Использование генеративных моделей для повышения полу-надзорного обучения
Генеративные модели в полу-надзорном обучении
Введение
В динамичном мире машинного обучения одной из постоянных проблем является использование полного потенциала ограниченного количества размеченных данных. Входит на сцену семисетевое обучение – гениальный подход, который сочетает небольшую партию размеченных данных с большим количеством неразмеченных данных. В этой статье мы рассмотрим революционную стратегию: использование генеративных моделей, в частности вариационных автокодировщиков (VAE) и генеративно-состязательных сетей (GAN). По окончании этого увлекательного путешествия вы поймете, как эти генеративные модели могут глубоко улучшить производительность алгоритмов семисетевого обучения, подобно виртуозному повороту в захватывающем повествовании.
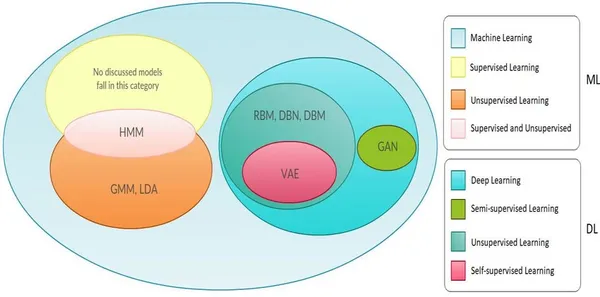
Цели обучения
- Мы начнем с погружения в семисетевое обучение, понимания его значения и увидим, как оно используется в реальных сценариях машинного обучения.
- Затем мы познакомим вас с увлекательным миром генеративных моделей, с фокусом на VAE и GAN. Узнаем, как они усиливают семисетевое обучение.
- Приготовьтесь приступить к практической части. Вы узнаете, как интегрировать эти генеративные модели в реальные проекты по машинному обучению, начиная с подготовки данных и заканчивая обучением моделей.
- Мы подчеркнем преимущества, такие как улучшение обобщения модели и экономия затрат. Кроме того, мы продемонстрируем, как этот подход применяется в различных областях.
- В каждом путешествии есть свои трудности, и мы их преодолеем. Мы также рассмотрим важные этические аспекты, чтобы вы имели все необходимые навыки для ответственного использования генеративных моделей в семисетевом обучении.
Эта статья была опубликована в рамках Data Science Blogathon.
Введение в семисетевое обучение
В огромном мире машинного обучения получение размеченных данных может быть сложной задачей. Это часто требует затрат времени и средств на разметку данных, что может ограничить масштабирование обучения с учителем. Входит на сцену семисетевое обучение, умный подход, который сокращает разрыв между размеченными и неразмеченными данными. Оно осознает, что, хотя размеченные данные очень важны, огромные объемы неразмеченных данных часто остаются неиспользуемыми, готовыми к использованию.
Представьте, что вам поручено обучить компьютеру распознавать различных животных на изображениях, но разметка каждого из них – геркулесов труд. Вот где на помощь приходит семисетевое обучение. Оно предлагает смешивать небольшую партию размеченных изображений с большим набором неразмеченных для обучения моделей машинного обучения. Такой подход позволяет модели использовать потенциал неразмеченных данных, улучшая ее производительность и адаптивность. Это как иметь в руках несколько направляющих звезд для навигации по галактике информации.
- Познакомьтесь с TinyLlama небольшой моделью искусственного интеллекта, которая стремится предварительно обучить модель ламы с 1,1 миллиарда параметров на 3 трлн. токенов.
- Alibaba представляет две открытые модели обработки больших объемов данных на основе зрительного языка (LVLM) Qwen-VL и Qwen-VL-Chat
- Переосмысление академической честности в эпоху искусственного интеллекта Сравнительный анализ ChatGPT и студентов университетов в 32 курсах
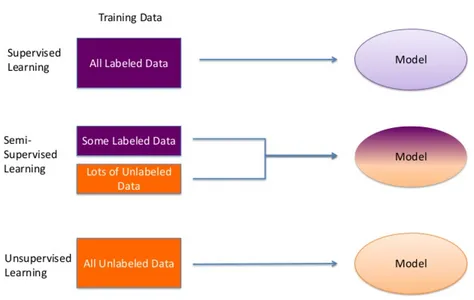
В нашем путешествии по семисетевому обучению мы изучим его важность, основные принципы и инновационные стратегии, с особым вниманием к тому, как генеративные модели, такие как VAE и GAN, могут усилить его возможности. Давайте откроем силу семисетевого обучения, рука об руку с генеративными моделями.
