Как United Airlines создала эффективную по стоимости трубопровод активного обучения оптического распознавания символов
United Airlines создала эффективный по стоимости трубопровод обучения распознаванию символов.
В этом посте мы рассмотрим, как United Airlines совместно с Amazon Machine Learning Solutions Lab создали фреймворк активного обучения на AWS для автоматизации обработки пассажирских документов.
“Для того чтобы обеспечить лучший опыт полета для наших пассажиров и сделать наш внутренний бизнес-процесс максимально эффективным, мы разработали автоматизированный конвейер обработки документов на основе машинного обучения в AWS. Для работы с этими приложениями, а также с приложениями, использующими другие модальности данных, такие как компьютерное зрение, нам необходим эффективный рабочий процесс для быстрой разметки данных, обучения и оценки моделей, а также быстрой итерации. За несколько месяцев United сотрудничал с лабораторией Amazon Machine Learning Solutions для разработки многоразового, независимого от конкретного случая использования рабочего процесса активного обучения с использованием AWS CDK. Этот рабочий процесс будет основополагающим для наших приложений машинного обучения на основе неструктурированных данных, поскольку он позволит нам минимизировать усилия по разметке человеком, быстро достигать высокой производительности моделей и адаптироваться к изменениям данных.”
– Джон Нельсон, старший менеджер по науке о данных и машинному обучению в United Airlines.
Проблема
Команда по цифровым технологиям United состоит из разнообразных специалистов, работающих совместно с передовыми технологиями для достижения бизнес-результатов и поддержания высокого уровня удовлетворенности клиентов. Они хотели использовать методы машинного обучения, такие как компьютерное зрение и обработка естественного языка, для автоматизации конвейеров обработки документов. В рамках этой стратегии они разработали модель анализа паспортов для проверки идентификационных данных пассажиров. В процессе обучения моделей машинного обучения требуется ручная разметка данных, что является очень дорогостоящим.
- Генеральный директор NVIDIA Дженсон Хуанг станет главным говорящим на AI-саммите в Тель-Авиве
- Может ли искусственный интеллект превзойти человека в творческой задаче мышления? Это исследование предоставляет понимание взаимоотношения между творчеством человека и машинным обучением.
- Исследование пересечения ИИ и блокчейна возможности и вызовы
