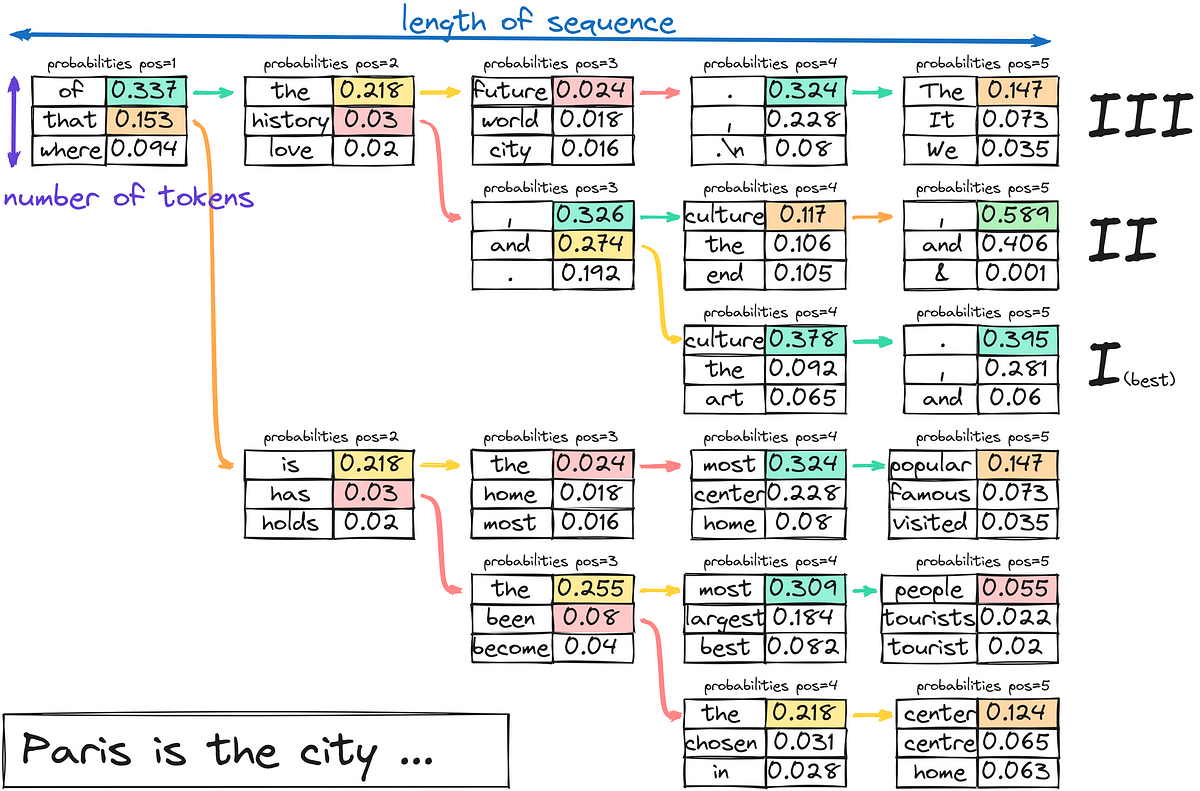
Обучение с временной разницей и важность исследования иллюстрированное руководство
TD Learning and the Importance of Exploration an Illustrated Guide
Сравнение безмодельных и модельных методов обучения с подкреплением на динамическом сеточном мире
Недавно алгоритмы обучения с подкреплением (RL) получили много внимания, решая исследовательские проблемы, такие как складывание белка, достигая сверхчеловеческого уровня в гонках дронов или даже интеграция обратной связи человека в ваших любимых чат-ботах.
Действительно, RL предоставляет полезные решения для различных проблем последовательного принятия решений. Методы обучения с временной разницей (TD learning) являются популярным подмножеством алгоритмов RL. Методы TD learning объединяют ключевые аспекты методов Monte Carlo и динамического программирования, чтобы ускорить обучение без необходимости в идеальной модели динамики окружения.
В этой статье мы сравним различные виды алгоритмов TD в настраиваемом сеточном мире. Дизайн эксперимента подчеркнет важность непрерывного исследования и индивидуальные характеристики тестируемых алгоритмов: Q-learning, Dyna-Q и Dyna-Q+.
Структура этого поста включает:
- Google DeepMind представляет новый инструмент искусственного интеллекта, который классифицирует эффекты 71 миллиона мутаций миссенс.
- Разблокировка оптимизации батарей Как машинное обучение и наномасштабная рентгеновская микроскопия могут революционизировать литиевые батареи
- Теперь вы видите меня (CME) Извлечение модели на основе концепции
- Описание окружения
- Обучение с временной разницей (TD learning)
- Безмодельные методы TD (Q-learning) и модельные методы TD (Dyna-Q и Dyna-Q+)
- Параметры
- Сравнение производительности
- Выводы
Полный код, позволяющий воспроизвести результаты и графики, доступен здесь: https://github.com/RPegoud/Temporal-Difference-learning
Окружение
Окружение, которое мы будем использовать в этом эксперименте, представляет собой сеточный мир со следующими особенностями:
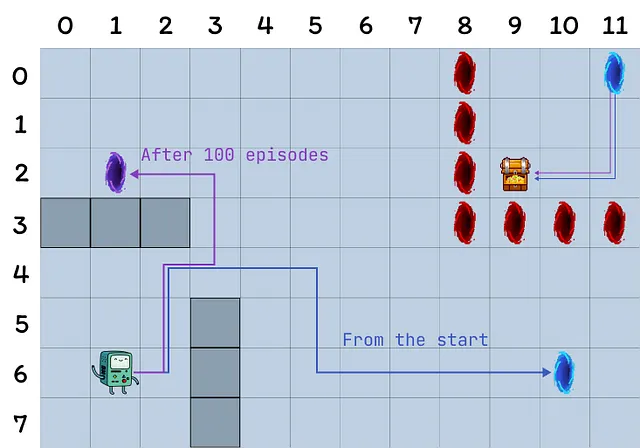
- Сетка состоит из 12 на 8 ячеек.