Генеративные модели: усиление семисетевого обучения
В увлекательном мире машинного обучения генеративные модели становятся настоящими игроками, придавая новую жизнь семисетевому обучению. Эти модели обладают уникальным талантом – они не только могут улавливать сложности данных, но и создавать новые данные, отражающие то, что они узнали. Среди лучших исполнителей в этой области можно выделить вариационные автокодировщики (VAE) и генеративно-состязательные сети (GAN). Давайте отправимся в путешествие, чтобы узнать, как эти генеративные модели становятся катализаторами, расширяя границы семисетевого обучения.
VAE отлично улавливают сущность распределений данных. Они делают это, отображая входные данные в скрытое пространство и затем тщательно их восстанавливая. Эта способность находит глубокое применение в семисетевом обучении, где VAE побуждают модели выделять значимые и лаконичные представления данных. Эти представления, выращенные без необходимости обилия размеченных данных, являются ключом к улучшенной обобщающей способности даже при ограниченном количестве размеченных примеров. На другой стороне сцены GAN вступают в увлекательный противоборствующий танец. Здесь генератор стремится создать данные, виртуально неотличимые от реальных данных, в то время как дискриминатор играет роль бдительного критика. Этот динамичный дуэт приводит к увеличению данных и открывает путь для создания совершенно новых значений данных. Именно благодаря этим увлекательным выступлениям VAE и GAN занимают центральное место, вводя новую эру семисетевого обучения.
Практические шаги реализации
Теперь, когда мы изучили теоретические аспекты, пришло время завернуть рукава и погрузиться в практическую реализацию полуобученного обучения с генеративными моделями. Именно здесь происходит волшебство, где мы превращаем идеи в реальные решения. Вот необходимые шаги, чтобы оживить эту синергию:

Шаг 1: Подготовка данных – подготовка сцены
Как и любая хорошо исполненная постановка, нам нужна хорошая и лучшая основа. Начните с сбора данных. У вас должен быть небольшой набор помеченных данных и значительный резервуар непомеченных данных. Обеспечьте чистоту, хорошую организацию и готовность ваших данных к сцене.
# Пример кода для загрузки и предварительной обработки данных
import pandas as pd
from sklearn.model_selection import train_test_split
# Загрузка помеченных данных
labeled_data = pd.read_csv('labeled_data.csv')
# Загрузка непомеченных данных
unlabeled_data = pd.read_csv('unlabeled_data.csv')
# Предварительная обработка данных (например, нормализация, обработка пропущенных значений)
labeled_data = preprocess_data(labeled_data)
unlabeled_data = preprocess_data(unlabeled_data)
# Разделение помеченных данных на обучающий и валидационный наборы
train_data, validation_data = train_test_split(labeled_data, test_size=0.2, random_state=42)
#import csvШаг 2: Интеграция генеративных моделей – Спецэффекты
Генеративные модели, наши звезды шоу, занимают центральную сцену. Интегрируйте вариационные автоэнкодеры (VAE) или генеративные противоборствующие сети (GAN) в вашу полуобученную обучающуюся конвейер. Вы можете выбрать обучение генеративной модели на неразмеченных данных или использовать ее для увеличения объема данных. Эти модели добавляют спецэффекты, которые делают ваше полуобученное обучение сияющим.
# Пример кода для интеграции VAE для увеличения объема данных
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Lambda
from tensorflow.keras import Model
# Определение архитектуры VAE (энкодер и декодер)
# ... (Определение слоев энкодера)
# ... (Определение слоев декодера)
# Создание модели VAE
vae = Model(inputs=input_layer, outputs=decoded)
# Компиляция модели VAE
vae.compile(optimizer='adam', loss='mse')
# Предварительное обучение VAE на неразмеченных данных
vae.fit(unlabeled_data, unlabeled_data, epochs=10, batch_size=64)
#import csvШаг 3: Полуобученное обучение – Репетиция ансамбля
Теперь пришло время обучить вашу модель полуобученного обучения. Комбинируйте помеченные данные с увеличенными данными, созданными генеративными моделями. Этот ансамбль данных даст вашей модели возможность извлечь важные характеристики и эффективно обобщить, так же как опытный актер выполняет свою роль идеально.