United хотел создать гибкую, надежную и эффективную систему машинного обучения для автоматизации верификации паспортной информации, проверки подлинности удостоверений личности пассажиров и выявления возможных фальшивых документов. Они обратились в ML Solutions Lab за помощью в достижении этой цели, что позволяет United продолжать предоставлять услуги мирового класса в условиях роста пассажиропотока.
Обзор решения
Наша совместная команда разработала фреймворк активного обучения, основанный на AWS Cloud Development Kit (AWS CDK), который программно настраивает и предоставляет все необходимые службы AWS. Фреймворк использует Amazon SageMaker для обработки неразмеченных данных, создания мягких меток, запуска заданий ручной разметки с помощью Amazon SageMaker Ground Truth и обучения произвольной модели машинного обучения на основе полученного набора данных. Мы использовали Amazon Textract для автоматизации извлечения информации из определенных полей документов, таких как имя и номер паспорта. На высоком уровне подход можно описать следующей диаграммой.
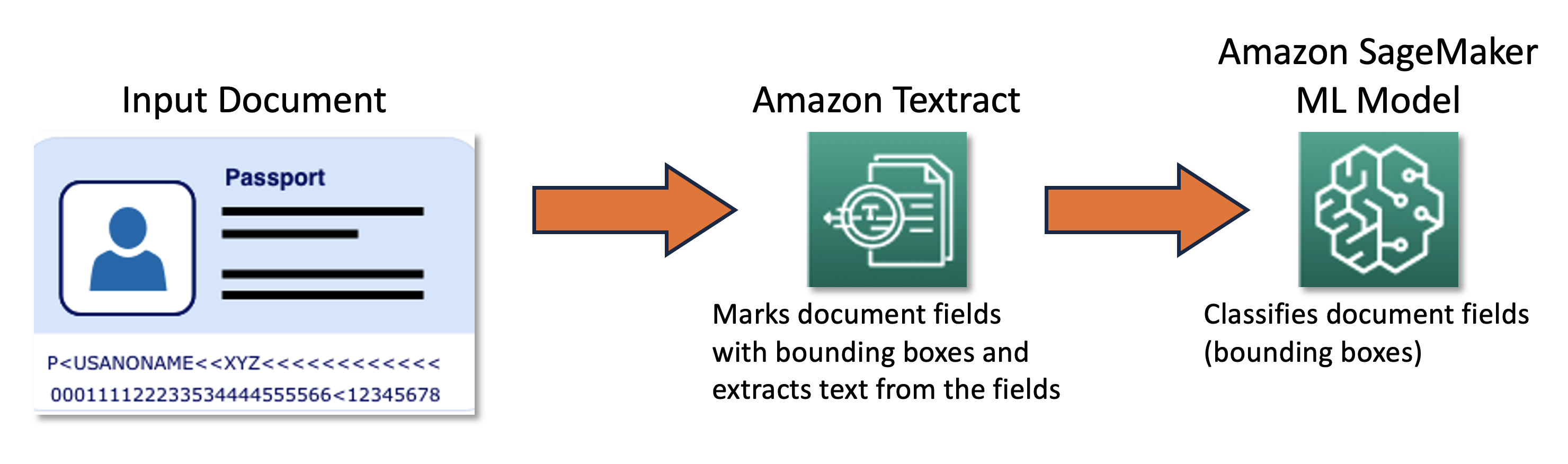
Данные
Основной набор данных для этой задачи состоит из десятков тысяч изображений паспортов, с которых необходимо извлечь личную информацию (имя, дата рождения, номер паспорта и т. д.). Размер, макет и структура изображений различаются в зависимости от страны, выдающей документ. Мы нормализуем эти изображения в набор однородных эскизов, которые составляют функциональный вход для конвейера активного обучения (автоматическая разметка и вывод).
Второй набор данных содержит файлы манифестов в формате JSON, которые связывают исходные изображения паспортов, эскизы и информацию о метках, таких как мягкие метки и позиции ограничивающих рамок. Файлы манифестов служат набором метаданных, хранящих результаты работы различных служб AWS в унифицированном формате и отделяют конвейер активного обучения от служб, используемых United. Следующая диаграмма иллюстрирует эту архитектуру.
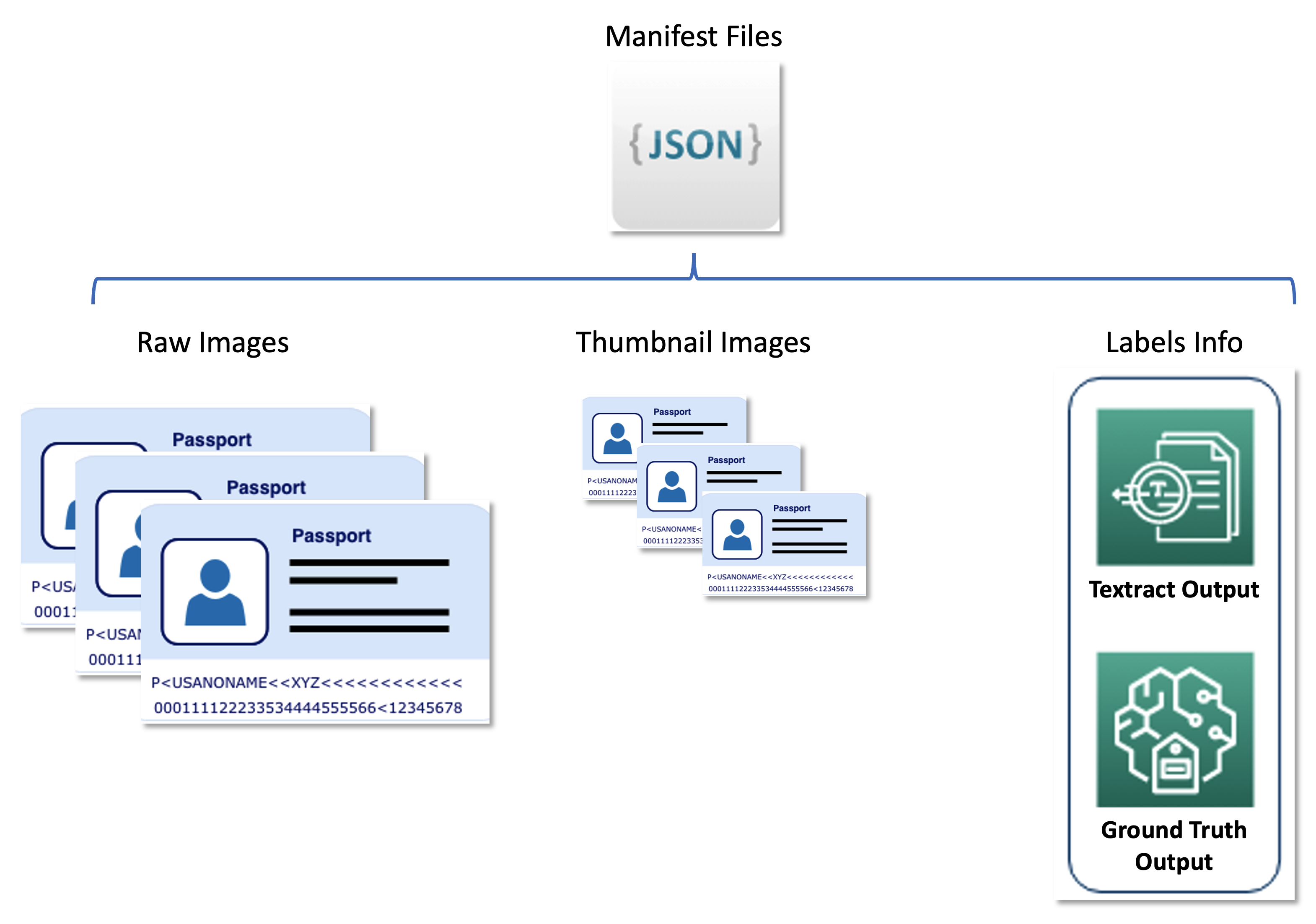
Следующий код представляет собой пример файла манифеста:
{
"raw-ref": "s3://bucket/passport-0.jpg",
"textract-ref": "s3://bucket/textract/passport-0.jpg",
"source-ref": "s3://bucket/clean-images/passport-0.jpg",
"page-num": 1,
"label": {
"image_size": [...],
"annotations": [
{
"class_id": 0,
"top": 1856,
"left": 1476,
"height": 67,
"width": 329
},
{"class_id": 1 ...},
{"class_id": 2 ...},
{"class_id": 3 ...},
{"class_id": 4 ...},
{"class_id": 5 ...},
{"class_id": 6 ...},
{"class_id": 7 ...},
{"class_id": 8 ...},
{"class_id": 9 ...},
{"class_id": 10 ...},
]
},
"label-metadata": {
"objects": [...],
