Эта научная работа по искусственному интеллекту от Университета Наньянг Технологического университета Сингапура (NTU Singapore) представляет MeVIS крупномасштабную платформу для сегментации видео с использованием движения
Эта научная работа представляет платформу MeVIS для сегментации видео с использованием движения.


Сегментация видео с учетом языка – это развивающаяся область, которая фокусируется на сегментации и отслеживании конкретных объектов в видео с использованием описаний на естественном языке. Текущие наборы данных для обращения к видеообъектам обычно подчеркивают значимые объекты и полагаются на языковые выражения с множеством статических атрибутов. Эти атрибуты позволяют идентифицировать целевой объект в одном кадре. Однако эти наборы данных игнорируют значимость движения в сегментации видеообъектов с учетом языка.

Исследователи представили MeVIS, новый масштабный набор данных под названием Motion Expression Video Segmentation (MeViS), чтобы помочь нашему исследованию. Набор данных MeViS включает 2 006 видео с 8 171 объектом, для которых предоставлены 28 570 выражений движения. Вышеописанные изображения отображают выражения в MeViS, которые в основном фокусируются на атрибутах движения, и целевой объект не может быть идентифицирован, рассматривая только один кадр. Например, первый пример показывает три попугая с похожими внешними данными, и целевой объект идентифицируется как “Птица, улетающая”. Этот объект может быть определен только захватом его движения на протяжении всего видео.
Несколько шагов обеспечивают акцентирование временных движений видео в наборе данных MeVIS.
- Как закодировать периодические временные признаки
- Язык для наград за синтез навыков робототехники
- Обучение языковых моделей алгоритмическому мышлению
Во-первых, тщательно выбирается видеоконтент, содержащий несколько объектов, существующих с движением, и исключаются видео с изолированными объектами, которые можно легко описать статическими атрибутами.
Во-вторых, приоритетными являются языковые выражения, не содержащие статических подсказок, таких как имена категорий или цвета объектов, в случаях, когда целевые объекты могут быть однозначно описаны только словами о движении.
Помимо предложения набора данных MeViS, исследователи также представляют базовый подход, названный Language-guided Motion Perception and Matching (LMPM), чтобы справиться с вызовами, представленными этим набором данных. Их подход включает генерацию языково-условных запросов для идентификации потенциальных целевых объектов в видео. Затем эти объекты представляются с помощью векторных представлений объектов, которые более устойчивы и вычислительно эффективны по сравнению с картами признаков объектов. Исследователи применяют Motion Perception к этим векторным представлениям объектов для захвата временного контекста и установления голистического понимания движения в видео. Это позволяет их модели уловить как мгновенные, так и продолжительные движения, присутствующие в видео.
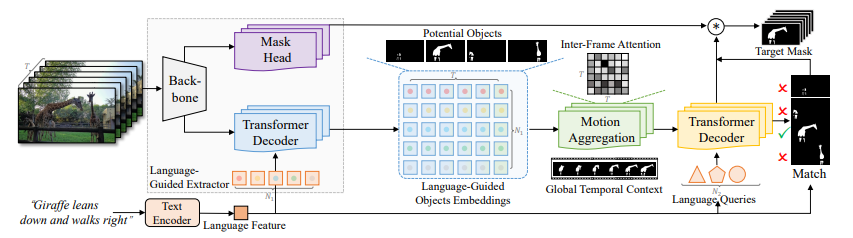
Вышеописанное изображение отображает архитектуру LMLP. Они используют декодер Transformer для интерпретации языка из объединенных векторных представлений объектов, подверженных движению. Это помогает предсказывать движение объектов. Затем они сравнивают языковые особенности с проекциями движений объектов, чтобы найти целевой объект(ы), упомянутый в выражениях. Этот инновационный метод объединяет понимание языка и оценку движения для эффективной обработки сложной задачи набора данных.
Это исследование положило основу для разработки более продвинутых алгоритмов сегментации видео с учетом языка. Оно открыло пути в более сложные направления, такие как:
- Исследование новых техник для лучшего понимания и моделирования движения визуальных и лингвистических модальностей.
- Создание более эффективных моделей, которые сокращают количество избыточно обнаруженных объектов.
- Проектирование эффективных методов кросс-модального слияния для использования дополнительной информации между языком и визуальными сигналами.
- Разработка продвинутых моделей, способных обрабатывать сложные сцены с различными объектами и выражениями.
Решение этих задач требует проведения исследований, чтобы продвинуть текущие достижения в области сегментации видео с помощью языка на новый уровень.





