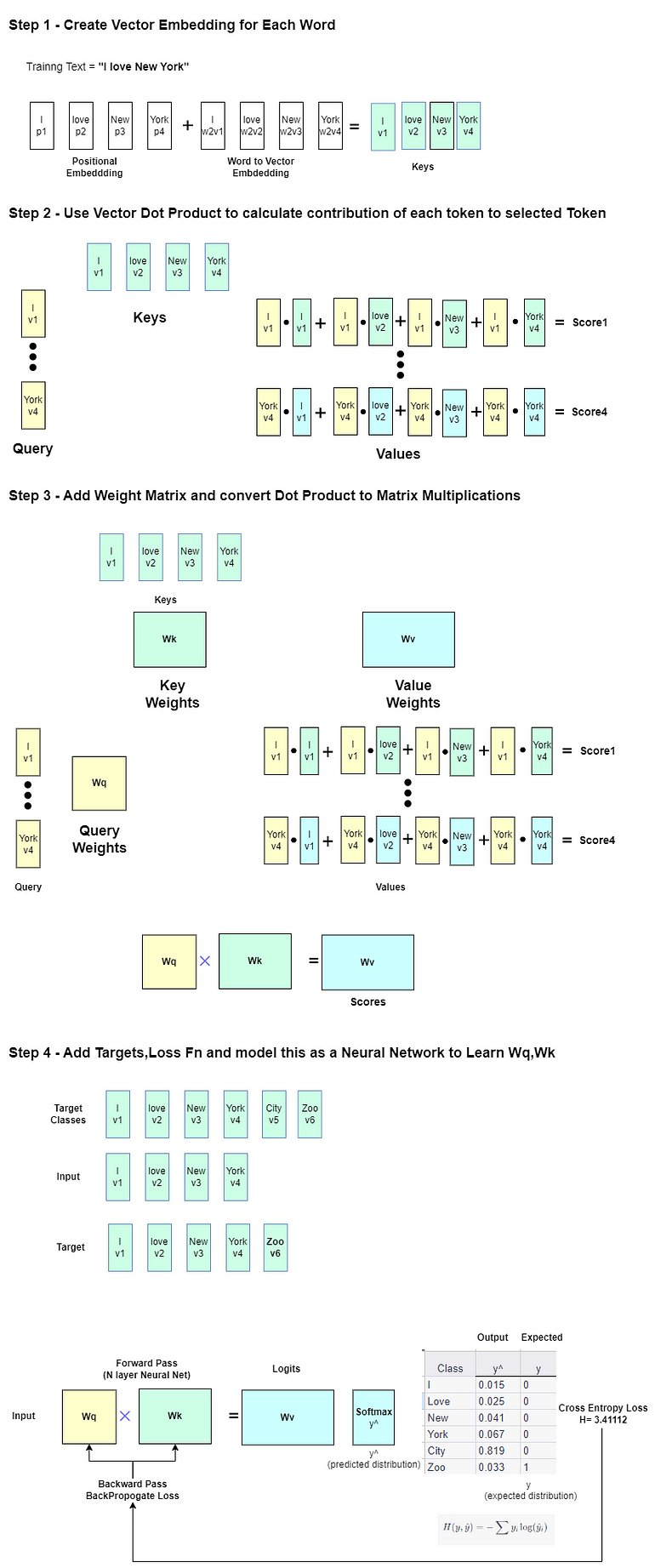
Общение по вашим требованиям мой путь применения генеративного искусственного интеллекта (LLM) к программным требованиям
Мой путь - генеративный искусственный интеллект (LLM) для программных требований.
В эпоху цифровых технологий крупные предприятия страдают от недостатка понимания своих устаревших систем и процессов. Знания изолированы в силосах, разбросанных среди различных команд и экспертов по определенным вопросам. Эта фрагментация значительно способствует росту технического долга, тихого убийцы, который постепенно затрудняет гибкость и производительность организации. В Curiosity Software мы провели последние пять лет, создавая структурированные требования (через визуальные модели) и связываясь с сотнями инструментов DevOps. Мы считаем, что это ставит нас в невероятно привилегированное положение при внедрении генеративного ИИ. Модели и артефакты DevOps могут выступать в качестве центральной точки доступа к данным, протекающим через программный ландшафт разработки организации.
В рамках нашей миссии по борьбе с распространенными проблемами технического долга и отсутствия знаний мы отправились в путешествие, чтобы применить большие языковые модели (LLM) к требованиям программного обеспечения и бизнес-логике. Нашей целью было создание центра знаний для требований программного обеспечения организации, который можно запросить, чтобы обнаружить знания и погасить технический долг.
Понимание территории больших языковых моделей (LLMs)
Прежде чем обсуждать наши опыт и понимание, давайте создадим краткий обзор больших языковых моделей. LLM, такой как GPT-4 от OpenAI, способны понимать и генерировать человеческий язык. Они учатся на огромном корпусе данных, охватывающем широкий спектр тем и стилей языка.
Эти LLM работают на модели глубокого обучения, известной как Трансформер, который использует слои механизмов само-внимания (нейронные сети) для анализа и понимания контекста в данных. Во время обучения они читают бесчисленное количество предложений и абзацев и делают прогнозы о том, что будет дальше в предложении. Эти прогнозы основаны на том, что они прочитали до сих пор:
- Создание пользовательских навыков для чат-ботов с помощью плагинов
- Тренировка на основе популяции (PBT) настройка гиперпараметров
- Обучение представлению на графах и сетях
Удивительная вещь в LLM заключается в его способности генерировать текст, похожий на человеческий. Это происходит, когда он обучен на большом корпусе данных и имеет большое количество параметров или весов в модели (GPT-4 имеет сотни миллиардов):
Эта невероятная способность реагировать как человек объясняется не только интеллектом, заложенным в алгоритме, но и открытием того, что человеческий язык может быть не так сложным, как мы сначала думали.
Подвергая нейронную сеть достаточному количеству примеров человеческого языка, LLM может распознавать паттерны и адекватно отвечать на запросы. С увеличением размера и качества данных, на которых обучается LLM, его мощность растет в геометрической прогрессии.
Структурированные данные являются ключевыми факторами успеха LLM
Для современных программных организаций возможность использования LLM никогда не казалась такой близкой. Существуют невероятно компактные специализированные модели, которые могут работать на локальном компьютере и не уступают по производительности GPT-3.5.
Однако самой важной частью LLM не является доступный инструментарий, а данные, на которых LLM был обучен. Поэтому это также главное препятствие для успешного использования LLM, так как сегодня организации не имеют структурированных данных в области программного обеспечения.
Требования программного обеспечения обычно хранятся в неструктурированном текстовом формате и, что еще хуже, часто являются неполными, неоднозначными и не содержат всей необходимой информации. То же самое относится и к тестовым случаям, которые часто хранятся в виде списков текстовых тестовых шагов.
Преодоление этой проблемы структурированных данных требует инноваций и тщательного обдумывания. Техники, такие как извлечение информации, понимание естественного языка и машинное обучение, могут быть использованы для преобразования неструктурированных данных в структурированные данные. Этот процесс часто включает ручное вмешательство человека.
Альтернативным решением для обучения LLM является не пытаться обучать его на неструктурированных текстовых данных. Он стремится создавать структурированные требования с самого начала или преобразовывать неструктурированные данные в структурированные требования в качестве промежуточного этапа.
Вот где моделирование требований может усилить создание готовых к использованию ИИ требований для обучения языковых моделей. Мы можем использовать модели для структурирования и улучшения существующих данных, интегрируя существующие артефакты ЖЦПО с моделями в центральном хранилище знаний.
Что такое моделирование для требований программного обеспечения?
