Обучение глубокого обучения на AWS Inferentia' can be condensed to
'Обучение на AWS Inferentia'.
Еще один способ экономии средств при обучении модели искусственного интеллекта
Фото Lisheng Chang на Unsplash
Тема этого поста – доморощенный чип искусственного интеллекта от AWS, AWS Inferentia – более конкретно, второе поколение AWS Inferentia2. Это продолжение нашего поста про AWS Trainium в прошлом году и входит в серию постов на тему специализированных ускорителей искусственного интеллекта. В отличие от чипов, которые мы рассмотрели в предыдущих постах серии, AWS Inferentia был разработан для вычисления моделей искусственного интеллекта и предназначен специально для применения в задачах глубокого обучения. Однако факт того, что AWS Inferentia2 и AWS Trainium используют одну и ту же архитектуру NeuronCore-v2 и одинаковый программный стек (AWS Neuron SDK), возникает вопрос: Можно ли использовать AWS Inferentia для обучения моделей искусственного интеллекта?
Естественно, есть некоторые аспекты спецификаций семейства экземпляров Amazon EC2 Inf2 (оснащенных ускорителями AWS Inferentia), которые могут быть менее подходящими для некоторых обучающих нагрузок по сравнению с семейством экземпляров Amazon EC2 Trn1. Например, хотя и Inf2, и Trn1 поддерживают устройства NeuronLink-v2 с высокой пропускной способностью и низкой задержкой, устройства Trainium соединены в топологии 2D-тор, а не в кольцевой топологии, что может сказаться на производительности операторов коллективного взаимодействия (см. здесь для получения дополнительной информации). Однако некоторые обучающие нагрузки могут не требовать уникальных возможностей архитектуры Trn1 и могут работать одинаково хорошо на архитектурах Inf1 и Inf2.
Фактически, возможность обучения на ускорителях Trainium и Inferentia значительно расширила бы разнообразие обучающих экземпляров, доступных нам, и нашу возможность настраивать выбор обучающего экземпляра в соответствии с конкретными потребностями каждого проекта по глубокому обучению. В нашем недавнем посте “Выбор экземпляра для глубокого обучения” мы подробно описали ценность наличия широкого разнообразия различных типов экземпляров для обучения глубоких нейронных сетей. В то время как семейство Trn1 включает всего два типа экземпляров, обучение на Inf2 добавило бы еще четыре дополнительных типа экземпляров. Включение Inf1 в комплект добавило бы еще четыре.
Цель этого поста – продемонстрировать потенциал обучения на ускорителях AWS Inferentia. Мы определим игрушечную модель зрения и сравним производительность ее обучения на семействах экземпляров Amazon EC2 Trn1 и Amazon EC2 Inf2. Большое спасибо Охаду Кляйну и Ицхаку Леви за их вклад в этот пост.
Обратите внимание, что на момент написания этого текста некоторые архитектуры моделей глубокого обучения не поддерживаются Neuron SDK. Например, поддерживается вычисление моделей сверточных нейронных сетей (CNN), но обучение моделей CNN все еще не поддерживается. Документация SDK содержит матрицу поддерживаемых моделей, в которой указаны поддерживаемые функции для каждой архитектуры модели, фреймворка обучения (например, TensorFlow и PyTorch) и версии архитектуры Neuron.
Описанные в нашем описании эксперименты были выполнены на Amazon EC2 с использованием самой последней версии Deep Learning AMI для Neuron на момент написания этого текста, “Deep Learning AMI Neuron PyTorch 1.13 (Ubuntu 20.04) 20230720”, которая включает версию 2.8 Neuron SDK. Поскольку разработка Neuron SDK продолжается, вероятно, что сравнительные результаты, которые мы получили, с течением времени могут измениться. Настоятельно рекомендуется переоценить результаты этого поста с использованием самых актуальных версий основных библиотек.
Цель этого поста – продемонстрировать возможность обучения на экземплярах, оснащенных ускорителями AWS Inferentia. Пожалуйста, не считайте этот пост рекомендацией к использованию этих экземпляров или любых других продуктов, о которых мы можем упоминать. Много факторов влияет на выбор среды обучения, и этот выбор может сильно варьироваться в зависимости от особенностей вашего проекта. В частности, разные модели могут показывать совершенно разные относительные результаты по соотношению цена-производительность при работе на двух разных типах экземпляров.
