GPT-4 8 моделей в одной; Секрет раскрыт
GPT-4 8 моделей в одной; Секрет раскрыт
Модель GPT4 была революционной моделью до сих пор, доступной широкой публике бесплатно или через их коммерческий портал (для использования в публичной бета-версии). Она сделала чудеса, вдохновляя новые идеи проектов и использования для многих предпринимателей, но тайна о количестве параметров и модели убивала всех энтузиастов, которые делали ставки на модель с первым триллионом параметров по заявкам на сто триллионов параметров!
Кот выскочил из мешка
Ну, кот выскочил из мешка (типа). 20 июня основатель стартапа по самоуправляемой езде Comma.ai Джордж Хотз утечкой сообщил, что GPT-4 не является единой монолитной плотной моделью (как GPT-3 и GPT-3.5), а является смесью 8 моделей с 220 миллиардами параметров каждая.
- Лучшие курсы по искусственному интеллекту от университетов с плейлистами на YouTube
- Xbox PC Game Pass приходит на GeForce NOW вместе с 25 новыми играми
- Топ-10 редакторов фотографий с искусственным интеллектом для использования в 2023 году
Позднее в тот же день Сумит Чинтала, сооснователь PyTorch в Meta, подтвердил утечку.
За день до этого Михаил Парахин, руководитель Microsoft Bing AI, тоже намекал на это.
GPT 4: Не монолит
Что означают все эти твиты? GPT-4 – это не единая большая модель, а союз/ансамбль из 8 меньших моделей, делящих свой опыт. Каждая из этих моделей, по слухам, имеет 220 миллиардов параметров.

Методология называется моделью смеси экспертов (ссылка ниже). Это хорошо известная методология, также называемая гидрой модели. Это напоминает мне индийскую мифологию, я выберу Равану.
Пожалуйста, отнеситесь к этому с некоторой долей скептицизма, это не официальная новость, но значительные члены сообщества искусственного интеллекта заговорили/намекнули на это. Microsoft еще не подтвердила ничего из этого.
Что такое парадигма смеси экспертов?
Теперь, когда мы говорили о смеси экспертов, давайте немного поглубже разберемся, что это такое. Смесь экспертов – это техника ансамбля обучения, разработанная специально для нейронных сетей. Она отличается от общей техники ансамбля для традиционного моделирования машинного обучения (эта форма является обобщенной формой). Так что вы можете считать, что смесь экспертов в LLM – это особый случай для методов ансамбля.
Вкратце, в этом методе задача разделяется на подзадачи, и для каждой подзадачи используются эксперты для решения моделей. Это способ подхода “разделяй и властвуй” при создании деревьев решений. Можно также рассматривать это как метаобучение поверх моделей экспертов для каждой отдельной задачи.
Для каждой подзадачи или типа проблемы можно обучить более маленькую и лучшую модель. Метамодель учится использовать ту модель, которая лучше всего предсказывает конкретную задачу. Метаобучающаяся модель действует как дорожный полицейский. Подзадачи могут перекрываться или не перекрываться, что означает, что комбинация выходных данных может быть объединена для получения конечного результата.
За концепт-описания от MOE до Pooling все заслуги принадлежат отличному блогу Джейсона Браунли (https://machinelearningmastery.com/mixture-of-experts/). Если вам понравилось то, что вы читаете ниже, пожалуйста, подпишитесь на блог Джейсона и купите одну или две его книги, чтобы поддержать его потрясающую работу!
Смесь экспертов, MoE или ME в сокращении, – это метод ансамбля обучения, который реализует идею обучения экспертов на подзадачах проблемы предсказательного моделирования.
В сообществе нейронных сетей несколько исследователей рассмотрели методологию декомпозиции. […] Методология смеси экспертов (ME), которая разбивает пространство входных данных на части, так что каждый эксперт рассматривает разные части пространства. […] Сеть выбора отвечает за комбинирование различных экспертов.
— Стр. 73, “Классификация шаблонов с использованием методов ансамбля”, 2010 г.
В этом подходе есть четыре элемента:
- Разделение задачи на подзадачи.
- Создание эксперта для каждой подзадачи.
- Использование модели селектора для определения, какой эксперт использовать.
