Создайте своего собственного PandasAI с LlamaIndex
Создайте своего PandasAI с LlamaIndex

Введение
Pandas AI – это библиотека на языке Python, которая использует возможности генеративного искусственного интеллекта для усиления функциональности Pandas, популярной библиотеки для анализа данных. С помощью простой команды Pandas AI позволяет выполнять сложную очистку, анализ и визуализацию данных, ранее требовавшие много строк кода.
- США вводит ограничения на экспорт чипов NVIDIA в определенные страны Ближнего Востока
- Управление по авторскому праву США открыто для общественного мнения о искусственном интеллекте и авторском праве
- Эволюция в вашем коде понимание и написание генетического алгоритма с нуля – часть 1
Помимо математических вычислений, Pandas AI понимает естественный язык. Вы можете задавать вопросы о ваших данных на простом английском языке, и он будет предоставлять сводки и выводы на естественном языке, освобождая вас от необходимости разбираться в сложных графиках и таблицах.
В приведенном ниже примере мы предоставили фрейм данных Pandas и попросили генеративный искусственный интеллект создать столбчатую диаграмму. Результат впечатляет.
pandas_ai.run(df, prompt='Построить столбчатую диаграмму типа медиа для каждого года релиза с использованием разных цветов.')
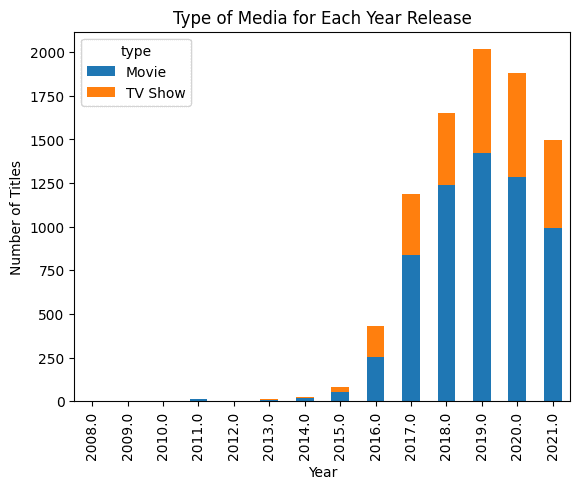
Примечание: пример кода взят из руководства Pandas AI: Руководство по анализу данных с использованием генеративного искусственного интеллекта.
В этой статье мы будем использовать LlamaIndex для создания подобных инструментов, которые могут понимать фрейм данных Pandas и производить сложные результаты, как показано выше.
LlamaIndex позволяет осуществлять естественный языковой запрос данных с помощью чата и агентов. Он позволяет масштабировать интерпретацию частных данных с использованием больших языковых моделей без повторного обучения на новых данных. LlamaIndex интегрирует большие языковые модели с различными источниками данных и инструментами. LlamaIndex – это фреймворк данных, который позволяет легко создавать приложения Chat с PDF с помощью всего нескольких строк кода.
Настройка
Вы можете установить библиотеку Python, используя команду pip.
pip install llama-index
По умолчанию LlamaIndex использует модель OpenAI gpt-3.5-turbo для генерации текста и text-embedding-ada-002 для поиска и представления данных. Чтобы запустить код без проблем, мы должны настроить переменную среды OPENAI_API_KEY. Мы можем зарегистрироваться и получить бесплатный API-ключ на странице нового токена API.
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxx"
Также поддерживаются интеграции с Anthropic, Hugging Face, PaLM и другими моделями. Вы можете узнать все об этом, прочитав документацию модуля.
Pandas Query Engine
Давайте перейдем к основной теме – созданию вашего собственного PandasAI. После установки библиотеки и настройки API-ключа мы создадим простой фрейм данных о городах с названием города и населением в качестве столбцов.
import pandas as pd
from llama_index.query_engine.pandas_query_engine import PandasQueryEngine
df = pd.DataFrame(
{"city": ["Нью-Йорк", "Исламабад", "Мумбаи"], "population": [8804190, 1009832, 12478447]}
)
С помощью PandasQueryEngine мы создадим запрос к фрейму данных для загрузки и индексации.
Затем мы напишем запрос и отобразим ответ.
query_engine = PandasQueryEngine(df=df)
response = query_engine.query(
"Какой город имеет наименьшее население?",
)
Как видим, он разработал Python-код для отображения города с наименьшим населением во фрейме данных.
> Инструкции Pandas:
```
eval("df.loc[df['population'].idxmin()]['city']")
```
eval("df.loc[df['population'].idxmin()]['city']")
> Вывод Pandas: Исламабад
Если вы выведете ответ, вы получите “Исламабад”. Это просто, но впечатляюще. Вам не нужно придумывать свою собственную логику или экспериментировать с кодом. Просто введите вопрос, и вы получите ответ.
print(response)
Исламабад
Вы также можете вывести код, лежащий в основе результата, используя метаданные ответа.
print(response.metadata["pandas_instruction_str"])
eval("df.loc[df['population'].idxmin()]['city']")
Анализ глобальной статистики YouTube
Во втором примере мы загрузим набор данных Global YouTube Statistics 2023 с Kaggle и выполним некоторый фундаментальный анализ. Это шаг вперед по сравнению с простыми примерами.
