Управление памятью в Apache Spark Диск-сброс
Управление памятью в Apache Spark.
Что это и как с ним работать
В мире больших данных Apache Spark пользуется любовью за его способность обрабатывать огромные объемы данных с чрезвычайной скоростью. Будучи ведущим движком обработки больших данных в мире, изучение использования этого инструмента является основой навыков любого профессионала в области больших данных. И важным шагом в этом пути является понимание системы управления памятью Spark и проблемы “вытеснения на диск”.
Вытеснение на диск происходит, когда Spark больше не может поместить свои данные в память и должен сохранить их на диске. Одним из основных преимуществ Spark является его возможность обработки в памяти, которая гораздо быстрее, чем использование дисковых накопителей. Таким образом, создание приложений, которые вытесняются на диск, в значительной степени противоречит цели использования Spark.
Вытеснение на диск имеет ряд нежелательных последствий, поэтому важно научиться с ним справляться для разработчика Spark. И это то, чему поможет эта статья. Мы рассмотрим, что такое вытеснение на диск, почему оно происходит, каковы его последствия и как его исправить. Используя встроенный интерфейс пользователя Spark, мы научимся определять признаки вытеснения на диск и понимать его метрики. Наконец, мы изучим некоторые действенные стратегии для смягчения вытеснения на диск, такие как эффективное разделение данных, подходящее кэширование и динамическое изменение размера кластера.
Управление памятью в Spark
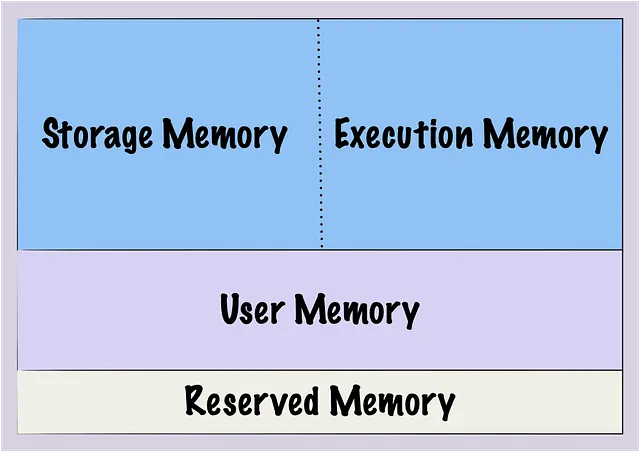
Прежде чем погрузиться в вытеснение на диск, полезно понять, как работает управление памятью в Spark, так как это играет ключевую роль в том, как происходит вытеснение на диск и как оно управляется.
- Безмозглый мягкий робот успешно перемещается в сложных средах в технологическом прорыве в робототехнике.
- Регулирование искусственного интеллекта делает первые шаги на Капитолийском Холме
- Ряд Фибоначчи на Python | Код, алгоритм и многое другое
Spark разработан как движок обработки данных в памяти, что означает, что он в основном использует ОЗУ для хранения и обработки данных, а не полагается на дисковое хранилище. Эта возможность вычисления в памяти является одной из ключевых особенностей, которая делает Spark быстрым и эффективным.
У Spark есть ограниченное количество памяти, выделенной для его операций, и эта память разделена на различные секции, которые составляют так называемую Unified Memory: