлюцинаций) с учетом последних данных (установка всегда устаревшая)
Авторегрессионные LLM обречены. Их нельзя сделать фактическими, и это невозможно исправить (без крупной переработки) …
Отсутствие объяснимости требует более высокого уровня управления и меньшей степени автоматизации. Мы уже рассмотрели популярный случай использования помощника в определенной области, а также каждодневное использование случая использования, когда мы, люди, являемся контролирующим уровнем.
Но когда мы говорим о ИИ/МО, мы стремимся к автоматизации на основе компьютера. Чтобы привести пример вне LLM-сценария и предложить некоторые мысли, давайте рассмотрим, как сверточные нейронные сети революционизировали компьютерное зрение и как они эффективно преодолевают эту проблему объяснимости.
Даже лучшие модели компьютерного зрения не имеют понимания изображений. Следовательно, очень легко обмануть эти модели с помощью адверсарных изображений, чтобы предсказать что-то другое. Модель, обученная на обнаружение, скажем, некоторых болезней по медицинским изображениям, нельзя доверять, независимо от того, была ли она изменена или выбрала что-то на изображении, что представляет себя как похожее на адверсарное изображение. (Самоуправляемые автомобили, полагающиеся на камеры, иногда неправильно интерпретируют – иногда с фатальными последствиями – граничные случаи)
Лучшее управление – здесь требуется рассмотрение врачом. Однако, если бы врачу пришлось рассмотреть мельчайшие детали изображений, то автоматизация не имела бы особого смысла. Именно здесь визуальная объяснимость используется в компьютерном зрении для таких случаев использования. Врачу потребуется некоторое объяснение того, почему модель предсказала так, как она сделала – объяснимость предсказания. Для компьютерного зрения это может быть визуально представлено с использованием алгоритмов Grad-CAM. Ниже мы видим, что модель действительно выбирает соответствующие особенности для предсказания, что изображение содержит французский рог. В медицинской сфере, где объекты не так очевидны, это помогает ускорить диагностику с эффективным контролем.

Для других моделей глубокого обучения, основанных на данных, понятие объяснимости относится к комбинациям признаков, выбранным моделью для своего прогноза. Объяснимость является сложной проблемой во всех областях машинного обучения, особенно в случае использования глубокого обучения, когда исходно слишком много признаков для правилового движка или человека, чтобы установить корреляцию. Но всё же, в некоторой степени это возможно в наблюдаемых обученных системах машинного обучения путем удаления признаков и проверки, как это влияет на выход модели и другие подобные методы.
Пока такие техники не будут изобретены для языковых моделей, необходимо будет тщательно контролировать процесс, поскольку нет способа определить галлюцинации. Другой альтернативой является использование их в сценариях, где некоторые ошибки не имеют большого значения. Мы рассмотрим один такой случай использования, в котором мы используем языковые модели для создания обучающих данных для обучения языковых моделей в разделе 3. Существует много других случаев использования, таких как более точные рекомендательные системы продуктов и подобные, где несколько ошибок не имеют значения.
Языковые модели в качестве поисковых систем (LLM расширенный поиск информации)
Это крайне популярный и растущий случай использования, с частым появлением новых участников. Вы можете задаться вопросом, почему это намного лучше, чем традиционный корпоративный поиск на основе индексирования ключевых слов.
Основная техническая интуиция здесь – это векторное вложение и поиск похожести; и основная нетехническая интуиция в отличие от других корпоративных поисков (например, ElasticSearch) заключается в том, что это использует концепцию контекстуальных вложений слов/предложений.
В то время как обычные поисковые системы индексируют каждое слово (или концепцию обратного индекса ES), в этом каждое предложение группируется в соответствии с тем, насколько оно похоже на другие предложения. Теоретически это делает его гораздо более эффективным агентом поиска информации. Нам нужно вернуться к части 1 и посмотреть, как трансформеры помогают в этом с помощью своего механизма внимания, чтобы лучше понять это. Кроме того, первая часть этой статьи более подробно объясняет это для GPT2.
На практике это делается путем вычисления высокоуровневого вложения или семантического вложения данных с использованием предварительно обученных моделей (популярные SentenceTransformers) и некоторых библиотек, таких как FAISS (Facebook AI Similarity Search) для быстрого поиска похожести на основе этих вложений в отношении аналогично вычисленного вектора пользовательского запроса. Вместо вложения или в дополнение к нему, FAISS или аналогичные технологии представляют собой постоянно растущие векторные базы данных – Pinecone, Weviate, Milvus и т. д. См. эту статью Forbes.
DeepDive – все документы сначала разбиваются на компоненты (предложения, абзацы или даже документы с URL-адресами и некоторой информацией в качестве метаданных) и преобразуются в векторные вложения с использованием модели, например Sentence Transformers. (Представьте их как плавающие в N-мерном пространстве (N – очень большое число), и похожие векторы сгруппированы в этом векторном пространстве).
Вот блокнот Colab, в котором используется SentenceTransformer и FAISS с локальным хранилищем для этого шаблона: https://colab.research.google.com/drive/1PU-KEHq-vUpUUhjbMbrJip6MP7zGBFk2?usp=sharing. Обратите внимание, что у Langchain есть более простые обертки над многими библиотеками, и это то, что мы используем выше. Прямой способ немного более криптичен, см. этот colab-блокнот.