- Объединение прогнозов и вывод модели селектора для получения прогноза.
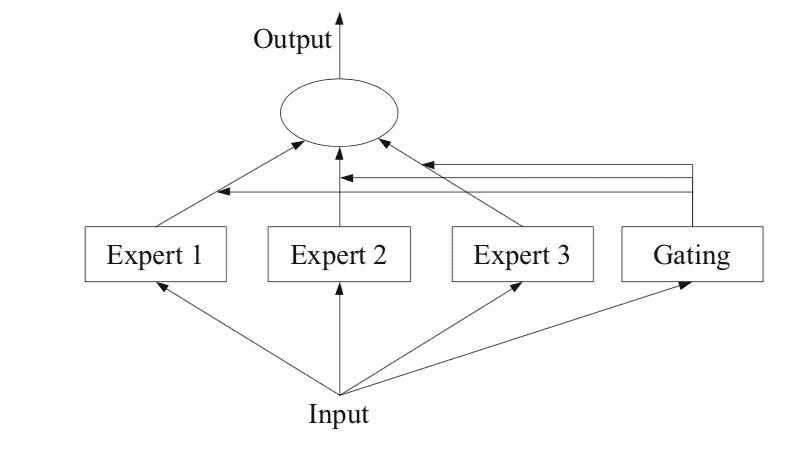
На рисунке ниже, взятом со страницы 94 книги 2012 года “Методы ансамблей”, представлена полезная обзорная информация об архитектурных элементах метода.
Как работают 8 меньших моделей в GPT4?
Секрет “Модели экспертов” раскрыт, давайте поймем, почему GPT4 так хорош!
ithinkbot.com
Подзадачи
Первый шаг – разделить прогностическую модельную задачу на подзадачи. Это часто включает использование предметных знаний. Например, изображение может быть разделено на отдельные элементы, такие как фон, передний план, объекты, цвета, линии и так далее.
… модель экспертов работает по стратегии “разделить и властвовать”, где сложная задача разбивается на несколько более простых и меньших подзадач, и для каждой подзадачи обучаются отдельные модели (эксперты).
— Страница 94, “Методы ансамблей”, 2012 год.
Для тех задач, где разделение задачи на подзадачи неочевидно, можно использовать более простой и общий подход. Например, можно представить подход, который разделяет пространство входных признаков по группам столбцов или разделяет примеры в пространстве признаков на основе мер расстояния, выбросов и выборки в стандартном распределении, и многое другое.
… в модели экспертов ключевой проблемой является определение естественного разделения задачи и затем получение общего решения из подрешений.
— Страница 94, “Методы ансамблей”, 2012 год.
Модели экспертов
Затем для каждой подзадачи создается экспертная модель.
Подход смеси экспертов изначально был разработан и исследован в области искусственных нейронных сетей, поэтому традиционно эксперты сами являются моделями нейронных сетей, используемыми для предсказания числового значения в случае регрессии или метки класса в случае классификации.
Ясно, что мы можем “подключить” любую модель в качестве эксперта. Например, мы можем использовать нейронные сети для представления как функций гейтинга, так и экспертов. Результат известен как сеть смеси плотностей.
— Страница 344, “Машинное обучение: вероятностная перспектива”, 2012 год.
Каждый эксперт получает одинаковый входной образец (строку) и делает прогноз.
Модель гейтинга
Модель используется для интерпретации прогнозов, сделанных каждым экспертом, и для помощи в принятии решения о том, какому эксперту доверять для данного входа. Это называется моделью гейтинга или гейтинговой сетью, поскольку традиционно это модель нейронной сети.
Гейтинговая сеть получает на вход входной образец, который был предоставлен моделям экспертов, и выводит вклад, который должен внести каждый эксперт в прогноз для входа.
… веса, определенные гейтинговой сетью, динамически назначаются на основе данного входа, поскольку МЭ эффективно изучает, какая часть пространства признаков изучается каждым участником ансамбля
— Страница 16, “Ансамбльное машинное обучение”, 2012 год.
Гейтинговая сеть является ключевым элементом подхода, и в результате модель обучается выбирать тип подзадачи для данного входа и, в свою очередь, эксперта, которому нужно доверять для получения сильного прогноза.