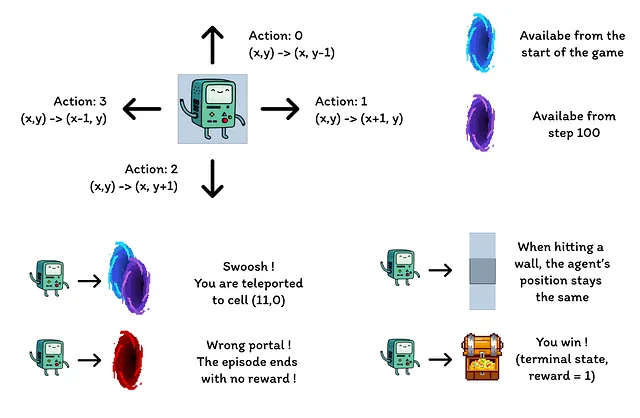
- Агент начинает в нижнем левом углу сетки, цель состоит в достижении сокровища, находящегося в верхнем правом углу (терминальное состояние с вознаграждением 1).
- Синие порталы соединены, проходящий через портал, расположенный в ячейке (10, 6), приводит к ячейке (11, 0). Агент не может повторно использовать портал после первого перехода.
- Фиолетовый портал появляется только после 100 эпизодов, но позволяет агенту достигать сокровища быстрее. Это стимулирует непрерывное исследование окружения.
- Красные порталы – это ловушки (терминальные состояния с вознаграждением 0) и завершают эпизод.
- Столкновение с стеной заставляет агента оставаться в том же состоянии.
Этот эксперимент направлен на сравнение поведения агентов Q-learning, Dyna-Q и Dyna-Q+ в изменяющейся среде. Действительно, после 100 эпизодов оптимальная стратегия обязательно изменится, и оптимальное количество шагов в успешном эпизоде уменьшится с 17 до 12.
Введение в обучение с временной разницей:
Обучение методом временных разностей (Temporal-Difference Learning) является комбинацией методов Монте-Карло (MC) и Динамического программирования (DP):
- Как и методы MC, методы TD могут учиться из опыта без необходимости модели динамики окружения.
- Как и методы DP, методы TD обновляют оценки после каждого шага на основе других полученных оценок, не дожидаясь результата (это называется бутстрэпингом).
Одной из особенностей методов TD является то, что они обновляют свою оценку значения на каждом шаге времени, в отличие от методов MC, которые ждут до конца эпизода.
Действительно, оба метода имеют разные цели обновления. Методы MC стремятся обновить возвращение Gt, которое доступно только в конце эпизода. Вместо этого, методы TD нацеливаются на:
Где V – это оценка истинной функции значения Vπ.
Таким образом, методы TD соединяют выборку из MC (используя оценку истинного значения) и бутстрэпинг из DP (обновление V на основе оценок, основанных на других оценках).
Самая простая версия обучения методом временных разностей называется TD(0) или одношаговый TD, практическая реализация TD(0) выглядит следующим образом:
![Псевдокод для алгоритма TD(0), взят из Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*YxhtNxDc985zRjMd7wPKJg.png)
При переходе из состояния S в новое состояние S’, алгоритм TD(0) вычисляет забэкапленное значение и соответствующим образом обновляет V(S). Это забэкапленное значение называется ошибкой TD, разницей между оптимальной функцией значения V_star и нашей текущей оценкой V(S):
В заключение, методы TD имеют несколько преимуществ:
- Они не требуют идеальной модели динамики окружения p
- Они реализуются в режиме онлайн, обновляя цель после каждого шага времени
- TD(0) гарантированно сходится для любой фиксированной политики π, если α (скорость обучения или размер шага) удовлетворяет условиям стохастической аппроксимации (дополнительные подробности см. на странице 55 “Tracking a Nonstationary Problem” в [4])
Детали реализации:
Следующие разделы изучают основные характеристики и производительность нескольких TD алгоритмов на сетке мира.
Все модели использовали одни и те же параметры для простоты:
- Epsilon (ε) = 0.1: вероятность выбора случайного действия в ε-жадных стратегиях
- Gamma (γ)= 0.9: коэффициент дисконтирования, применяемый к будущим наградам или оценкам значения
- Aplha (α) = 0.25: скорость обучения, ограничивающая обновления значения Q
- Планировочные шаги = 100: для Dyna-Q и Dyna-Q+, количество выполняемых планировочных шагов для каждого прямого взаимодействия
- Kappa (κ)= 0.001: для Dyna-Q+, вес бонусных наград, применяемых во время планировочных шагов
Результаты каждого алгоритма сначала представлены для одного прогона из 400 эпизодов (разделы: Q-обучение, Дина-кью и Дина-кью+), а затем усреднены по 100 прогонам из 250 эпизодов в разделе “сводка и сравнение алгоритмов”.
Q-обучение
Первый алгоритм, который мы реализуем здесь, – это известное Q-обучение (Watkins, 1989):
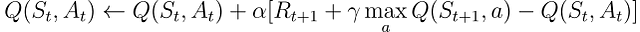
Q-обучение называется off-policy алгоритмом, так как его целью является прямое приближение оптимальной функции значения вместо функции значения π, политики, которую следует агент.
На практике Q-обучение все еще зависит от политики, часто называемой “поведенческой политикой”, чтобы выбирать, какие пары состояние-действие посещаются и обновляются. Однако, Q-обучение является off-policy, потому что оно обновляет свои Q-значения на основе лучшей оценки будущих вознаграждений, независимо от того, следуют ли выбранные действия текущей политике π.
По сравнению с предыдущим псевдокодом для TD-обучения, есть три основных отличия:
- Нам нужно инициализировать функцию Q для всех состояний и действий, и Q(терминальное) должно быть равно 0
- Действия выбираются из политики на основе значений Q (например, политика ϵ-жадной относительно значений Q)
- Обновление нацелено на функцию значения действия Q, а не на функцию значения состояния V
![Псевдокод для алгоритма Q-обучения, взятый из Reinforcement Learning, an introduction [4]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*l5_4S_WDALtIROP2HOhJ0w.png)
Теперь, когда у нас есть наш первый алгоритм, готовый для тестирования, мы можем начать фазу обучения. Наш агент будет перемещаться по Grid World, используя свою ε-жадную политику относительно значений Q. Эта политика выбирает действие с наивысшим значением Q с вероятностью (1 – ε) и выбирает случайное действие с вероятностью ε. После каждого действия агент будет обновлять свои оценки значений Q.
Мы можем визуализировать эволюцию оценки максимального значения действия Q(S, a) каждой ячейки Grid World с помощью тепловой карты. Здесь агент играет 400 эпизодов. Поскольку есть только одно обновление на эпизод, эволюция Q-значений происходит довольно медленно, и большая часть состояний остается неотображенной:
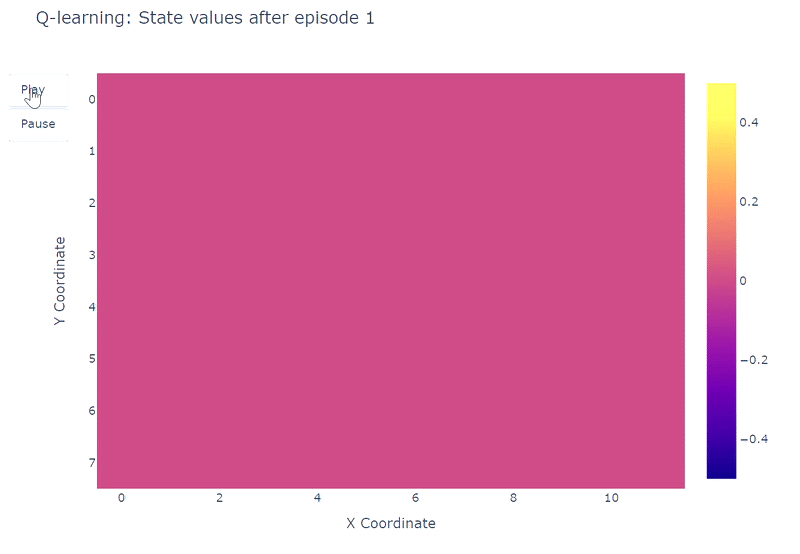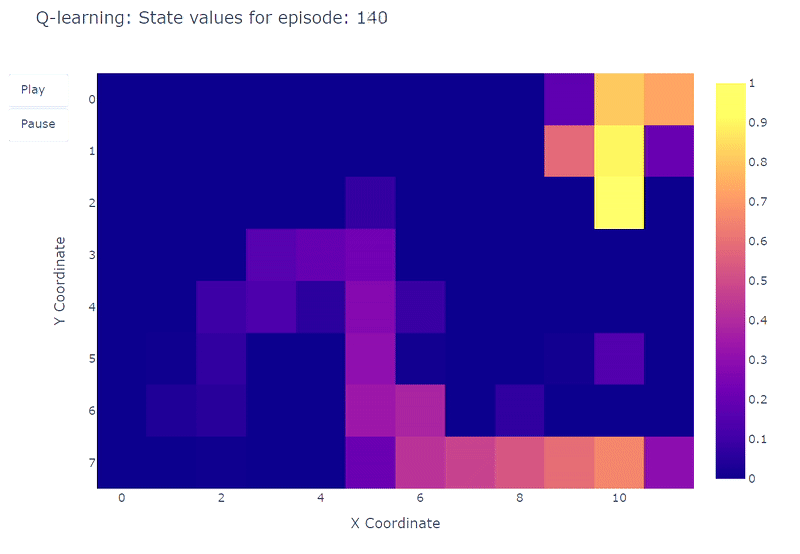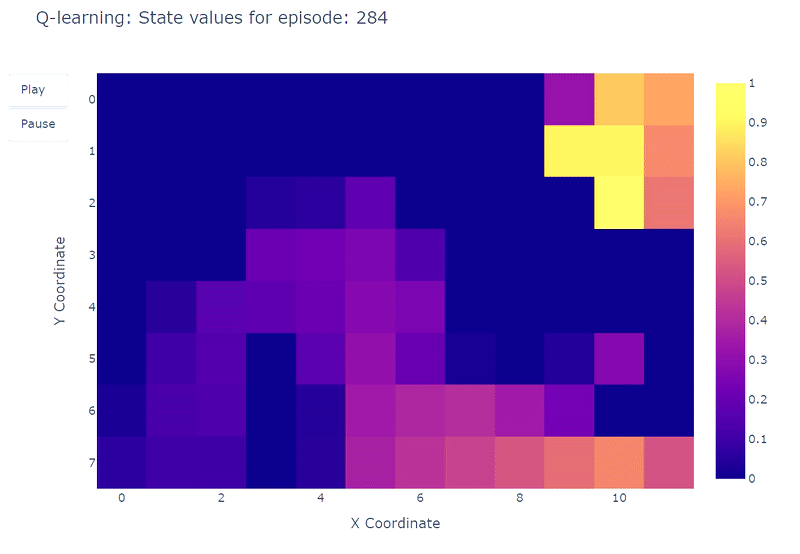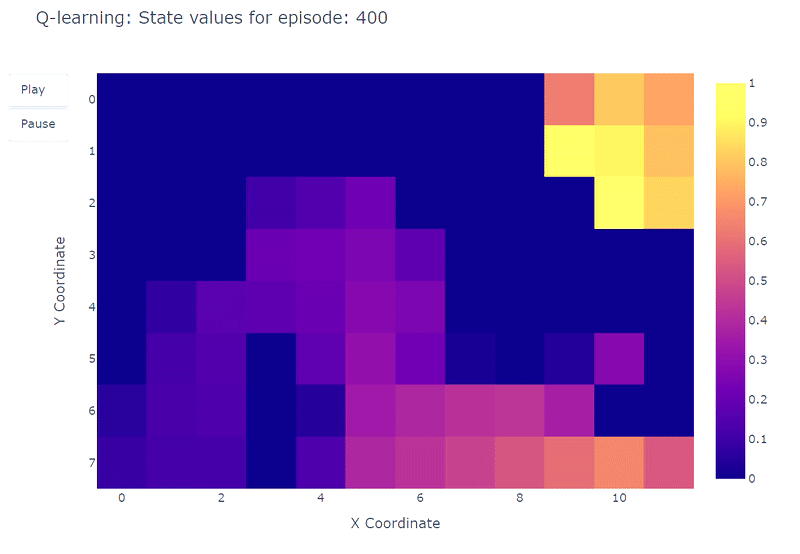
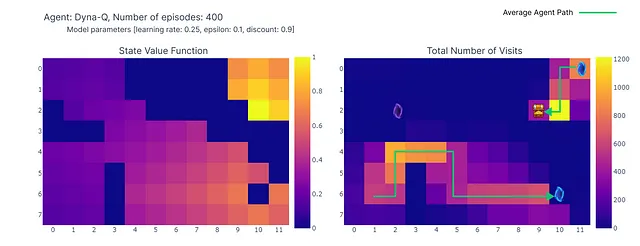
По окончании 400 эпизодов анализ общего количества посещений каждой ячейки дает нам приличную оценку среднего маршрута агента. Как показано на графике справа, агент, кажется, сходится к подоптимальному маршруту, избегая ячейку (4,4) и последовательно следуя нижней стене.
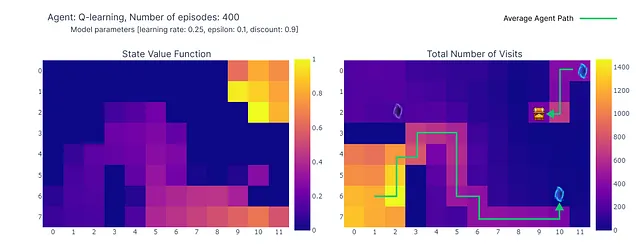
В результате этой подоптимальной стратегии агент достигает минимума в 21 шаге на эпизоде, следуя пути, обозначенному на графике “количество общих посещений”. Изменения в количестве шагов могут быть обусловлены политикой ε-жадности, которая вводит 10% вероятность случайных действий. Учитывая эту политику, следование нижней стене является приличной стратегией для ограничения возможных нарушений, вызванных случайными действиями.
В заключение, агент Q-обучения сошелся к подоптимальной стратегии, как упоминалось ранее. Более того, часть среды остается неисследованной функцией Q, что мешает агенту найти новый оптимальный путь, когда появляется фиолетовый портал после 100-го эпизода.
Эти ограничения производительности можно объяснить относительно небольшим количеством шагов обучения (400), ограничивающим возможности взаимодействия с окружающей средой и исследования, вызванного политикой ε-жадности.
Планирование, существенный компонент методов обучения с подкреплением на основе модели, особенно полезно для улучшения эффективности использования выборки и оценки значений действий. Дина-Кью и Дина-Кью+ являются хорошими примерами алгоритмов TD, включающих шаги планирования.
Дина-Кью
Алгоритм Дина-Кью (динамическое Q-обучение) является комбинацией обучения на основе модели и обучения TD.
Алгоритмы обучения на основе модели полагаются на модель окружающей среды для включения планирования в качестве основного способа обновления оценок значения. В отличие от них, алгоритмы обучения без модели полагаются на прямое обучение.
“Модель окружающей среды – это все, что агент может использовать для предсказания, как окружающая среда отреагирует на его действия” – Введение в обучение с подкреплением.
В рамках данной статьи модель может быть рассмотрена как приближение динамики перехода p(s’, r|s, a). Здесь p возвращает одну следующую пару состояние-вознаграждение при заданной текущей паре состояние-действие.
В средах, где p является стохастическим, мы разделяем модели распределения и модели выборки, первая возвращает распределение следующих состояний и действий, а вторая возвращает одну пару, выбранную из оцененного распределения.
Модели особенно полезны для моделирования эпизодов и, следовательно, обучения агента с заменой взаимодействий с реальной средой шагами планирования, т.е. взаимодействиями с симулируемой средой.
Агенты, реализующие алгоритм Дина-Кью, являются частью класса агентов планирования, агентов, комбинирующих прямое обучение с подкреплением и обучение модели. Они используют прямые взаимодействия с окружающей средой для обновления своей функции значения (как в Q-обучении), а также для изучения модели окружающей среды. После каждого прямого взаимодействия они также могут выполнять шаги планирования для обновления своей функции значения с использованием симулированных взаимодействий.
Быстрый пример шахматной игры
Представьте игру в шахматы. После каждого хода реакция вашего оппонента позволяет вам оценить качество вашего хода. Это похоже на получение положительного или отрицательного вознаграждения, которое позволяет вам “обновить” свою стратегию. Если ваш ход приводит к просчету, вы, вероятно, не повторите его, при условии, что доска остается в том же состоянии. Это сравнимо с прямым обучением с подкреплением.
Теперь добавим планирование в эту смесь. Представьте, что после каждого вашего хода, пока оппонент думает, вы ментально переходите к каждому из ваших предыдущих ходов, чтобы переоценить их качество. Вы можете обнаружить слабые места, которые вы пренебрегли на первый взгляд, или выяснить, что определенные ходы были лучше, чем вы думали. Эти размышления также позволяют вам обновить свою стратегию. Вот в чем суть планирования, обновление функции значения без взаимодействия с реальной средой, а скорее модели среды.

Таким образом, Дина-Кью содержит несколько дополнительных шагов по сравнению с Q-обучением:
После каждого прямого обновления значений Q модель сохраняет пару состояние-действие и наблюдаемое вознаграждение и следующее состояние. Этот шаг называется обучением модели.
- После обучения модели Дина-Кью выполняет n шагов планирования:
- Из буфера модели (т.е. эту пару состояние-действие наблюдали при прямых взаимодействиях) выбирается случайная пара состояние-действие
- Модель генерирует симулированное вознаграждение и следующее состояние
- Функция значения обновляется с использованием симулированных наблюдений (s, a, r, s’)

Теперь мы повторяем процесс обучения с использованием алгоритма Dyna-Q с параметром n=100. Это означает, что после каждого непосредственного взаимодействия с окружающей средой мы используем модель для выполнения 100 планировочных шагов (т.е. обновлений).
Следующая тепловая карта показывает быструю сходимость модели Dyna-Q. Фактически, алгоритму требуется всего около 10 эпизодов, чтобы найти оптимальный путь. Это происходит потому, что каждый шаг приводит к 101 обновлению значений Q (вместо 1 для Q-обучения).
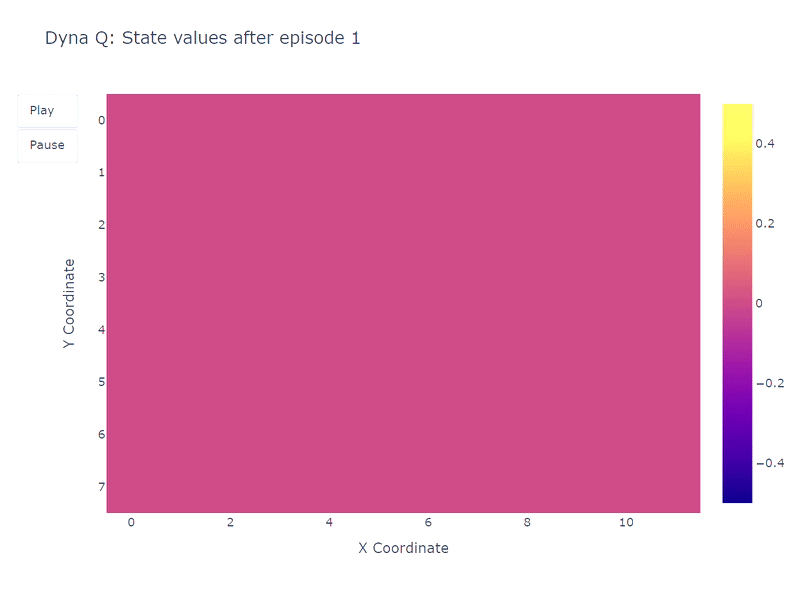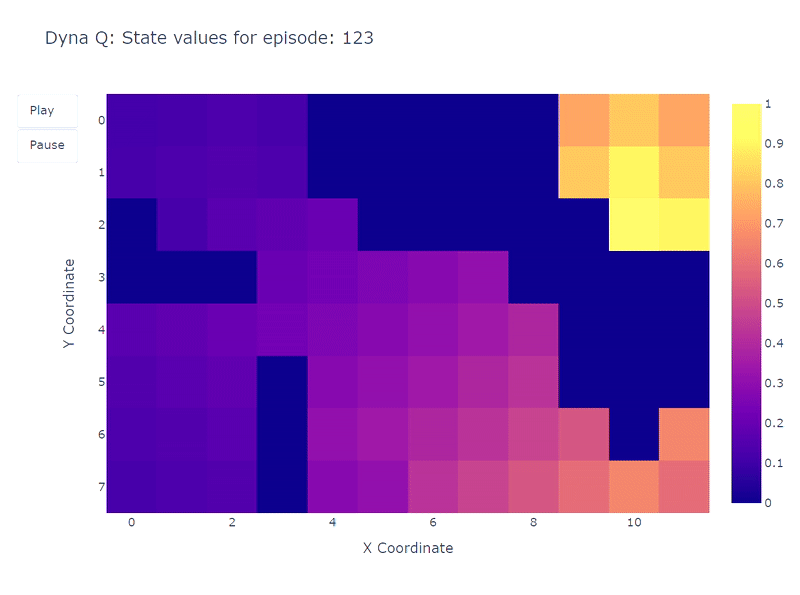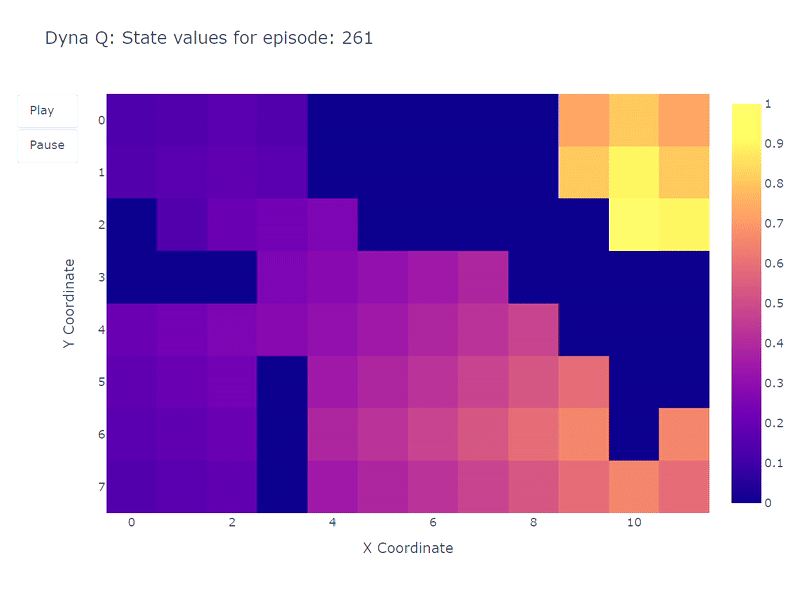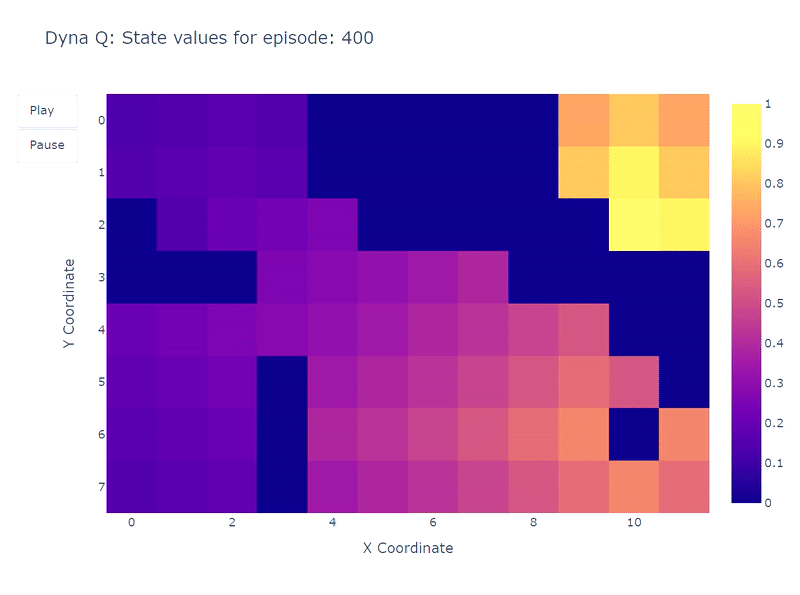
Еще одним преимуществом планировочных шагов является лучшая оценка значений действий на всей сетке. Поскольку косвенные обновления направлены на случайные переходы, сохраненные внутри модели, обновляются также состояния, находящиеся далеко от цели.
В отличие от этого, значения действий медленно распространяются от цели при Q-обучении, что приводит к неполному отображению сетки.
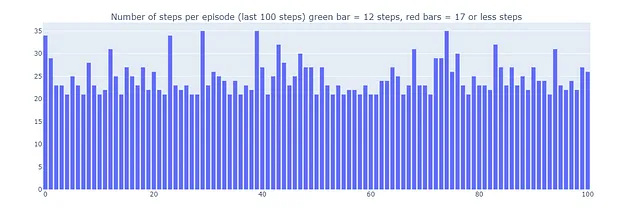
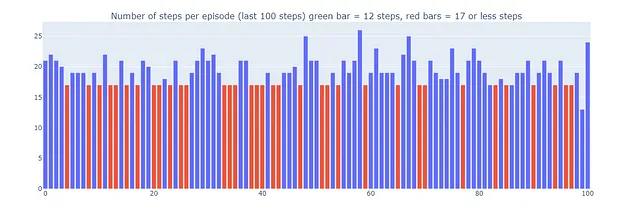
Используя Dyna-Q, мы находим оптимальный путь, позволяющий решить задачу в сетке за 17 шагов, как показано на графике красными столбцами. Оптимальные результаты достигаются регулярно, несмотря на случайные ε-жадные действия в целях исследования.
Наконец, хотя Dyna-Q может показаться более убедительным, чем Q-обучение из-за введения планирования, важно помнить, что планирование вносит компромисс между вычислительными затратами и исследованием реального мира.
Dyna-Q+
До сих пор ни один из протестированных алгоритмов не смог найти оптимальный путь, появляющийся после 100-го шага (фиолетовый портал). Действительно, оба алгоритма быстро сходились к оптимальному решению, которое оставалось неизменным до конца фазы обучения. Это подчеркивает необходимость продолжительного исследования на протяжении всего обучения.
Dyna-Q+ по большей части похож на Dyna-Q, но добавляет небольшой поворот в алгоритм. Действительно, Dyna-Q+ постоянно отслеживает количество временных шагов, прошедших с момента последней попытки каждой пары состояние-действие в реальном взаимодействии с окружающей средой.
В частности, рассмотрим переход, приводящий к награде r, который не был протестирован в течение τ временных шагов. Dyna-Q+ будет выполнять планировочные шаги, как если бы награда за этот переход была r + κ √τ, где κ достаточно маленький (0.001 в эксперименте).
Это изменение в конструкции награды побуждает агента постоянно исследовать окружающую среду. Оно предполагает, что чем дольше пара состояние-действие не была протестирована, тем больше вероятность того, что динамика этой пары изменилась или что модель неправильна.

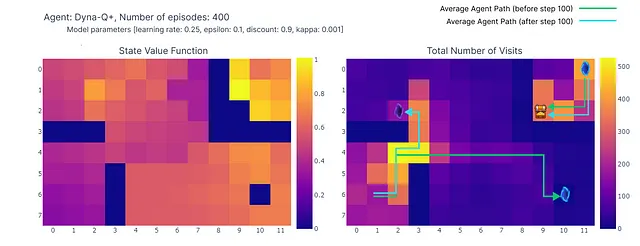
Как показано на следующем тепловом графике, алгоритм Dyna-Q+ намного активнее обновляет свои значения по сравнению с предыдущими алгоритмами. До эпизода 100 агент исследует всю сетку и находит синий портал и первый оптимальный маршрут.
Значения действий для остальной сетки уменьшаются, а затем медленно увеличиваются, так как пары состояний-действий в верхнем левом углу не исследуются некоторое время.
Как только в эпизоде 100 появляется фиолетовый портал, агент находит новый короткий путь, и значение для всей области повышается. До завершения 400 эпизодов агент будет непрерывно обновлять значение действия для каждой пары состояние-действие, сохраняя при этом случайное исследование сетки.
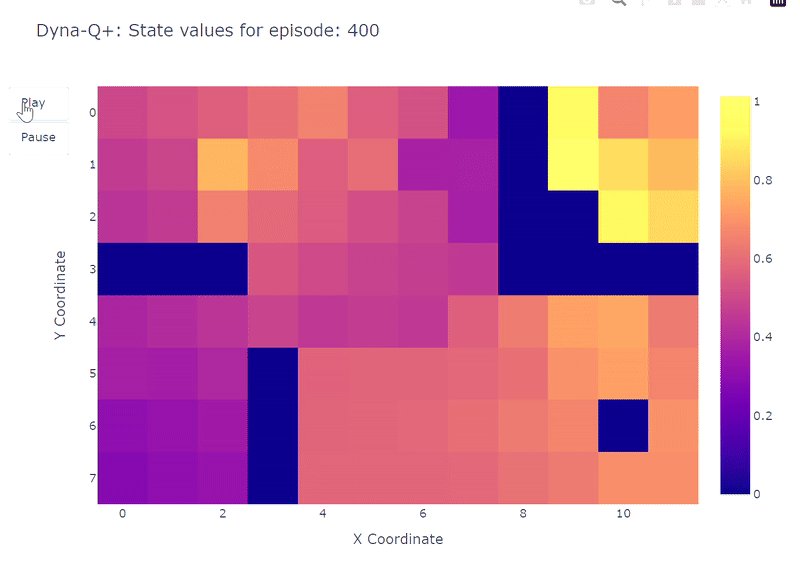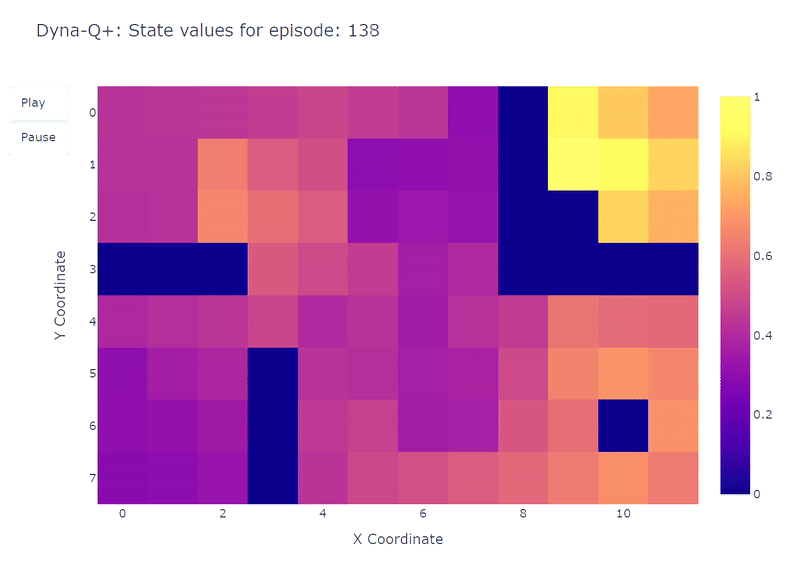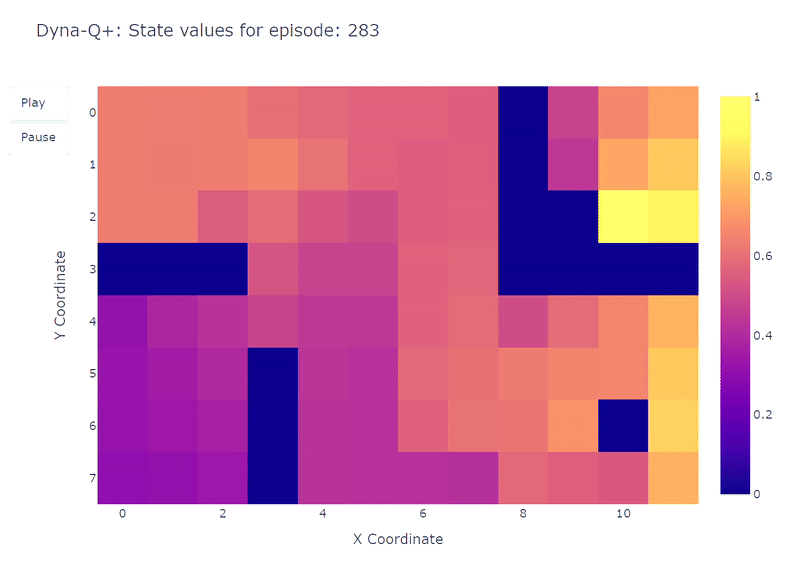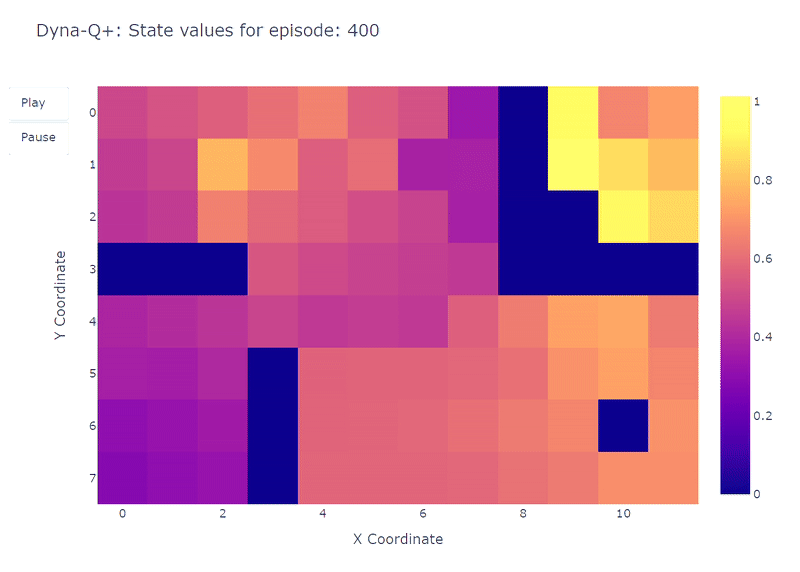
Благодаря бонусу, добавленному к вознаграждению модели, нам наконец удалось получить полное отображение функции Q (каждому состоянию или ячейке соответствует значение действия).
В сочетании с непрерывным исследованием агенту удается найти новый лучший маршрут (т.е. оптимальную стратегию), появившийся, сохраняя при этом предыдущее решение.
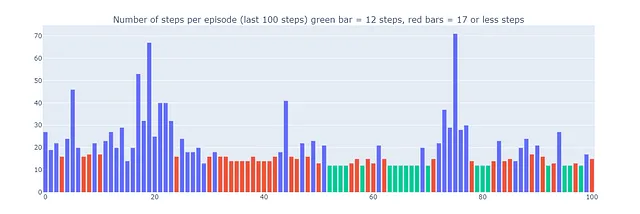
Однако компромисс между исследованием и использованием в Dyna-Q+ действительно имеет свою цену. Когда пары состояние-действие не были посещены в течение достаточного времени, бонус за исследование побуждает агента посещать эти состояния снова, что может временно ухудшить его немедленную производительность. Это исследовательское поведение приоритетно обновляет модель, чтобы улучшить принятие долгосрочных решений.
Это объясняет, почему некоторые эпизоды, сыгранные с помощью Dyna-Q+, могут состоять из 70 шагов, в то время как для Q-обучения и Dyna-Q максимальное количество шагов составляет 35 и 25 соответственно. Более длительные эпизоды в Dyna-Q+ отражают готовность агента вложить дополнительные шаги в исследование, чтобы собрать больше информации о среде и усовершенствовать свою модель, даже если это приводит к временному снижению производительности.