# Пример кода для полуобученного обучения с использованием TensorFlow/Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Создание модели полуобученного обучения (например, нейронная сеть)
model = Sequential()
# Добавление слоев (например, входной слой, скрытые слои, выходной слой)
model.add(Dense(128, activation='relu', input_dim=input_dim))
model.add(Dense(64, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Компиляция модели
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Обучение модели с помощью помеченных и увеличенных данных
model.fit(
x=train_data[['feature1', 'feature2']], # Используйте соответствующие характеристики
y=train_data['label'], # Метки помеченных данных
epochs=50, # Подстройте при необходимости
batch_size=32,
validation_data=(validation_data[['feature1', 'feature2']], validation_data['label'])
)Шаг 4: Оценка и настройка – Генеральная репетиция
После обучения модели пришло время для генеральной репетиции. Оцените ее производительность с помощью отдельного набора данных для валидации. Настройте модель на основе результатов. Повторяйте и улучшайте, пока не достигнете оптимальных результатов, как режиссер настраивает выступление до безупречности.
# Пример кода для оценки модели и ее настройки
from sklearn.metrics import accuracy_score
# Предсказание на валидационном наборе данных
y_pred = model.predict(validation_data[['feature1', 'feature2']])
# Вычисление точности
accuracy = accuracy_score(validation_data['label'], y_pred.argmax(axis=1))
# Тонкая настройка гиперпараметров или архитектуры модели на основе результатов валидации
# Повторять до достижения оптимальной производительностиВ этих практических шагах мы превращаем концепции в действия, включая фрагменты кода, чтобы помочь вам. Здесь сценарий оживает, и ваша модель полу-надзорного обучения, работающая на основе генеративных моделей, занимает свое место на сцене. Давайте двигаться вперед и увидеть эту реализацию в действии.
Выгоды и применение в реальном мире
Когда мы сочетаем генеративные модели с полу-надзорным обучением, результаты меняют все. Вот почему это важно:
1. Повышенная обобщаемость: Используя неразмеченные данные, модели, обученные таким образом, показывают выдающиеся результаты на ограниченном количестве размеченных примеров, подобно талантливому актеру, который сияет на сцене даже с минимальной репетицией.
2. Увеличение данных: Генеративные модели, такие как VAE и GAN, предоставляют богатый источник разнообразных данных. Это повышает устойчивость модели и предотвращает переобучение, подобно уникальному декорационному отделу, создающему бесконечные вариации сцен.
3. Снижение затрат на разметку: Разметка данных может быть дорогостоящей. Интеграция генеративных моделей снижает необходимость в обширной разметке данных, оптимизируя ваш бюджет на производство.
4. Адаптация к доменам: Этот подход отлично адаптируется к новым, неизвестным доменам с минимальным количеством размеченных данных, подобно актеру, безупречно переходящему между разными ролями.
5. Применение в реальном мире: Возможности огромны. В обработке естественного языка это повышает анализ настроений, перевод языка и генерацию текста. В компьютерном зрении это повышает классификацию изображений, обнаружение объектов и распознавание лиц. Это ценный инструмент в здравоохранении для диагностики заболеваний, в финансах для обнаружения мошенничества и в автономном вождении для улучшения восприятия.
Это не просто теория – это практический инструмент, который меняет все в разных отраслях, обещая захватывающие результаты и производительность, подобно хорошо исполненному фильму, оставляющему неизгладимое впечатление.
Трудности и этические соображения
В нашем путешествии по захватывающему миру полу-надзорного обучения с генеративными моделями необходимо пролить свет на трудности и этические соображения, сопровождающие этот инновационный подход.
- Качество и распределение данных: Одна из основных трудностей заключается в обеспечении качества и представительности данных, используемых для обучения генеративных моделей и последующего полу-надзорного обучения. Смещенные или зашумленные данные могут привести к искаженным результатам, подобно недостоверному сценарию, влияющему на всю постановку.
- Сложность обучения модели: Интеграция генеративных моделей может привнести сложность в процесс обучения. Требуется не только экспертиза в традиционном машинном обучении, но и в тонкостях генеративного моделирования.
- Конфиденциальность и безопасность данных: Поскольку мы работаем с большими объемами данных, обеспечение конфиденциальности и безопасности данных становится важным. Обработка чувствительной или личной информации требует строгих протоколов, подобно защите конфиденциальных сценариев в индустрии развлечений.