Мы будем использовать read_csv для загрузки набора данных в запросный движок. Затем мы напишем запрос, чтобы отобразить только столбцы с отсутствующими значениями и количество отсутствующих значений.
df_yt = pd.read_csv("Global YouTube Statistics.csv")
query_engine = PandasQueryEngine(df=df_yt, verbose=True)
response = query_engine.query(
"Показать столбцы с отсутствующими значениями и количество отсутствующих значений. Показать только столбцы с отсутствующими значениями.",
)
> Инструкции Pandas:
```
df.isnull().sum()[df.isnull().sum() > 0]
```
df.isnull().sum()[df.isnull().sum() > 0]
> Вывод Pandas: category 46
Country 122
Abbreviation 122
channel_type 30
video_views_rank 1
country_rank 116
channel_type_rank 33
video_views_for_the_last_30_days 56
subscribers_for_last_30_days 337
created_year 5
created_month 5
created_date 5
Gross tertiary education enrollment (%) 123
Population 123
Unemployment rate 123
Urban_population 123
Latitude 123
Longitude 123
dtype: int64
Теперь мы зададим прямые вопросы о популярных типах каналов. По моему мнению, движок запросов LlamdaIndex является очень точным и еще не породил галлюцинации.
response = query_engine.query(
"Какой тип канала имеет наибольшее количество просмотров.",
)
> Инструкции Pandas:
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
> Вывод Pandas: Entertainment
Entertainment
В конце мы попросим его визуализировать столбчатую диаграмму, и результаты будут потрясающими.
response = query_engine.query(
"Визуализировать столбчатую диаграмму десяти самых популярных каналов YouTube на основе подписчиков и добавить заголовок.",
)
> Инструкции Pandas:
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
> Вывод Pandas: AxesSubplot(0.125,0.11;0.775x0.77)
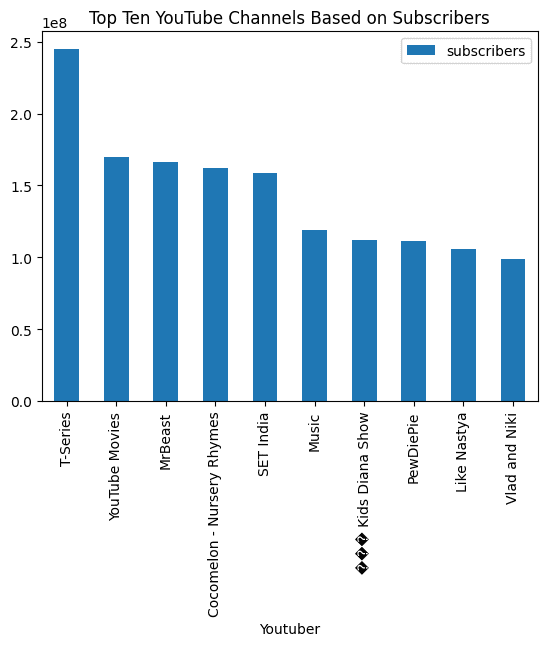
С помощью простого запроса и запросного движка мы можем автоматизировать анализ данных и выполнять сложные задачи. В LamaIndex есть гораздо больше возможностей. Я настоятельно рекомендую вам прочитать официальную документацию и попробовать создать что-то удивительное.
Заключение
В заключение, LlamaIndex – это захватывающий новый инструмент, который позволяет разработчикам создавать свой собственный PandasAI, используя мощь больших языковых моделей для интуитивного анализа данных и разговора. Индексируя и встраивая свой набор данных с помощью LlamaIndex, вы можете использовать передовые возможности естественного языка в своих собственных данных без ущерба для безопасности или переобучения моделей.
Это только начало, с LlamaIndex вы можете создавать Q&A над документами, чат-боты, автоматизированный искусственный интеллект, граф знаний, AI SQL Query Engine, полноценные веб-приложения и создавать частные генеративные AI-приложения. Абид Али Аван (@1abidaliawan) – сертифицированный профессионал в области науки о данных, который любит создавать модели машинного обучения. В настоящее время он сосредоточен на создании контента и написании технических блогов о технологиях машинного обучения и науке о данных. Абид имеет степень магистра по управлению технологиями и степень бакалавра по телекоммуникационной инженерии. Его цель – создать продукт искусственного интеллекта, используя графовую нейронную сеть, для студентов, страдающих от психических заболеваний.




