Десять советов и хитростей, которые можно применить в ваших проектах по Gen AI
10 советов и хитростей для проектов Gen AI
Уроки от производственного готового генеративного ИИ-приложения
Сегодня в использовании производственных генеративных ИИ-приложений не так много, я имею в виду приложения, которые развернуты и активно используются конечными пользователями. (Демонстрации, POC и Extractive AI не учитываются.) Генеративные ИИ-приложения, которые используются в производстве (например, Duet в Google Workspace, создание электронных писем продаж в Einstein GPT Salesforce), являются закрытыми и поэтому нельзя изучить их.
Вот почему я был взволнован, когда defog.ai сделал открытым код SqlCoder, модель NLP-to-SQL, которую они использовали в автоматизации нескольких рабочих процессов Генеративного ИИ у своих клиентов. Они также написали ряд блог-постов, детализирующих свой подход и свои мысли. Это дает мне конкретный пример, на который можно указать.

В этой статье я буду использовать SqlCoder для демонстрации конкретных примеров того, что вы можете делать в своих собственных проектах GenAI.
1. Создайте метрику оценки, которая вычисляется на основе того, как будет использоваться сгенерированный текст.
Как и в традиционном машинном обучении, метрика потерь, используемая для оптимизации LLM, не отражает его практическую пользу. Модели классификации обучаются с использованием потерь перекрестной энтропии, но оцениваются с помощью метрик, таких как AUM/F-мера или назначением экономической стоимости для ложных срабатываний и т.д.
- Первые 50 сессий объявлены для ODSC West 2023
- Тематическое моделирование с Llama 2
- 5 рабочих мест, которые будут использовать технологию Prompt в 2023 году
Аналогично, основные LLM обучаются для оптимизации метрик, таких как BLEU или ROUGE. На каком-то уровне все они меряют перекрытие токенов между сгенерированным текстом и меткой. Очевидно, что это не подходит для генерации SQL – метка “SELECT list_price” и сгенерированный текст “SELECT cost_price” не особо близки (токены в LLM являются подсловами, поэтому эти две строки отличаются всего 1 токеном!).
Способ, которым defog решает эту проблему, объясняется в этом блог-посте о том, как они проводили оценку. Вместо прямого сравнения строк SQL они выполняют сгенерированный SQL на небольшом наборе данных и сравнивают результаты. Это позволяет им принимать эквивалентный SQL, если SQL выполняет то же самое, что и метка. Однако что происходит, если столбцы имеют другие псевдонимы? Как обрабатывать результаты, которые находятся вне порядка? Что происходит, если сгенерированный SQL является надмножеством метки? Нужно учесть множество крайних случаев и нюансов. Прочитайте их блог-пост об оценке, если вас интересует эта конкретная проблема. Более общая точка зрения состоит в том, чтобы создать метрику оценки, которая вычисляется не на основе сгенерированной строки, а на основе того, как эта сгенерированная строка будет использоваться.
Многие научные статьи используют LLM (обычно GPT-4), чтобы “оценить” сгенерированный текст и использовать это в качестве метрики. Это не так хорошо, как создание правильной метрики оценки, потому что оценки LLM сильно смещены в пользу алгоритмов GPT и против многих умных оптимизаций, которые вы можете сделать. Также помните, что Open AI пришлось отключить свою службу, которая пыталась обнаружить ИИ-сгенерированный текст; если они не смогли заставить LLM-генерируемые оценки работать, почему вы думаете, что у вас получится?
2. Настройте отслеживание экспериментов
Прежде чем приступить к чему-либо, убедитесь, что у вас есть система для записи и обмена результатами ваших экспериментов. Вы будете проводить множество экспериментов, и вы хотите убедиться, что вы зафиксировали все, что вы попробовали.
Это может быть таким простым, как электронная таблица с следующими столбцами: эксперимент, дескрипторы эксперимента (подход, параметры, набор данных и т.д.), стоимость обучения, стоимость вывода, метрики (разделенные по подзадачам: см. ниже), качественные заметки. Или это может быть более сложным, используя систему отслеживания экспериментов в рамках различных платформ и фреймворков машинного обучения, таких как Vertex AI, Sagemaker, neptune.ai, Databricks, Datarobot и т.д.
Если вы не записываете эксперименты таким образом, чтобы это было повторяемо и согласовано для всех членов вашей команды, будет трудно принимать решения на следующих этапах.