Смесь экспертов также может рассматриваться как алгоритм выбора классификатора, где отдельные классификаторы обучаются становиться экспертами в некоторой части пространства признаков.
— Страница 16, “Ансамбльное машинное обучение”, 2012 год.
Когда используются модели нейронных сетей, гейтинговая сеть и эксперты обучаются вместе так, чтобы гейтинговая сеть училась, когда доверять каждому эксперту для прогноза. Эта процедура обучения традиционно реализуется с помощью метода ожидания и максимизации (EM). У гейтинговой сети может быть выход softmax, который дает вероятностно-подобный показатель уверенности для каждого эксперта.
В общем случае процедура обучения стремится достичь двух целей: для заданных экспертов найти оптимальную функцию гейтинга; для заданной функции гейтинга обучить экспертов на распределении, заданном функцией гейтинга.
— Страница 95, Ensemble Methods, 2012.
Метод объединения
Наконец, модели экспертов должны сделать прогноз, и это достигается с помощью механизма объединения или агрегации. Это может быть так просто, как выбор эксперта с наибольшим выводом или уверенностью, предоставленной сетью гейтинга.
В качестве альтернативы может быть сделан прогноз с взвешенной суммой, который явно комбинирует прогнозы, сделанные каждым экспертом, и уверенность, оцененную сетью гейтинга. Вы можете представить себе и другие подходы к эффективному использованию прогнозов и выхода сети гейтинга.
Система объединения/комбинирования может выбирать один классификатор с наибольшим весом или вычислять сумму с весами выходов классификаторов для каждого класса и выбирать класс, который получает наибольшую сумму с весами.
— Страница 16, Ensemble Machine Learning, 2012.
Маршрутизация переключателя
Мы также должны кратко обсудить, чем отличается подход маршрутизации переключателя от статьи “MoE”. Я упоминаю это, так как кажется, что Microsoft использовала маршрутизацию переключателя, а не модель экспертов, чтобы сэкономить вычислительную сложность, но я готов быть опровергнутым. Когда есть более одной модели экспертов, у них может быть нетривиальный градиент для функции маршрутизации (какую модель использовать). Эту границу принятия решения контролирует слой переключателя.
Преимущества слоя переключателя тройные.
- Вычисление маршрутизации сокращается, если токен маршрутизируется только в одну модель эксперта
- Размер пакета (емкость эксперта) может быть уменьшен как минимум вдвое, так как один токен идет в одну модель
- Реализация маршрутизации упрощается, и обмен данными сокращается.
Перекрытие одного и того же токена более чем в одной модели эксперта называется фактором емкости. Ниже представлен концептуальный образец того, как работает маршрутизация с различными факторами емкости эксперта
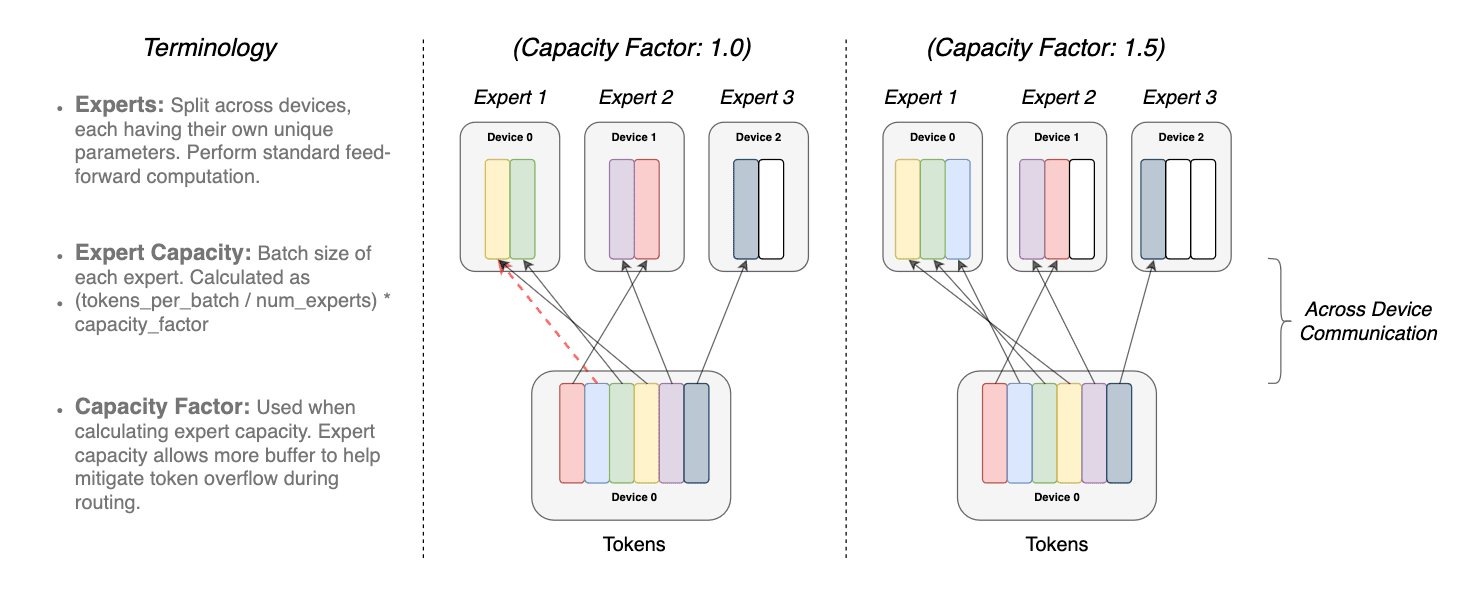
токенов, модулированных фактором емкости. Каждый токен маршрутизируется к эксперту
с наибольшей вероятностью, но каждый эксперт имеет фиксированный размер пакета
(общее количество токенов/количество экспертов) × фактор емкости. Если токены неравномерно распределены,
то некоторые эксперты переполнятся (обозначено пунктирными красными линиями), что приведет
к тому, что эти токены не будут обрабатываться этим слоем. Более большой фактор емкости снижает
эту проблему переполнения, но также увеличивает вычислительные и коммуникационные затраты
(изображено белыми/пустыми слотами). (источник https://arxiv.org/pdf/2101.03961.pdf)
По сравнению с “MoE”, результаты исследований в статье “MoE” и “Switch” показывают, что
- Трансформаторы переключателя превосходят тщательно настроенные плотные модели и трансформаторы “MoE” по соотношению скорость-качество.
- Трансформаторы переключателя имеют меньший вычислительный след, чем “MoE”
- Трансформаторы переключателя показывают лучшие результаты при более низких факторах емкости (1–1.25).

Заключительные мысли
Две оговорки, во-первых, все это основано на слухах, и, во-вторых, мое понимание этих концепций довольно слабо, поэтому я настоятельно рекомендую читателям воспринимать это с большой долей сомнения.
Но что добилась Microsoft, скрывая эту архитектуру? Они создали ажиотаж и напряжение вокруг этого. Это могло помочь им лучше обозначить свои нарративы. Они хранили инновации у себя и избегали того, чтобы другие догнали их раньше. Весь идеал, вероятно, был обычной игрой Microsoft по противодействию конкуренции, пока они инвестируют 10 млрд в компанию.
Производительность GPT-4 отлична, но она не является инновационным или прорывным дизайном. Это удивительно умная реализация методов, разработанных инженерами и исследователями, дополненная предприятий/капиталистическим внедрением. OpenAI ни отрицает, ни соглашается с этими утверждениями (https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed), что заставляет меня думать, что эта архитектура для GPT-4 скорее всего является реальностью (что здорово!). Просто не круто! Мы все хотим знать и учиться.
Огромная заслуга принадлежит Альберто Ромеро, который выявил эту новость и дальше исследовал ее, связавшись с OpenAI (которые, согласно последнему обновлению, не ответили). Я увидел его статью в Linkedin, но она также была опубликована на VoAGI.
Доктор Мандар Кархаде, МД, доктор философии. Старший директор по передовой аналитике и стратегии данных в Avalere Health. Мандар – опытный врач-ученый, работающий над актуальными реализациями искусственного интеллекта в области наук о жизни и здравоохранения уже более 10 лет. Мандар также является частью AFDO/RAPS, помогающей регулировать внедрение искусственного интеллекта в сферу здравоохранения.
Оригинал. Перепечатка с разрешения.