Сегментируй все возможность запроса сегментации произвольных объектов
Сегментируй запросы для произвольных объектов
Обзор статьи — Сегментация всего
Сегодняшний обзор статьи будет визуальным! Мы рассмотрим статью “Сегментация всего” от исследовательской команды искусственного интеллекта Meta, которая привлекла внимание не только научного сообщества, но и всех видов практиков и приверженцев глубокого обучения.
Статья “Сегментация всего” представляет задачу сегментации с подсказкой, вводит модель “Сегментация всего” (SAM) и детализирует создание нового общедоступного набора данных из 11 миллионов изображений, содержащих более 1 миллиарда масок. SAM получил широкое распространение в сообществе и привел к созданию новых моделей основных архитектур, таких как Grounded-SAM, который сочетает в себе Grounding DINO с SAM.
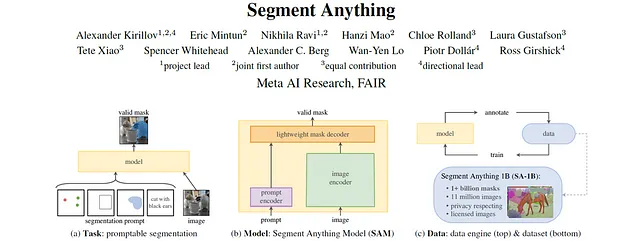
Статья: Сегментация всего
Код: https://github.com/facebookresearch/segment-anything
- Исследование структуры успешных подсказок
- Как машинное обучение может быть использовано для снижения счетов за энергию
- Линейная регрессия с нуля с использованием NumPy
Первая публикация: 5 апр. 2023
Авторы: Александр Кириллов, Эрик Минтун, Нихила Рави, Ханзи Мао, Клоу Ролланд, Лаура Густафсон, Тете Сяо, Спенсер Уайтхед, Александр К. Берг, Ван-Ен Ло, Пьотр Доллар, Росс Гиршик
Категория: сегментация, предсказание без примера, компьютерное зрение, подсказывание, масштабное
Структура
- Контекст и предыстория
- SAM — Модель “Сегментация всего”
- SA-1B — Набор данных с 1 миллиардом масок
- Эксперименты и абляции
- Заключение
- Дополнительные источники и ресурсы
Контекст и предыстория
Авторы статьи “Сегментация всего” ясно заявили: “[…] наша цель – построить модель основы для сегментации изображений”. Модели основы происходят из большого успеха обработки естественного языка (NLP). Модели обучаются в масштабах на основе самообучения. Эти модели обычно очень хорошо справляются с задачами предсказания без примера, то есть они могут решать задачи, отличные от тех, на которых они обучались, и делать это достаточно хорошо или даже лучше, чем их обученные конкуренты. В последние годы многие исследователи работали над тем, чтобы принести успех моделей основы NLP в другие области, такие как компьютерное зрение.
Модели, такие как CLIP и GLIP, сделали возможным условное классификацию изображений или задачу обнаружения объектов на основе текстовых подсказок, а не фиксированного набора классов. Другие модели, такие как BYOL или DINO, предложили различные техники для изучения семантически богатых представлений входных изображений, что является одним из ключевых требований для многих приложений компьютерного зрения.
Статья “Сегментация всего” стремится к следующему:
- Обеспечить сегментацию без примера с помощью подсказок
- Обучить модель большого масштаба (SAM) в качестве демонстрационного примера
- Собрать и опубликовать самый большой общедоступный набор данных для сегментации.
Но почему так важна работа модели без примера? — Ответ двойной. Во-первых, изначально модели компьютерного зрения обучались в надзорной манере, требующей не только данных, но и множества меток истинного значения. Сбор таких данных является крайне времязатратным и дорогостоящим. Во-вторых, классы, которые модель может предсказывать, ограничены фиксированным набором классов, использованных для обучения. Если вы хотите добавить новый класс в свою модель, вам нужно сначала собрать данные и переобучить модель.
Как можно задавать модели сегментации подсказку? — Вы, возможно, знакомы с подсказками текста из моделей, таких как ChatGPT, CLIP или GLIP. В то время как SAM в принципе также тестировалась с текстовыми подсказками, она в основном использует маски, точки, рамки или сетки точек, как показано на изображении ниже.

Рассмотрев контекст SAM, давайте теперь подробнее рассмотрим модель Segment Anything Model, также известную как SAM.