- Предвзятость и справедливость: Использование генеративных моделей должно выполняться с бдительностью, чтобы предотвратить усиление предвзятости в сгенерированных данных или влияние на решения модели.
- Соблюдение регулирования: В различных отраслях, таких как здравоохранение и финансы, существуют строгие регулирования, регулирующие использование данных. Соблюдение этих регулирований является обязательным, подобно соблюдению стандартов в индустрии развлечений.
- Этический ИИ: Существует общая этическая задача влияния ИИ и машинного обучения на общество. Обеспечение доступности и равноправия выгод от этих технологий подобно продвижению разнообразия и включения в мире развлечений.
При решении этих трудностей и этических соображений необходимо подходить к интеграции генеративных моделей в полу-надзорное обучение с добросовестностью и ответственностью. Подобно созданию задумчивого и социально осознанного произведения искусства, этот подход должен стремиться обогатить общество, минимизируя вред.

Экспериментальные результаты и исследования
Теперь давайте погрузимся в суть вопроса: экспериментальные результаты, которые демонстрируют осязаемый вклад объединения генеративных моделей с полу-надзорным обучением
- Улучшенная классификация изображений: В области компьютерного зрения исследователи провели эксперименты, используя генеративные модели для расширения ограниченных помеченных наборов данных для классификации изображений. Результаты были впечатляющими; модели, обученные с использованием этого подхода, показали значительно более высокую точность по сравнению с традиционными методами обучения с учителем.
- Перевод языка с ограниченными данными: В области обработки естественного языка, кейс-стади показали эффективность полу-надзорного обучения с генеративными моделями для перевода языка. С использованием только минимального количества помеченных данных для перевода и большого количества одноязычных данных, модели смогли достичь впечатляющей точности перевода.
- Медицинская диагностика: Обратим внимание на здравоохранение, эксперименты показали потенциал этого подхода в медицинской диагностике. С помощью недостатка помеченных медицинских изображений, полу-надзорное обучение, усиленное генеративными моделями, позволило достичь точной детекции заболеваний.
- Выявление мошенничества в финансах: В финансовой отрасли кейс-стади продемонстрировали мощь генеративных моделей в полу-надзорном обучении для обнаружения мошенничества. Путем расширения помеченных данных примерами модели достигли высокой точности в идентификации мошеннических транзакций.
Полу-надзорное обучение показывает, как это сотрудничество может привести к замечательным результатам в различных областях, подобно сотрудничеству профессионалов в разных областях, которые сотрудничают, чтобы создать нечто великое.
Заключение
В этом исследовании взаимосвязи генеративных моделей и полу-надзорного обучения мы обнаружили новаторский подход, который обещает революционизировать машинное обучение. Эта мощная синергия позволяет преодолеть постоянную проблему нехватки данных и позволяет моделям процветать в областях, где помеченных данных мало. По мере нашего заключения, становится очевидно, что эта интеграция представляет собой сдвиг в парадигме, открывающий новые возможности и переопределяющий область искусственного интеллекта.
Основные выводы
1. Эффективность через слияние: Полу-надзорное обучение с генеративными моделями сокращает разрыв между помеченными и непомеченными данными, предоставляя более эффективный и экономически выгодный путь к машинному обучению.
2. Звезды генеративных моделей: Вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN) играют ключевую роль в расширении процесса обучения, подобно талантливым партнерам, поднимающим представление.
3. Практическая реализация плана: Реализация включает тщательную подготовку данных, бесшовную интеграцию генеративных моделей, тщательное обучение, итеративное совершенствование и бдительное соблюдение этических принципов, отражая тщательное планирование крупного производства.
4. Универсальное влияние в реальном мире: Преимущества распространяются на различные области, от здравоохранения до финансов. Демонстрируя приспособляемость и применимость этого подхода в реальном мире, подобно другому и уникальному сценарию, который резонирует с различной аудиторией.
5. Этическая ответственность: Как и любой инструмент, этические соображения стоят на первом месте. Обеспечение справедливости, конфиденциальности и ответственного использования ИИ является важным, подобно поддержанию этических стандартов в индустрии искусства и развлечений.
Часто задаваемые вопросы
Использование показанных в статье материалов не принадлежит Analytics Vidhya и осуществляется по усмотрению автора.