Семантическое вложение частей используется как векторное вложение. Например, если вы используете LamaCPPEmbedding, вы можете увидеть, как выбираются логиты из оценки модели, где вложение последнего слова используется для представления предложения. langchain -> lmacpp(python) -> lamacpp (c++)
Преимущество такого подхода заключается в том, что вычисление векторных вложений и их хранение и последующее использование этих данных проще, чем донастройка модели. Недостатком является то, что выбор данных основан не на понимании пользовательского запроса, а на разделении на основе слов в запросе с помощью механизма внимания/семантического вложения. Модель не имеет “понимания” предметной области, как мы объяснили ранее. Поскольку используется предварительно обученная модель, она понимает запрос и может использовать контексты из поиска похожести для создания содержательного ответа.
Обычно этого достаточно для многих применений. Но если вы чувствуете, что вы не получаете такую же эффективность вывода, как, например, с ChatGPT или Bard, то вариантом является донастройка модели для вашей пользовательской области.
Языковые модели в качестве агентов причинно-следственного рассуждения
Связанное с объяснимостью, которую мы ранее обнаружили, является понятие причинности в машинном обучении (SHAP, LIME, книга “Почему” – Джудея Перл более подробно объясняет это понятие, но это выходит за рамки данной статьи).
Простыми словами, это рассуждение о причине и следствии. Представьте, как ранние люди ассоциировали причину и следствие. Однажды они проводили ритуальный танец, и на следующий день пошел дождь.

Это повторилось еще один или два раза, и они связали эти два факта. Ассоциация – это первый шаг на лестнице причинного мышления, но не единственный.
Как сказал Джудея П., все наши системы искусственного интеллекта находятся на этом шаге. (Полагаю, что многие из нас, людей, также находятся здесь). Простые люди будут танцевать в следующий раз, когда будет идти дождь. Теперь, если говорить о наших предках-примере, предполагая, что они танцевали каждый раз, когда шел дождь, почти невозможно убедить кого-либо в обратном.
За исключением случаев, когда они «не» танцевали, и все равно шел дождь, или они танцевали, но дождя не было. Первый шаг, «Ассоциация», также может быть представлен как «Видение», следующий – «Действие», а третий – «Воображение» (как в книге).
Надеюсь, это поможет нам понять, что причинное мышление требует понимания, а не только ассоциации (как ассоциации между токенами).
Интересная статья от Microsoft Research, которая использует LLMs для обнаружения причинности
Мы обнаружили, что методы на основе LLM устанавливают новую точность, которая является лучшей на нескольких причинных тестах.
Я проверил те же подсказки в статье с помощью ChatGPT 4, и он дал лучшие результаты, чем они получили ранее с той же моделью; это не означает много, но все же иллюстрирует их способность к причинному мышлению “из коробки”.
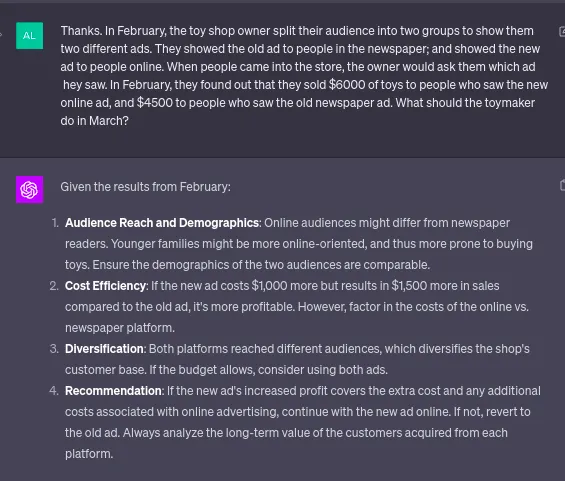
Обратите внимание, здесь не было упоминания онлайн и офлайн демографии и т. д. Модель GPT4 сама выбрала помехи и рассуждала не только на основе данных, но и на основе своего мировоззрения. Как описано авторами, LLMs не являются идеальными в этом, и они делают ошибки.
Опять же, мне сейчас не так легко продемонстрировать это на простом примере, но это увлекательное поле для исследования. Мне особенно нравится этот цитат из статьи, которая практически обходит споры о том, являются ли они имитаторами или нет, и использует эти возможности на практике.
Независимо от того, выполняют ли LLMs действительно причинное мышление или нет, их эмпирически наблюдаемая способность выполнять определенные причинные задачи достаточно сильна, чтобы предоставить полезное дополнение для аспектов причинного мышления, где мы в настоящее время полагаемся только на людей.
То есть, хотя эти системы сами по себе трудно объяснить, их можно использовать как инструменты для обнаружения причинных связей между переменными в наборе данных. Это иллюстрирует их потенциальные возможности в задачах высокоуровневого мышления.
В части 3 мы рассмотрим, как настраивать модели, используя сами модели для помощи в генерации данных и как это может увеличить их применение в настраиваемых областях применения.