SAM — Сегментационная модель для всего
Модель Segment Anything Model (SAM) является многомодальной моделью, которая принимает на вход изображение и одну или несколько подсказок и выдает допустимую маску сегментации. Модель состоит из трех основных модулей: кодировщика изображения, кодировщика подсказок и декодера маски.
SAM может быть запущен с использованием маски, набора точек, ограничивающего прямоугольника или текста, или любой комбинации из них.
ПРИМЕЧАНИЕ: Несмотря на то, что в статье упоминается и экспериментируется с текстом в качестве подсказки, официальная реализация и демонстрация SAM до сих пор (на сентябрь 2023 года) не включают его.
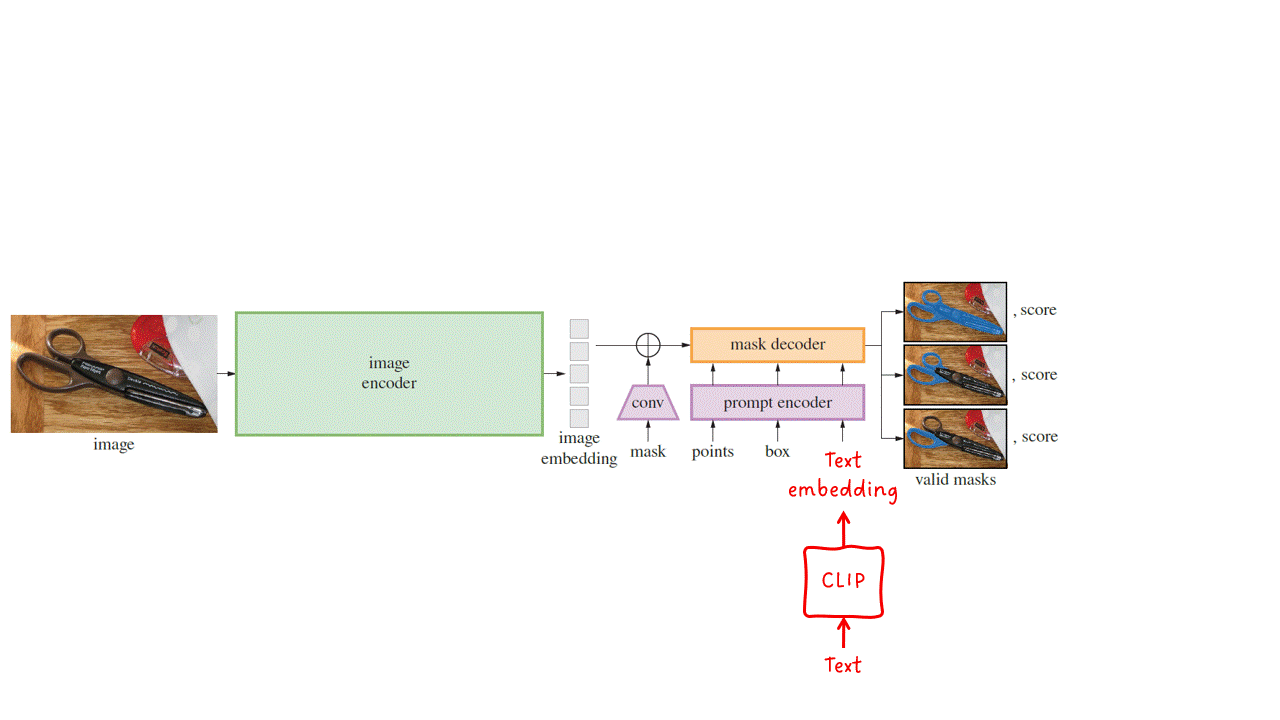