Игрушечная модель
Подобно экспериментам, описанным в нашем предыдущем посте, мы определили простую модель классификации на основе Vision Transformer (ViT) (с использованием пакета timm версии 0.9.5 для Python) вместе с случайно сгенерированным набором данных.
from torch.utils.data import Datasetimport time, osimport torchimport torch_xla.core.xla_model as xmimport torch_xla.distributed.parallel_loader as plfrom timm.models.vision_transformer import VisionTransformer
# использование случайных данныхclass FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, labeldef train(batch_size=16, num_workers=4): # Инициализация группы процессов XLA для torchrun import torch_xla.distributed.xla_backend torch.distributed.init_process_group('xla') # мультипроцессорность: убедитесь, что каждый рабочий процесс имеет одинаковые начальные веса torch.manual_seed(0) dataset = FakeDataset() model = VisionTransformer() # загрузка модели на устройство XLA device = xm.xla_device() model = model.to(device) optimizer = torch.optim.Adam(model.parameters()) data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, num_workers=num_workers) data_loader = pl.MpDeviceLoader(data_loader, device) loss_function = torch.nn.CrossEntropyLoss() summ, tsumm = 0, 0 count = 0 for step, (inputs, target) in enumerate(data_loader, start=1): t0 = time.perf_counter() inputs = inputs.to(device) targets = torch.squeeze(target.to(device), -1) optimizer.zero_grad() outputs = model(inputs) loss = loss_function(outputs, targets) loss.backward() xm.optimizer_step(optimizer) batch_time = time.perf_counter() - t0 if idx > 10: # пропустить первые шаги summ += batch_time count += 1 t0 = time.perf_counter() if idx > 500: break print(f'среднее время шага: {summ/count}')if __name__ == '__main__': os.environ['XLA_USE_BF16'] = '1' # установите количество
Результаты
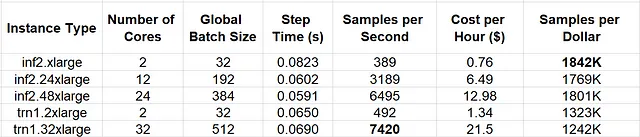
В таблице ниже мы сравниваем скорость и ценовую эффективность различных типов экземпляров Amazon EC2 Trn1 и Amazon EC2 Inf2.
Сравнение производительности модели классификации на основе ViT (Автор)
Хотя очевидно, что экземпляры, оснащенные Trainium, обладают лучшей абсолютной производительностью (то есть увеличенной скоростью обучения), обучение на экземплярах с инферентией привело к улучшению производительности по цене на ~39% (для экземпляров с двумя ядрами) и выше (для экземпляров большего размера).
Мы еще раз предупреждаем от принятия любых проектных решений, основанных исключительно на этих результатах. Некоторые архитектуры моделей могут успешно работать на экземплярах Trn1, но не работать на Inf2. Другие могут успешно работать на обоих экземплярах, но показывать совершенно отличные результаты сравнительной производительности, чем показанные здесь.
Обратите внимание, что мы опустили время, необходимое для компиляции модели глубокого обучения. Хотя это требуется только при первом запуске модели, время компиляции может быть довольно высоким (например, более десяти минут для нашей игрушечной модели). Два способа снизить накладные расходы на компиляцию модели - параллельная компиляция и автономная компиляция. Важно также убедиться, что ваш сценарий не содержит операций (или изменений графа), которые вызывают частые перекомпиляции. Дополнительные сведения см. в документации по Neuron SDK.
Итог
Хотя AWS Inferentia позиционируется как чип для вычисления искусственного интеллекта, оказывается, что он предлагает еще одну опцию для обучения моделей глубокого обучения. В нашей предыдущей публикации о AWS Trainium мы подчеркнули некоторые проблемы, с которыми вы можете столкнуться при адаптации ваших моделей для обучения на новом AI ASIC. Возможность обучения тех же моделей на экземплярах с инферентией также может увеличить потенциальную отдачу от ваших усилий.