Практическое занятие с обучением с учителем линейная регрессия
Линейная регрессия в практическом занятии с учителем

Основной обзор
Линейная регрессия – это фундаментальный алгоритм машинного обучения с учителем для прогнозирования непрерывных целевых переменных на основе входных признаков. Как следует из названия, он предполагает, что отношение между зависимой и независимой переменной является линейным. Поэтому, если мы попытаемся построить график зависимой переменной Y от независимой переменной X, мы получим прямую линию. Уравнение этой линии может быть представлено следующим образом:
- Техники ансамблевого обучения обзор Random Forest в Python
- Могут ли большие языковые модели самооцениваться на предмет безопасности? Знакомьтесь с RAIN новым методом вывода, преобразующим согласование и защиту искусственного интеллекта без донастройки.
- Как построить многофункциональную систему с несколькими графическими процессорами для глубокого обучения в 2023 году
Где,
- Y Предсказанное значение.
- X = Входной признак или матрица признаков в множественной линейной регрессии
- b0 = Перехват (точка пересечения линии с осью Y).
- b1 = Наклон или коэффициент, определяющий крутизну линии.
Основная идея линейной регрессии заключается в поиске наилучшей линии подходящей для наших точек данных, чтобы ошибка между фактическими и предсказанными значениями была минимальной. Она делает это, оценивая значения b0 и b1. Затем мы используем эту линию для проведения прогнозов.
Реализация с использованием Scikit-Learn
Теперь вы понимаете теорию линейной регрессии, но чтобы укрепить наше понимание, давайте построим простую модель линейной регрессии с использованием Scikit-learn, популярной библиотеки машинного обучения на языке Python. Пожалуйста, следуйте за нами для лучшего понимания.
1. Импортирование необходимых библиотек
Сначала вам понадобится импортировать необходимые библиотеки.
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
2. Анализ набора данных
Вы можете найти набор данных здесь. Он содержит отдельные файлы CSV для обучения и тестирования. Давайте отобразим наш набор данных и проанализируем его перед продолжением.
# Загрузка обучающего и тестового наборов данных из файлов CSV
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# Отобразить первые несколько строк обучающего набора данных, чтобы понять его структуру
print(train.head())
Результат: 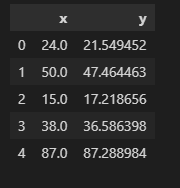
Набор данных содержит 2 переменные, и мы хотим предсказать y на основе значения x.
# Проверить информацию о наборе данных обучения и тестирования, такую как типы данных и отсутствующие значения
print(train.info())
print(test.info())
Результат:
RangeIndex: 700 entries, 0 to 699
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 700 non-null float64
1 y 699 non-null float64
dtypes: float64(2)
memory usage: 11.1 KB
RangeIndex: 300 entries, 0 to 299
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 300 non-null int64
1 y 300 non-null float64
dtypes: float64(1), int64(1)
memory usage: 4.8 KB
Вышеуказанный вывод показывает, что у нас есть отсутствующее значение в обучающем наборе данных, которое можно удалить следующей командой:
train = train.dropna()
Также проверьте, содержит ли ваш набор данных дубликаты и удалите их перед подачей на модель.
duplicates_exist = train.duplicated().any()
print(duplicates_exist)
Вывод:
False
2. Подготовка набора данных
Теперь подготовьте обучающие и тестовые данные и целевую переменную с помощью следующего кода:
# Извлечение столбцов x и y для обучающего и тестового набора данных
X_train = train['x']
y_train = train['y']
X_test = test['x']
y_test = test['y']
print(X_train.shape)
print(X_test.shape)
Вывод:
(699, )
(300, )
Вы можете видеть, что у нас есть одномерный массив. В то время как технически вы можете использовать одномерные массивы с некоторыми моделями машинного обучения, это не является наиболее распространенной практикой, и это может привести к непредвиденному поведению. Поэтому мы изменим форму на (699,1) и (300,1), чтобы явно указать, что у нас есть одна метка для каждой точки данных.
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1,1)
Когда признаки находятся на разных шкалах, некоторые из них могут доминировать в процессе обучения модели, что приводит к некорректным или неоптимальным результатам. Для этой цели мы выполняем стандартизацию, чтобы наши признаки имели среднее значение 0 и стандартное отклонение 1.
До:
print(X_train.min(),X_train.max())
Вывод:
(0.0, 100.0)
Стандартизация:
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print((X_train.min(),X_train.max())
Вывод:
(-1.72857469859145, 1.7275858114641094)
Теперь мы закончили с основными шагами предварительной обработки данных, и наши данные готовы для обучения.
4. Визуализация набора данных
Важно сначала визуализировать связь между нашей целевой переменной и признаком. Вы можете сделать это, создав диаграмму рассеяния:
# Создание диаграммы рассеяния
plt.scatter(X_train, y_train)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Диаграмма рассеяния обучающих данных')
plt.grid(True) # Включение сетки
plt.show()
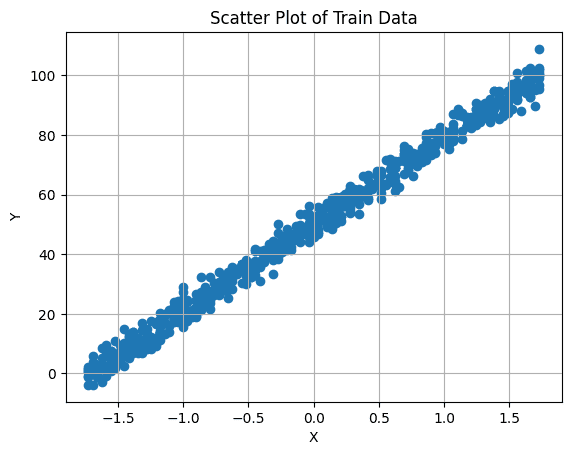
5. Создание и обучение модели
Теперь мы создадим экземпляр модели линейной регрессии с помощью Scikit Learn и попробуем подогнать ее к нашему обучающему набору данных. Она находит коэффициенты (наклоны) линейного уравнения, которое наилучшим образом соответствует вашим данным. Эта линия затем используется для прогнозирования. Код для этого шага следующий:
# Создание модели линейной регрессии
model = LinearRegression()
# Подгонка модели к обучающим данным
model.fit(X_train, y_train)
# Использование обученной модели для прогнозирования значений целевой переменной для тестовых данных
predictions = model.predict(X_test)
# Расчет среднеквадратичной ошибки (MSE) в качестве метрики оценки производительности модели
mse = mean_squared_error(y_test, predictions)
print(f'Среднеквадратичная ошибка: {mse:.4f}')
Вывод:
Среднеквадратичная ошибка: 9.4329
6. Визуализация регрессионной линии
Мы можем построить нашу регрессионную линию с помощью следующей команды:
# Построение регрессионной линии
plt.plot(X_test, predictions, color='red', linewidth=2, label='Регрессионная линия')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Модель линейной регрессии')
plt.legend()
plt.grid(True)
plt.show()
Вывод: 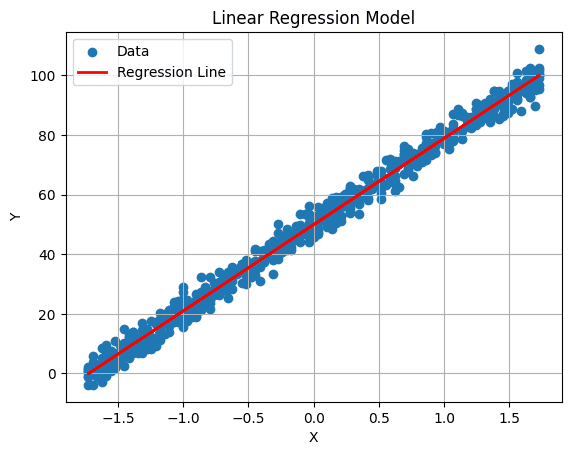
Заключение
Вот и все! Теперь вы успешно реализовали фундаментальную модель линейной регрессии с использованием Scikit-learn. Навыки, которые вы приобрели здесь, могут быть применены для работы с сложными наборами данных с большим количеством признаков. Это интересный вызов, который стоит исследовать в свободное время и который открывает двери в захватывающий мир решения проблем на основе данных и инноваций. Канвал Мехрин – начинающий разработчик программного обеспечения с большим интересом к науке о данных и применению искусственного интеллекта в медицине. Канвал была выбрана Google Generation Scholar 2022 для региона APAC. Канвал любит делиться техническими знаниями, публикуя статьи на актуальные темы, и страстно стремится улучшить представительство женщин в технологической индустрии.