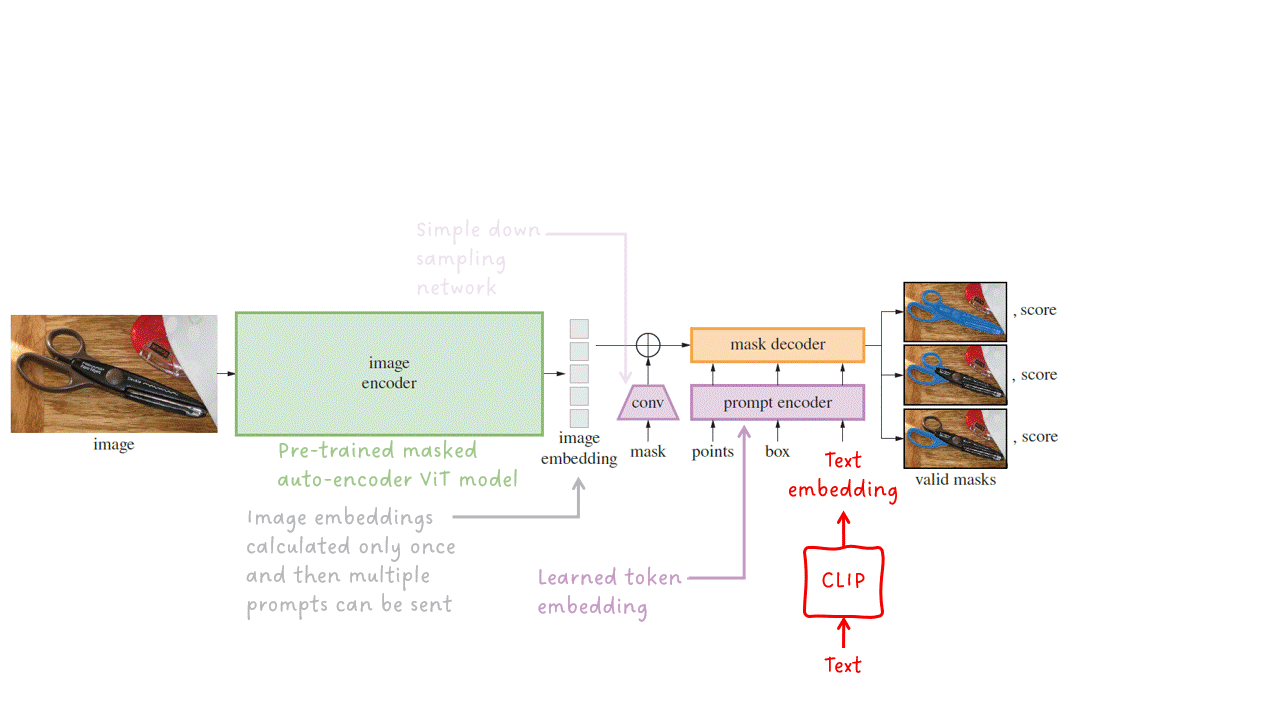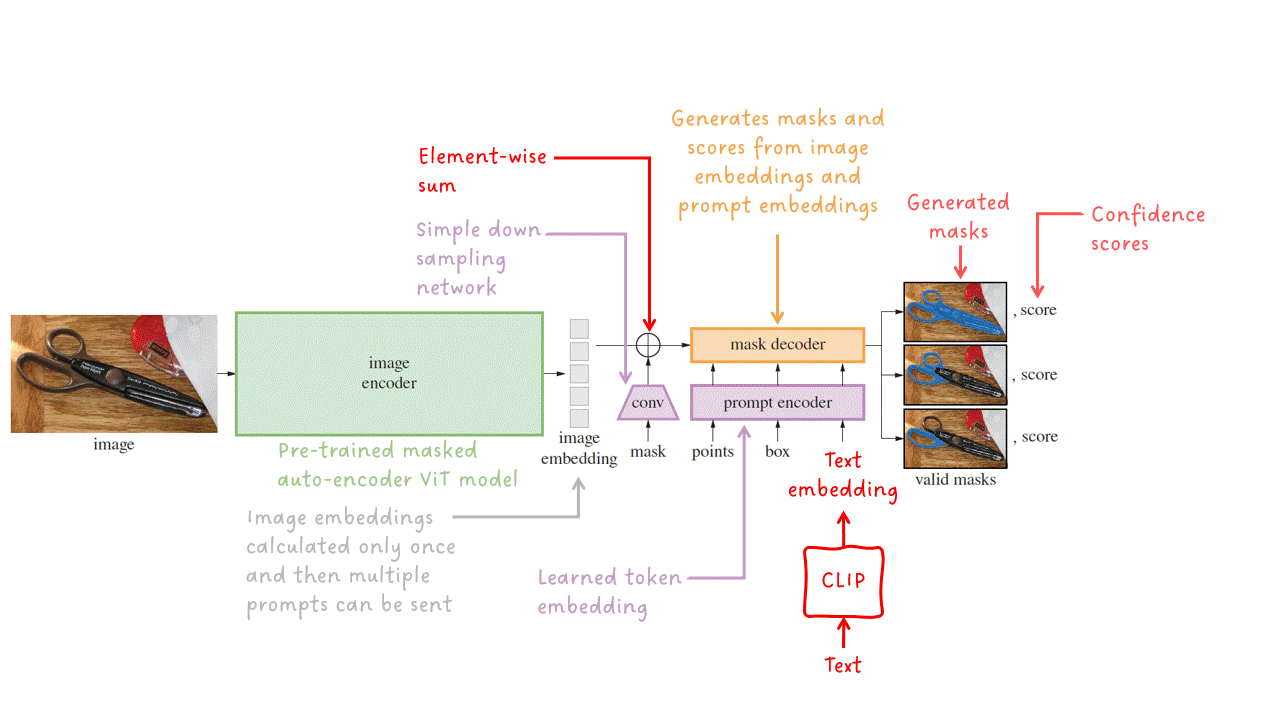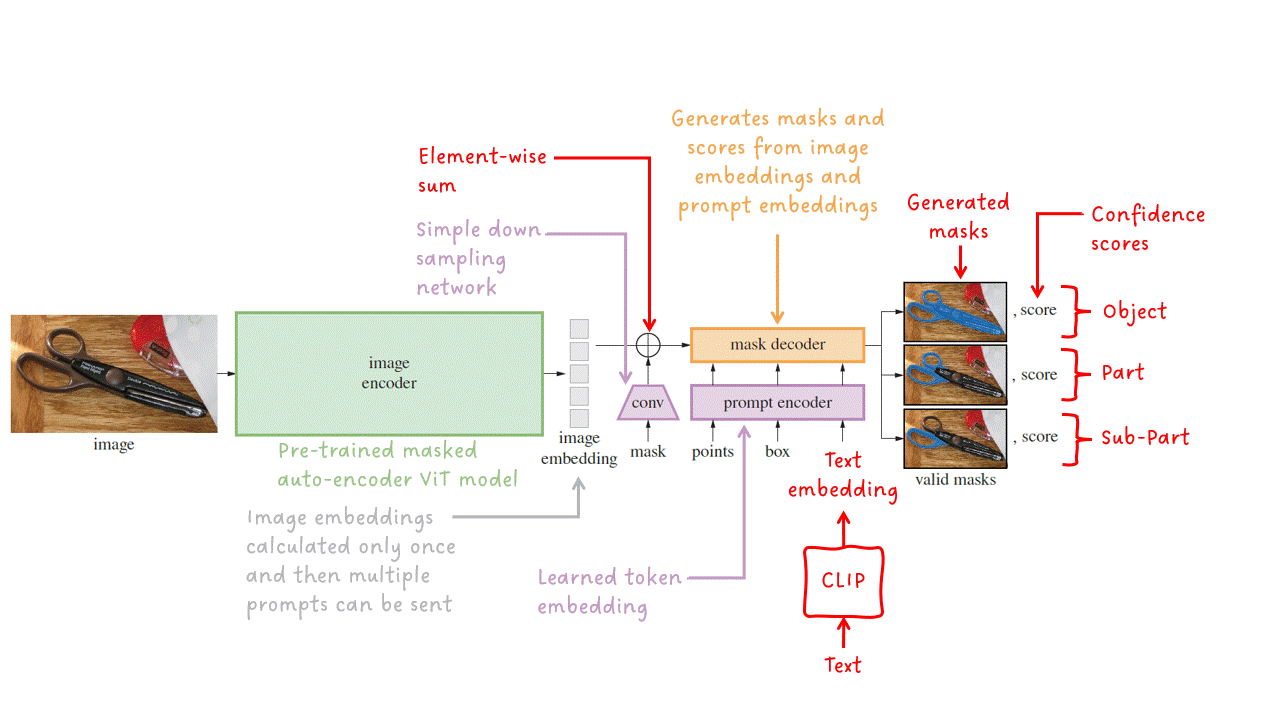
Кодировщик изображения — Выдает векторное представление изображения для заданного входного изображения. SAM использует и адаптирует предварительно обученный автоэнкодер ViT-H/16 с маскировкой. Это относительно большая модель с высокой производительностью.