Модельное тестирование использует модель рассматриваемой функции для генерации тестовых случаев. Эти модели обычно представлены в виде визуальных блок-схем, которые четко определяют требования программного обеспечения, изображая поведение, функции или операции системы.
Используя такие модели, можно сократить неоднозначность, что облегчает понимание требований как разработчикам, так и тестировщикам. Более того, моделирование облегчает автоматическую генерацию тестовых случаев, данных и автоматизации. Любые изменения в требованиях программного обеспечения могут быть отражены путем изменения моделей, что приводит к динамическому и обновленному набору тестовых средств.
Блок-схемы предлагают визуальный метод представления сложных процессов в простой и понятной форме. Они показывают каждый шаг в виде блока или символа, а стрелки между ними показывают поток пользователей и данных через процесс. Это дает четкое, легко следуемое представление процесса, выделяя последовательность операций и точки принятия решений:
Обычно организация, использующая модельное тестирование, создает библиотеку повторно используемых моделей, которые затем можно соединять, чтобы создавать более сложные сценарии от начала до конца с большей скоростью. Процесс компонентизации позволяет команде работать намного быстрее в создании своих тестовых ресурсов, а также реагировать на изменения в упрощенном подходе:
Фло-диаграммы структурированы для LLM
Фло-диаграммы по своей природе являются структурированными. Когда речь идет о тренировке больших языковых моделей, структурированные данные в виде фло-диаграмм могут давать очень мощные результаты.
Более того, фло-диаграммы идеально подходят для запросов, потому что они интуитивны и просты в интерпретации. Поток контроля и процесс принятия решений ясно изображены, что упрощает модели предсказывать следующие шаги в процессе.
Возможность находить связи между различными шагами делает фло-диаграммы особенно ценными как для запросов, так и для тренировки LLM. Вот пример использования LLM для запроса простой модели. Модель ниже изображает процесс подачи заявки на студенческий счет:
Задание: Сколько лет должен быть студент, чтобы получить одобрение на студенческий счет?
Ответ: 18 лет и старше.
Задание: Как студент может получить одобрение на студенческий счет?
Ответ: Чтобы получить одобрение на студенческий счет, студент должен сначала ввести свои личные данные. После этого будет проверена его возраст, чтобы убедиться, что ему уже исполнилось 18 лет. Затем студент должен предоставить доказательство своего статуса студента. Если все эти критерии выполнены, и заявка прошла успешно, студент получит одобрение на студенческий счет.
Общение с требованиями программного обеспечения
Учитывая доказанную способность LLM запрашивать и рассуждать на основе фло-диаграмм (моделей) и разнообразных подключаемых модулей в инструментах DevOps, мы стремимся применить LLM к фло-диаграммам и артефактам DevOps. Мы стремимся объединить модели с данными из различных артефактов DevOps, создавая центральную базу знаний для LLM.
Мы применили и обучили LLM на массиве требований программного обеспечения (собранных из JIRA) и моделей, хранящихся в рабочем пространстве Test Modeller организации. Для этого проекта у нас есть проект JIRA с серией задач для банковского приложения, а также модели, созданные для текстовых проблем. Эти модели добавляют дополнительную структуру и завершают требования, создавая данные, необходимые для LLM:
Вот пример тикета:
Если вы сравните вышеуказанную “стену текста” сюжета пользователя с визуальными требованиями ниже, вы увидите, насколько легче понять логику подачи заявки на кредитную карту с использованием фло-диаграммы. Это происходит из-за внутренней структуры и визуальной природы фло-диаграммы.
Коллекция фло-диаграмм и тикетов Jira, синхронизированных в рабочем пространстве Test Modeller, обеспечивает базу знаний для LLM. При запросе LLM может использовать и рассуждать на основе информации, хранящейся в различных артефактах жизненного цикла разработки ПО, например, данных, хранящихся в нескольких тикетах Jira.
Давайте рассмотрим несколько примеров запросов к этой базе знаний с использованием LLM, обученной на примерах требований программного обеспечения и моделей банковского приложения.