3. Разбейте вашу проблему на подзадачи
Часто вам захочется проводить все свои оценки не на всем наборе данных для оценки, а на подмножествах этого набора данных, разбитых по задачам. Например, посмотрите, как defog сообщает о производительности на разных типах запросов:
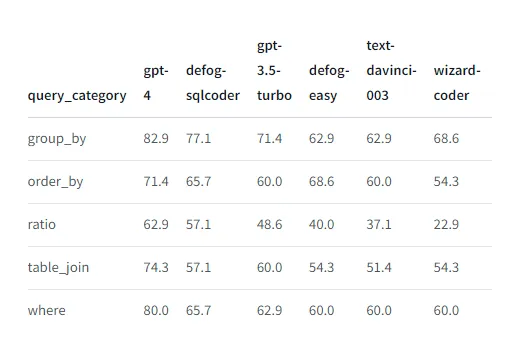
Существуют три причины, почему вы хотели бы проводить такие срезовые оценки:
- В конечном итоге вы столкнетесь с проблемой взаимосвязи между размером модели, производительностью и стоимостью. Один из способов выйти из этой ситуации – иметь несколько моделей машинного обучения, каждая из которых настроена на разные подзадачи. Многие люди подозревают, что GPT-4 сам по себе является ансамблем моделей GPT 3.5-го качества. [Кстати, это одна из причин, по которой отдельные LLM-ы плохо справляются с GPT-4 – вам нужно построить ансамбль моделей, чтобы его победить.]
- Если у вас есть несколько заинтересованных сторон, они могут быть заинтересованы в разных вещах. В этом случае обязательно разработайте и отслеживайте метрики, соответствующие каждой из их целей. Вы также можете рассматривать эти различные цели как подзадачи и начать отслеживать их. Вероятно, вам придется создать несколько моделей, по одной для каждой заинтересованной стороны. Опять же, вы можете рассматривать эти модели как членов ансамбля.
- Третья причина для срезовой оценки подзадач заключается в том, что золотой стандарт оценки машинного обучения – представить его панели экспертов-людей. Это часто слишком дорого. Однако, если вы когда-нибудь будете проводить оценку людей, убедитесь, что вы делаете это таким образом, чтобы вы позже могли использовать вычисленные метрики для “предсказания”, какой может быть оценка человека. Более полная информация о проблеме может быть полезна для проведения такой калибровки.
4. Применение приемов инжиниринга подсказок
Все подходы к использованию искусственного интеллекта требуют отправки текстовой подсказки обученной модели языкового моделирования. Со временем сообщество узнало множество полезных советов и трюков для создания хороших подсказок. Обычно в документации к моделям языкового моделирования указано, что работает (например, OpenAI Cookbook, Lllama2, Google PaLM) – убедитесь, что вы прочитали это и используете предложенные техники!
Подсказка defog:
prompt = """### Инструкции: Ваша задача - преобразовать вопрос в SQL-запрос, учитывая схему базы данных Postgres. Соблюдайте следующие правила:- **Тщательно просмотрите вопрос и схему базы данных слово за словом**, чтобы адекватно ответить на вопрос- **Используйте псевдонимы таблиц** для предотвращения двусмысленности. Например, `SELECT table1.col1, table2.col1 FROM table1 JOIN table2 ON table1.id = table2.id`.- При создании отношения всегда приводите числитель к типу float### Вход: Сгенерируйте SQL-запрос, отвечающий на вопрос `{question}`. Этот запрос будет выполняться на базе данных, схема которой представлена в этой строке:CREATE TABLE products ( product_id INTEGER PRIMARY KEY, -- Уникальный идентификатор для каждого продукта name VARCHAR(50), -- Название продукта price DECIMAL(10,2), -- Цена за единицу продукта quantity INTEGER -- Текущее количество на складе);CREATE TABLE customers ( customer_id INTEGER PRIMARY KEY, -- Уникальный идентификатор для каждого клиента name VARCHAR(50), -- Имя клиента address VARCHAR(100) -- Почтовый адрес клиента);...-- sales.product_id можно соединить с products.product_id-- sales.customer_id можно соединить с customers.customer_id-- sales.salesperson_id можно соединить с salespeople.salesperson_id-- product_suppliers.product_id можно соединить с products.product_id### Ответ: В соответствии с вашими инструкциями, вот SQL-запрос, который я сгенерировал для ответа на вопрос `{question}`:```sql"""Это демонстрирует несколько трюков:
- Задача ввода. Преамбула (“Ваша задача … SQL … база данных Postgres …”) называется задачей ввода. Это входные данные для этапа обучения инструкционной модели языковой модели. Напомню, что в основе LLM лежит машина для автодополнения текста. Любая вещь, которую вы можете сделать, чтобы увеличить вероятность слов в нужной части пространства слов, будет полезна. Поэтому многие LLM работают лучше, если ваша преамбула направляет LLM в ту часть пространства слов, которая вам важна. Важно использовать слова, связанные с SQL, Postgres и т.д. в преамбуле defog.