Кодировщик подсказок — Разреженные подсказки (точки, прямоугольники и текст) преобразуются в векторные представления. Текстовые подсказки преобразуются в текстовые векторные представления с помощью CLIP, а затем подаются на вход кодировщику подсказок. Плотные подсказки (маски) просто уменьшаются с помощью сверточных слоев с шагом и далее добавляются к векторным представлениям изображения. Затем все векторные представления подаются на финальный этап: декодер маски.
Декодер маски — Принимает набор векторных представлений изображений (возможно, содержащих плотные векторные представления масок) и набор векторных представлений подсказок и выдает допустимую маску сегментации.
Существует две дополнительные детали, на которые мы должны обратить внимание: неоднозначность подсказок и производительность.
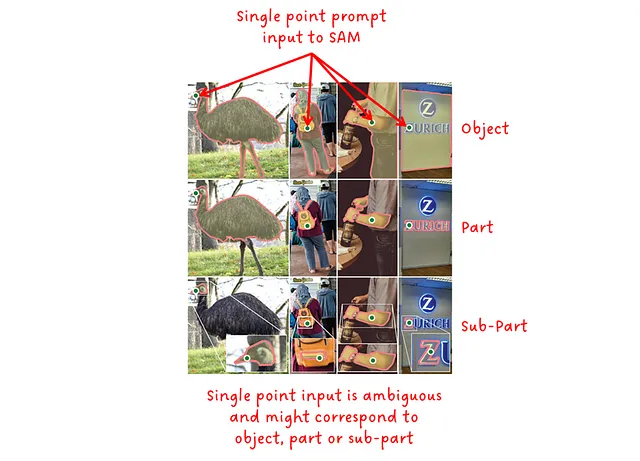
Вкратце, чем меньше контекста содержит подсказка, тем более неоднозначным она является и тем сложнее для модели предоставить правильный результат. Для текстовых подсказок мы наблюдали связь между специфичностью входного текста и производительностью модели в CLIP и GLIP. Точка в качестве входа может привести к различным возможным маскам. Поэтому SAM выдает набор из трех выходных масок, соответствующих объектному уровню, уровню части и уровню подчасти допустимой маски, как показано на изображении ниже.
Вторая деталь, о которой я хочу упомянуть, это производительность в терминах скорости вывода. Заметили ли вы, что кодировщик изображения является наиболее крупным подмодулем в SAM? Хорошо, это неправильный вопрос, потому что я до сих пор не рассказал вам, но SAM спроектирован таким образом, чтобы иметь семантически богатые векторные представления изображений (что часто требует большой модели), а затем действовать на эти представления, применяя легкий кодировщик подсказок и легкий декодер маски. Хорошо, что кодировщик изображений нужно запустить только один раз для каждого изображения, а затем модель может использовать одно и то же векторное представление изображения для множества подсказок. Это позволяет выполнять SAM в браузере, требуя всего ~50 мс для предсказания маски для заданной подсказки (после вычисления векторных представлений изображения).
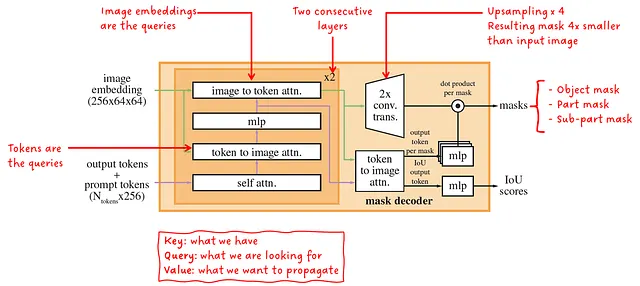
Давайте подробнее рассмотрим легкий декодер маски. Он принимает векторные представления изображений и векторные представления подсказок и выдает набор масок с соответствующими оценками. Внутри два последовательных блока декодера выполняют комбинацию самовнимания и перекрестного внимания, чтобы создать сильную зависимость между изображением и подсказками. Простая сеть повышения разрешения в сочетании с еще одним блоком перекрестного внимания генерирует маски и оценки.
SA-1B — Набор данных с 1 миллиардом масок
Второй большой вклад Segment Anything заключался в создании и выпуске масштабного набора данных для сегментации. Он содержит 11 миллионов высокого разрешения и лицензионных изображений с примерно 1.1 миллиардом масок. В то время как оригинальная версия набора данных имеет в среднем 3300×4950 пикселей, выпущенная версия уменьшена до 1500 пикселей на самом коротком краю. Он разнообразен в терминах различных сцен и количества масок на изображение, которое варьируется от менее чем 50 до более чем 500.