В отличие от этого, Dyna-Q+ регулярно достигает оптимальной производительности (показано зелеными столбцами на графике ниже), которую предыдущие алгоритмы не достигали.
Сводка и сравнение алгоритмов
Чтобы сравнить основные различия между алгоритмами, мы используем две метрики (имейте в виду, что результаты зависят от входных параметров, которые были идентичны для всех моделей для упрощения):
- Количество шагов в эпизоде: эта метрика характеризует скорость сходимости алгоритмов к оптимальному решению. Она также описывает поведение алгоритма после сходимости, особенно с точки зрения исследования.
- Среднее накопительное вознаграждение: процент эпизодов, приводящих к положительному вознаграждению
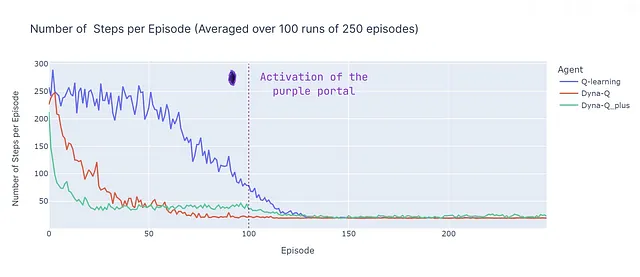
Анализ количества шагов в эпизоде (см. график ниже) раскрывает несколько аспектов модельных и бесмодельных методов:
- Эффективность моделей: Модельные алгоритмы (Dyna-Q и Dyna-Q+) обычно более эффективны по количеству образцов в этой конкретной сетке (это свойство также наблюдается более общим образом в RL). Это происходит потому, что они могут планировать заранее, используя изученную модель среды, что может привести к более быстрой сходимости к почти оптимальным или оптимальным решениям.
- Сходимость Q-обучения: Q-обучение, хотя и в конечном итоге сходится к почти оптимальному решению, требует большего количества эпизодов (125) для этого. Важно подчеркнуть, что Q-обучение выполняет только 1 обновление на шаг, что противоречит множественным обновлениям, выполняемым Dyna-Q и Dyna-Q+.
- Множественные обновления: Dyna-Q и Dyna-Q+ выполняют 101 обновление на шаг, что способствует их более быстрой сходимости. Однако компромиссом за эту эффективность по количеству образцов является вычислительная сложность (см. раздел времени выполнения в таблице ниже).
- Сложные среды: В более сложных или стохастических средах преимущество модельных методов может уменьшиться. Модели могут содержать ошибки или неточности, что может привести к субоптимальным стратегиям. Поэтому это сравнение следует рассматривать как обзор преимуществ и недостатков разных подходов, а не как прямое сравнение производительности.
Теперь мы представляем среднюю накопленную награду (ACR), которая представляет собой процент эпизодов, в которых агент достигает цели (поскольку награда равна 1 при достижении цели и 0 при активации ловушки), ACR вычисляется следующим образом:
Где N – количество эпизодов (250), K – количество независимых запусков (100), а Rn, k – накопленная награда для эпизода n в запуске k.
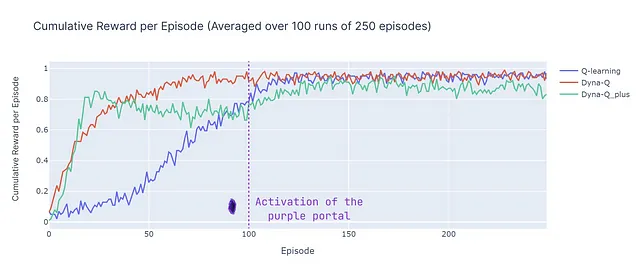
Вот разбивка производительности всех алгоритмов:
- Dyna-Q быстро сходится и достигает наивысшего общего результата с ACR 87%. Это означает, что он эффективно учится и достигает цели в значительной части эпизодов.
- Q-learning также достигает сходного уровня производительности, но требует большего количества эпизодов для сходимости, что объясняет его немного более низкий ACR – 70%.
- Dyna-Q+ быстро находит хорошую стратегию, достигая накопленной награды 0.8 уже после 15 эпизодов. Однако изменчивость и исследование, вызванные бонусной наградой, снижают производительность до 100-го шага. После 100 шагов он начинает улучшаться, открывая новый оптимальный путь. Однако краткосрочное исследование подрывает его производительность, что приводит к ACR 79%, что ниже, чем у Dyna-Q, но выше, чем у Q-learning.
Вывод
В этой статье мы представили основные принципы обучения методом временной разности и применили Q-learning, Dyna-Q и Dyna-Q+ к пользовательскому сетке-миру. Дизайн этого сетке-мира помогает подчеркнуть важность непрерывного исследования как способа обнаружения и использования новых оптимальных стратегий в изменяющихся средах. Различия в производительности (оцениваемой по количеству шагов в эпизоде и накопленной награде) иллюстрируют сильные и слабые стороны этих алгоритмов.
В заключение, методы, основанные на модели (Dyna-Q, Dyna-Q+), имеют преимущество в увеличении эффективности использования выборки по сравнению с методами, основанными на модели (Q-learning), за счет эффективности вычислений. Однако в стохастических или более сложных средах неточности модели могут снижать производительность и приводить к субоптимальным стратегиям.

Литература:
[1] Демис Хассабис, AlphaFold раскрывает структуру вселенной белков (2022), DeepMind
[2] Элиа Кауфманн, Леонард Бауэрсфельд, Антонио Локерчио, Матиас Мюллер, Владлен Колтун и Давиде Скарамуцца, Дрон-гонки на чемпионском уровне с использованием глубинного обучения с подкреплением (2023), Nature
[3] Натан Ламберт, Луис Кастрикато, Леандро фон Верра, Алекс Хаврилла, Иллюстрация обучения с подкреплением от обратной связи человека (RLHF), HuggingFace
[4] Саттон, Р. С., и Барто, А. Г. . Обучение с подкреплением: Введение (2018), Кембридж (Масс.): The MIT Press.
[5] Кристофер Дж. С. Х. Уоткинс и Питер Даян, Q-learning (1992), Machine Learning, Springer Link