- Системная подсказка. Правила (“просматривайте вопрос и схему слово за словом, используйте псевдонимы таблиц и т.д.”) формируют то, что называется системной подсказкой. Она используется для направления и ограничения поведения. [Мое предложение команде defog было бы избегать сложных слов, а использовать более простые, такие как “Всегда” и “Никогда” – они обычно работают лучше.] LLM обучены следовать системным подсказкам (вот как они защищаются от токсичности, например). Используйте их в свою пользу.
- Начало и конец контекста. Вопрос, на который нужно ответить, встречается дважды. Один раз в разделе Вход и еще раз в разделе Ответ. Это размещение – в начале и в конце – не случайно. LLM обычно весит среднюю часть контекста ниже, особенно если ваша подсказка (как здесь) очень длинная. Размещайте самые важные вещи в начале и в конце. Повторение может помочь (проведите эксперимент, чтобы узнать, действительно ли оно помогает).
- Структурированный в
Кстати, вы можете увидеть №7 и №8 в Google Workspace Duet. Если ошибка не была исправлена, попробуйте выбрать слишком длинный параграф (длиннее контекста) и попросить его сделать сводку. Результат будет содержать слово “Instruction”, которое является частью системного промпта. Причина, по которой вы его видите, заключается в том, что специальные символы, которые ограничивают вывод, отсутствовали в ответе. Многочисленные попытки хакеров-исследователей LLM начинаются с переполнения ответа — обрезание позволяет обнаружить много ошибок и непредвиденного поведения.
5. Интеллектуальное сочетание различных подходов в вашей архитектуре
Сейчас существуют пять подходов к построению на основе генеративного ИИ:
- Zero-shot: просто отправка запроса LLM. Вы полностью полагаетесь на обучающие данные LLM.
- Few-shot: Включение 1-2 примеров ввода и ответов в контекст. Эти примеры могут быть фиксированными или могут быть получены на основе наиболее релевантных примеров для запроса. Это обычно просто способ направить LLM, а не учить его новой информации или новым задачам.
- Дополненное генерирование с использованием поиска по сходству (RAG): Получение релевантных данных, обычно из векторной базы данных на основе поиска по сходству, и включение их в контекст. Это способ учить LLM новой информации (сегодняшние LLM не могут обучаться новым навыкам с использованием RAG).
- Тонкая настройка. Обычно это делается параметрически эффективным способом с использованием подхода низкоранговой адаптации (LoRA) обучения отдельной нейронной сети, которая изменяет веса LLM, чтобы LLM мог справиться с новыми задачами. При тонкой настройке вы обучаете LLM обрабатывать новую инструкцию (сегодняшние LLM не могут учиться новой информации путем тонкой настройки).
- Агентский фреймворк. Получите LLM, чтобы сгенерировать параметры, которые вы передадите внешнему API. Это может быть использовано для добавления большего количества навыков и знаний в LLM, но может быть опасным без человека в процессе.
Как видно, каждый подход имеет свои преимущества и недостатки. Поэтому то, что делает defog, является смесью нескольких из этих подходов. В конечном итоге, они используют #5 (генерацию SQL, который будет отправлен в базу данных), но помещают SQL на пути сложного рабочего процесса, который управляется пользователем. Они выбирают необходимую схему и правила объединения (#3) на основе запроса. Они настроили (#4) небольшую модель для эффективного управления затратами. И они вызывают настроенную модель способом zero-shot (#1).
Такое интеллектуальное сочетание подходов является необходимым для использования преимуществ различных подходов и защиты от их недостатков.
6. Очистка и организация набора данных
Становится ясно, что в Gen AI важны как количество, так и качество ваших данных. Defog поставил перед собой цель получить 10 тыс. примеров обучения, чтобы настроить модель на заказ (похоже, они настраивают модели для каждого клиента: см. обсуждение ранее о подзадачах), и большая часть их усилий направлена на очистку набора данных.
Вот краткий список контроля при обеспечении оптимальности вашего набора данных:
- Корректность. Убедитесь, что все ярлыки правильные. Defog обеспечивает это, убедившись, что необходимый SQL выполняется и производит фрейм данных, который можно сравнить с фреймами данных, созданными из сгенерированного текста.
- Курирование данных. Platypus смог улучшить Llama2, просто удалив дубликаты из обучающего набора данных, удалив вопросы, относящиеся к серому зоне и т. д.
- Разнообразие данных. Важно мудро использовать 10 тыс. примеров и показать LLM хорошее разнообразие того, с чем он столкнется в производстве. Обратите внимание, как Platypus использует множество открытых наборов данных или как defog использовал 10 отдельных наборов схем вместо обучения только на одном наборе таблиц.
- Evol-instruct. В статье “Textbooks are all you need” показано, насколько важно выбирать простые примеры в порядке увеличения сложности. defog использует LLM для адаптации набора инструкций в более сложные.