Набор данных был создан в трехэтапном движке данных, который объединяет ручные метки, аннотированные людьми, и автоматические метки, сгенерированные SAM.
Этап 1: Этап ассистированной ручной разметки — Команда профессиональных разметчиков помечала изображения с помощью ранней версии SAM, обученной на общих наборах данных для сегментации. Им было предложено пометить наиболее яркие объекты и они были поддержаны в продолжении работы после 30 секунд. По завершении этого этапа SAM был повторно обучен с новыми метками (всего 120 тысяч изображений с 4,3 миллиона масок).
Этап 2: Полуавтоматический этап — На этом этапе целью было увеличить разнообразие масок, сначала позволив SAM предсказывать некоторые маски, а затем просить разметчиков аннотировать отсутствующие менее яркие объекты. По завершении этого этапа SAM был повторно обучен, включив новые примеры (всего 300 тысяч изображений с 10,2 миллионами масок).
Этап 3: Полностью автоматический этап — На этом этапе разметка была полностью автоматической. SAM был предложен сеткой точек 32×32 для генерации масок и применения некоторой постобработки.
Анализ набора данных
Теперь давайте ближе рассмотрим некоторый анализ, касающийся набора данных SA-1B, представленного в статье.
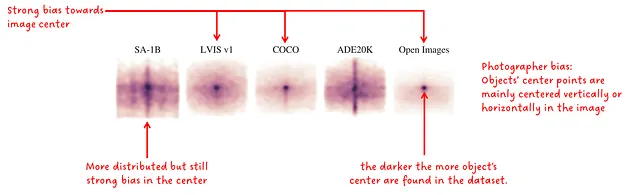
В первой оценке авторы создали нормализованное распределение центральной точки масок. Интересно, что эти распределения подвержены фотографическому предубеждению, то есть большинство фотографий центрируют объект интереса в центре и основной оси изображения.
Одним из основных преимуществ SA-1B является большое количество масок на изображение по сравнению с другими наборами данных (рис.7 слева). Это также означает, что SA-1B имеет много маленьких масок (рис.7 посередине). Сравнивая выпуклость масок, которая является мерой сложности, SA-1B очень похож на другие наборы данных, которые были размечены вручную (рис.7 справа).

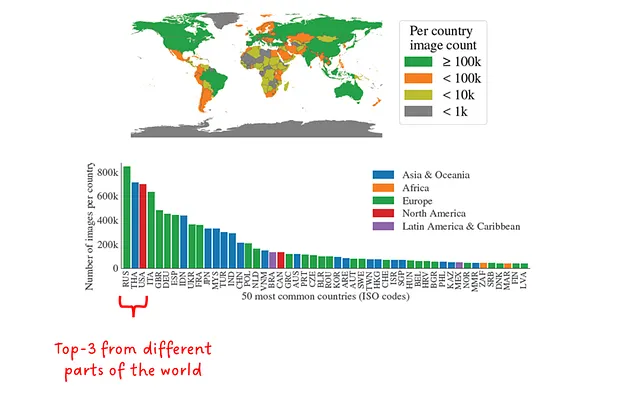
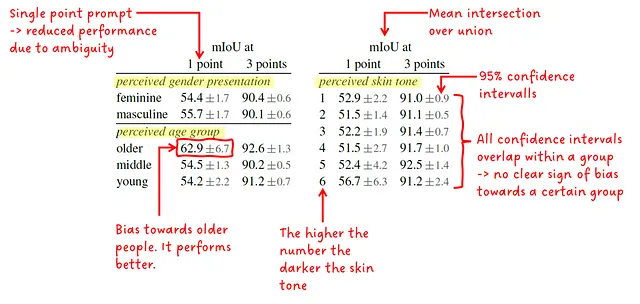
Особое внимание уделяется ответственному искусственному интеллекту (RAI), где анализируются и пытаются устранить предубеждения в отношении определенных групп людей. Как показывает рис.8, большинство стран мира имеют более 1000 изображений, и топ-3 страны представлены из разных частей света. Хотя низкодоходные страны все еще относительно слабо представлены (0,9% от общего количества образцов), в абсолютном масштабе это все равно более 9 миллионов масок и больше, чем в других наборах данных для сегментации.