Пример 1: Простой вопрос
Давайте начнем с простого вопроса, на который мы ожидаем получить хороший ответ. Дайте мне подробности о тикете JIRA по его идентификатору.
Задание: Что такое тикет JIRA CB-13?
Посмотрим, вернется ли краткое описание тикета:
Пример 2: Подразумеваемое рассуждение с моделью
В этом примере мы пойдем немного глубже и зададим вопрос, ожидая, что LLM поймет фло-диаграмму и выведет ответ на основе нее. Конкретно о процессе подачи заявки на кредитную карту.
Задание: Какой кредитный рейтинг необходим для подачи заявки на кредитную карту?
LLM захватил фло-диаграмму процесса подачи заявки на кредитную карту и интерпретировал модель. Затем он использовал эту интерпретацию для расчета необходимого кредитного рейтинга, равного 700 и выше.
Пример 3: Подразумеваемое рассуждение с моделями и требованиями
Это предложение требует от LLM прерывания нескольких источников информации для ответа на вопрос. Оно ищет модель и соответствующее требование.
Предложение: Когда клиент может подать заявку на кредитную карту?
Пример 4: Множественное рассуждение по требованиям
Для ответа на запрос, требующий понимания и рассуждения по нескольким требованиям, необходимо обратиться к трем историям пользователей. В ответе мы увидим, что для получения доступа к продуктам требуется хороший кредитный рейтинг.
Предложение: На какие продукты я могу подать заявку, если у меня хороший кредитный рейтинг?
Демонстрация: Использование LLM для запроса структурированных данных с помощью блок-схем
Смотрите, как я синхронизирую информацию из пользовательских историй Jira в центральный базе знаний и запускаю запросы, используемые при написании этой статьи:
Применение LLM для более эффективной доставки программного обеспечения
Curiosity Software использует большие языковые модели (LLMs), такие как GPT-4 от OpenAI, для лучшего понимания и управления требованиями к программному обеспечению и бизнес-логикой, особенно с акцентом на борьбу с техническим долгом.
Учитывая, что LLM процветает на структурированных данных, модельное тестирование является идеальным инструментом для завершения и устранения неоднозначности в неструктурированных данных. Модели предоставляют источник структурированных бизнес-потоков, используя визуальные блок-схемы для представления требований к программному обеспечению, что обеспечивает ясность. В то же время мы можем синхронизировать информацию из инструментов и артефактов DevOps в центральной базе знаний.
Такой подход также позволяет автоматически генерировать тестовые сценарии, данные и автоматизацию. Используя эти методы, Curiosity Software активно работает над обучением LLM на широком спектре требований к программному обеспечению, полученных из различных инструментов DevOps, которые моделируются в рабочей области Test Modeller организации. Это создает сопилота и панели управления, предоставляющие объяснения всего жизненного цикла разработки программного обеспечения при запросе, а также информацию для принятия решений относительно риска, выпусков, тестового покрытия, соответствия требованиям и т.д.:
Мы даже можем генерировать модели с помощью генеративного искусственного интеллекта, как описано в моей последней статье. Это закрывает цикл обратной связи. Человек может работать с генеративным ИИ для создания и пошагового улучшения моделей на основе данных в блок-схемах и других артефактах жизненного цикла разработки программного обеспечения. Потоки, в свою очередь, предоставляют точные спецификации для разработчиков, одновременно генерируя тесты для проверки создаваемого ими кода.
Результаты, полученные в результате использования ИИ для проектирования, тестирования и разработки программного обеспечения, подаются в нашу центральную базу знаний. Это обновляет LLM, информирует будущие итерации и позволяет избежать технического долга.
Применение ИИ к требованиям программного обеспечения может помочь улучшить эффективность и эффективность процессов разработки программного обеспечения, выступать в качестве базы знаний для бизнес-процессов организации и, наконец, бороться с техническим долгом.