- Назначение уровня сложности примерам. Существует много случаев, когда сегментация обучающего набора данных по сложности может быть полезной. Вы можете использовать срезанную метрику оценки (см. совет №3), обучать более простые модели для более простых задач, использовать это как эффективный механизм ансамблирования, обучать модель поэтапно увеличивающейся сложности и т. д.
Это совет, который даст вам наибольший прирост производительности.
7. Принимайте решение о создании или покупке на основе конкретной ситуации
Большие модели требуют значительных затрат на обслуживание. Вы можете достичь конкурентных результатов, настраивая более маленькую модель на отобранных наборах данных. Это может стоить в 10 раз меньше или даже меньше стоимости большой модели. Кроме того, вы можете использовать настроенную модель на своей территории, на краю сети и т. д. При расчете возврата инвестиций не игнорируйте финансовые и стратегические выгоды владения моделью.
Тем не менее, GPT-4 от Open AI часто обеспечивает отличную производительность изначально. Если вы можете предвидеть масштаб, в котором вы будете использовать API Open AI, вы можете оценить, сколько это будет стоить в производстве. Если ваши запросы будут достаточно редкими, настройка не имеет финансового смысла из-за затрат на разработку. Даже если вы начинаете с настройки, сравнивайте с моделью последнего поколения и будьте готовы изменить свой подход при необходимости.
Вряд ли у вас будет достаточно ресурсов, чтобы создавать пользовательские модели для всех ваших потребностей. Поэтому у вас, вероятно, будет смесь приобретенных и созданных моделей. Не попадайте в ловушку постоянного создания или всегда покупайте.
8. Абстрагируйтесь от конкретной LLM
OpenAI – не единственный игрок в этой области. Google намекает, что их предстоящая модель Gemini лучше, чем GPT-4. Вероятно, каждые несколько месяцев будет появляться новая передовая модель. Ваша оценка должна включать в себя любую модель (GPT-4, Gemini или GPT-5), которая будет передовой на момент вашего прочтения этого. Однако убедитесь также в сравнении производительности и стоимости с другими моделями, близкими к передовым, такими как Cohere или Anthropic, а также с предыдущими поколениями, такими как GPT 3.5 и PaLM2.
Какую модель вы покупаете, в основном является бизнес-решением. Незначительные различия в производительности редко стоят больших разниц в стоимости. Поэтому сравнивайте производительность и стоимость нескольких вариантов.
Используйте langchain, чтобы абстрагироваться от LLM и учесть экономические выгоды в вашей рамке экспериментов. Это поможет вам эффективно вести переговоры.
9. Разверните в качестве API
Даже ваша “маленькая” модель с настройкой параметров в 13 ГБ загружается очень долго и требует группы графических процессоров для обслуживания. Развертывайте ее в виде API, даже для внутренних пользователей, и используйте службу шлюза для учета и мониторинга.
Если ваши конечные пользователи – программисты приложений, задокументируйте интерфейс API, а если вы поддерживаете разные приглашения, задокументируйте их и предоставьте модульные тесты, чтобы убедиться, что вы не нарушаете последующие рабочие процессы, использующие эти конкретные приглашения.
Если ваши конечные пользователи не технически подкованы, API недостаточно. Как показывает defog, хорошей идеей будет предоставить интерфейс площадки с примерами запросов (“чипами”) с использованием, например, streamlit. Если ваши конечные пользователи – разработчики ML, используйте HuggingFace для вашей функциональности площадки.
10. Автоматизируйте вашу тренировку
Убедитесь, что ваша система настройки модели полностью автоматизирована.
Используйте ту платформу облачного ML, которую обычно используете, но также учтите стоимость и наличие GPU/TPU в вашем регионе. Есть также несколько стартапов, которые предоставляют “LLMops” в качестве услуги и часто являются более экономически выгодными, чем крупные облачные провайдеры, потому что они используют выгодные предложения, владеют своим оборудованием или тратят чужие деньги.
Хорошим способом сохранить выбор здесь является контейниризация всей системы. Таким образом, вы можете легко перенести свою систему (по)тренировки туда, где есть графические процессоры.
Резюме

Ссылки
- https://defog.ai/
- SqlCoder: https://defog.ai/blog/open-sourcing-sqlcoder/
- SQL Evaluation metric: https://github.com/defog-ai/sql-eval
- Can foundation models label data like humans https://huggingface.co/blog/llm-leaderboard
- OpenAI cookbook, Lllama2, Google PaLM
- Lost in the middle: how language models use long contexts. https://arxiv.org/abs/2307.03172
- Platypus AI: https://www.geeky-gadgets.com/platypus-ai/
- Evol-Instruct, from WizardLM: Empowering Large Language Models to Follow Complex Instructions. https://arxiv.org/abs/2304.12244