Авторы дополнительно исследовали разницу в производительности между воспринимаемой презентацией пола, воспринимаемой возрастной группой и воспринимаемым оттенком кожи. Они предоставили среднее значение IoU (пересечение по объединению) между предсказанными масками и земной правдой масок и доверительный интервал 95%. SAM вызывается либо одной точкой, либо тремя точками. Основное сообщение заключается в том, что результаты очень похожи (и перекрываются доверительными интервалами) внутри группы, что показывает, что никому в группе не уделяется предпочтение. Единственное исключение – это пожилые люди в воспринимаемой возрастной группе.
Эксперименты и абляции
Segment Anything провел нам набор экспериментов, в основном сосредоточенных на его нулевой производительности, так как это была основная цель авторов: найти модель сегментации с возможностью подсказки с нулевым обучением. Также мы знаем из других моделей, таких как CLIP и GLIP, что настройка подсказки практически так же эффективна, как тонкая настройка модели в терминах производительности.
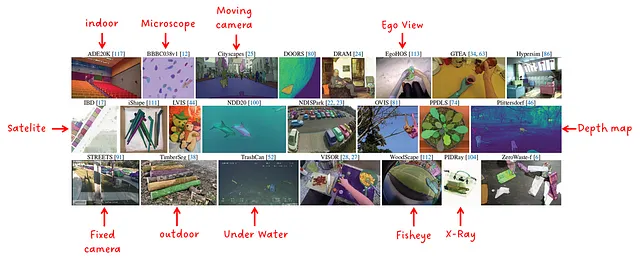
Для выполнения экспериментов был составлен набор из 23 различных наборов данных. Он содержит образцы из широкого спектра распределений данных, как показано на рис. 10.
Оценка нулевого выстрела одной точки
Напомним, что нулевой выстрел означает, что модель никогда не обучалась на данных, с которыми она сталкивается во время оценки. Также напомним, что подсказка одной точки является довольно сложной задачей из-за ее неоднозначности, как показано на рис. 3.
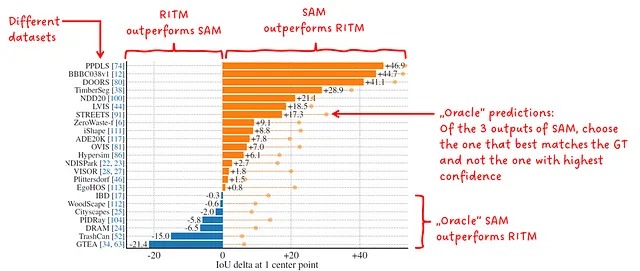
В этом первом эксперименте авторы сравнили SAM с RITM, сильным интерактивным сегментатором, который, по их словам, показал лучшие результаты на их бенчмарках.
Помните, что SAM выводит 3 разные маски с соответствующим баллом при подсказке одной точки. В этом эксперименте выбирается маска с самым высоким баллом для оценки. Поскольку иногда это неверно, авторы также оценивают лучшую маску, которая определяется путем сравнения предсказаний с земной правдой масок и выбора тех, которые имеют наивысшее перекрытие. Это “оракул” предсказания.
SAM превосходит RITM в 16 из 23 наборов данных в нулевом выстреле одной точки с действительной маской. При выполнении оракульных предсказаний он превосходит RITM во всех 23 наборах данных.
Нулевой выстрел: текст в маску
В этом эксперименте SAM был подсказан текстом. Авторы называют эту функцию концептом доказательства и, следовательно, не проводят обширных экспериментов и не выпускают эту функцию в своей официальной реализации кода.
Посмотрев на рис. 12, вы можете видеть, что SAM способен возвращать правильные маски даже для сложных объектов, таких как “решетка для зубов бобра”. В некоторых других случаях модель не справляется только с текстовыми подсказками, и они показывают, что, предоставив контекст в виде точки, SAM способен правильно предсказывать одиночные или несколько стеклоочистителей, показывая, что для предсказания учитывается не только точка, но и текст.

Zero-Shot Edge Detection
Интересно, SAM также может использоваться для обнаружения границ, задачи, которую он не рассматривал и к данным которой не имел доступа во время обучения.
Для предсказания карт SAM сначала предлагается сетка из 16×16 точек, что приводит к 768 предсказанным маскам (объект, часть и подчасть для каждой из 256 точек). Затем полученные маски фильтруются и подвергаются постобработке для получения масок границ.
Как показано на рис. 13, по сравнению с истинными данными, SAM предсказывает гораздо больше деталей. Но, чтобы быть справедливым, если истинные данные не полные или охватывают другой уровень абстракции, это сравнение кажется нечестным. Но всё же, результаты довольно хорошие!

Zero-Shot Instance Segmentation
В этом эксперименте SAM предлагается с ограничивающей рамкой, полученной от полностью обученной модели ViTDet-H на COCO и LVIS. Затем полученная маска снова подается в SAM вместе с исходной ограничивающей рамкой для уточнения результата. Сравнение между ViTDet и SAM показано на рис. 14.

Здесь стоит отметить две вещи: Если вы изучите COCO и LVIS, вы увидите, что маски не выровнены пиксельно с объектами. Это смещение присутствует в ViTDet, поэтому качество SAM кажется лучше. Насколько лучше – трудно сказать с помощью вычисленных метрик, так как истинные данные также имеют это смещение, и по сравнению с плохими исходными данными SAM покажет худший результат. Поэтому людей попросили визуально проверить их. Второе, почему у этого слона только 3 ноги 😅. Независимо от того, насколько я стараюсь, я не могу увидеть четвертую…
Абляции
В разделе абляций авторы в основном были заинтересованы в масштабировании набора данных, количества точек для предложения и размера кодировщика изображений (см. рис. 13). Результаты отображаются в среднем IoU.
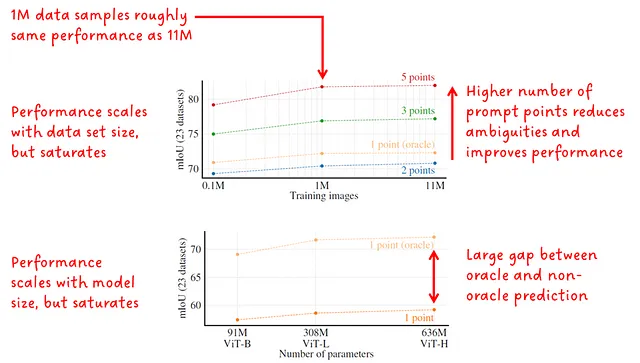
Интересно, даже если масштабирование данных и масштабирование размера модели влияют на результаты mIoU, они насыщаются. Это может указывать на то, что модель настолько хороша, что практически нет места для улучшений или, вероятно, это ограничение их подхода.
Заключение
Segment Anything представил модель Segment Anything Model (SAM), которую можно подстраивать с помощью запросов, а также крупномасштабный набор данных для сегментации, содержащий более 1 миллиарда масок в более чем 11 миллионах изображений. Возможность подстраивать модель сегментации приносит много гибкости, такую как адаптацию обученной модели к невидимым задачам или возможность обнаружения неизвестных классов. Хотя некоторые спорят, считается ли SAM фундаментальной моделью, поскольку она была обучена в надзорном режиме, она все же продемонстрировала замечательные результаты и была широко принята.
Дополнительные чтения и ресурсы
Как вы, вероятно, знаете, область глубокого обучения развивается с невероятной скоростью. Поэтому неудивительно, что сразу после выпуска SAM появилось много новых проектов, развивающих его успех, дальнейшее улучшение качества предсказаний, сокращение времени вывода или адаптация модели для применения на краю.
Вот список интересных ресурсов, развивающих идеи SAM:
- Grounded Segment Anything
- Segment Anything in High Quality
- Fast Segment Anything
- Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Здесь я делюсь некоторыми ссылками, если вы хотите получить практический опыт с SAM и SA-1B:
- Загрузка набора данных SA-1B
- Демонстрация Segment Anything
- Segment Anything на GitHub
- Python Notebook для экспериментов с SAM
Вот некоторые из моих статей, анализирующих некоторые связанные основные модели:
Основная модель CLIP
Анализ статьи — Обучение переносимых визуальных моделей с естественным языковым наблюдением
towardsdatascience.com
GLIP: Введение языково-образового предварительного обучения для обнаружения объектов
Анализ статьи — Основное языково-образовое предварительное обучение
towardsdatascience.com
BYOL – Альтернатива контрастному самообучению
Анализ статьи — Bootstrap Your Own Latent: Новый подход к самообучению
towardsdatascience.com