"class-map ": {"0": "Номер паспорта" ...},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2022-09-19T00:58:55.729305",
"job-name": "labeling-job/passports-20220918-195035"
}
}Компоненты решения
Решение включает два основных компонента:
- ML-фреймворк, который отвечает за обучение модели
- Автоматизированный конвейер разметки, который отвечает за улучшение точности обученной модели в экономически эффективном режиме
ML-фреймворк отвечает за обучение модели машинного обучения и развертывание ее в виде конечной точки SageMaker. Автоматизированный конвейер разметки фокусируется на автоматизации задач SageMaker Ground Truth и выборке изображений для разметки через эти задачи.
Оба компонента разделены друг от друга и взаимодействуют только через набор размеченных изображений, созданных автоматизированным конвейером разметки. То есть, конвейер разметки создает метки, которые затем используются ML-фреймворком для обучения модели машинного обучения.
ML-фреймворк
Команда ML Solutions Lab разработала ML-фреймворк, используя реализацию Hugging Face модели LayoutLMV2 (LayoutLMv2: Многомодальное предварительное обучение для понимания документов с богатой визуальной информацией, Янг Су и др.). Обучение было основано на выводах Amazon Textract, которые служили предварительной обработкой и создавали ограничивающие рамки вокруг интересующего текста. Фреймворк использует распределенное обучение и запускается на пользовательском Docker-контейнере, основанном на предварительно созданном Docker-образе Hugging Face для SageMaker с дополнительными зависимостями (зависимостями, отсутствующими в предварительно созданном Docker-образе SageMaker, но требующими Hugging Face LayoutLMv2).
Модель машинного обучения была обучена для классификации полей документа в следующих 11 классах:
"0": "Номер паспорта",
"1": "Фамилия",
"2": "Имя",
"3": "Гражданство",
"4": "Дата рождения",
"5": "Место рождения",
"6": "Пол",
"7": "Дата выдачи",
"8": "Авторитет",
"9": "Дата истечения срока",
"10": "Ограничения"
Параметры предварительно созданного образа:
{
"фреймворк": "huggingface",
"версия": "4.17",
"базовая_версия_фреймворка": "pytorch1.10"
}Dockerfile пользовательского образа выглядит следующим образом: (BASE_IMAGE ссылается на предыдущий базовый образ):
ARG BASE_IMAGE
FROM ${BASE_IMAGE}
RUN pip install "amazon-textract-response-parser>=0.1,<0.2" "Pillow>=8,<9" \
&& pip install git+https://github.com/facebookresearch/detectron2.git
RUN pip install pytesseract "datasets==2.2.1" "torchvision>=0.11.3,<0.12"
RUN pip install setuptools==59.5.0Обучающий конвейер может быть представлен в следующей диаграмме.
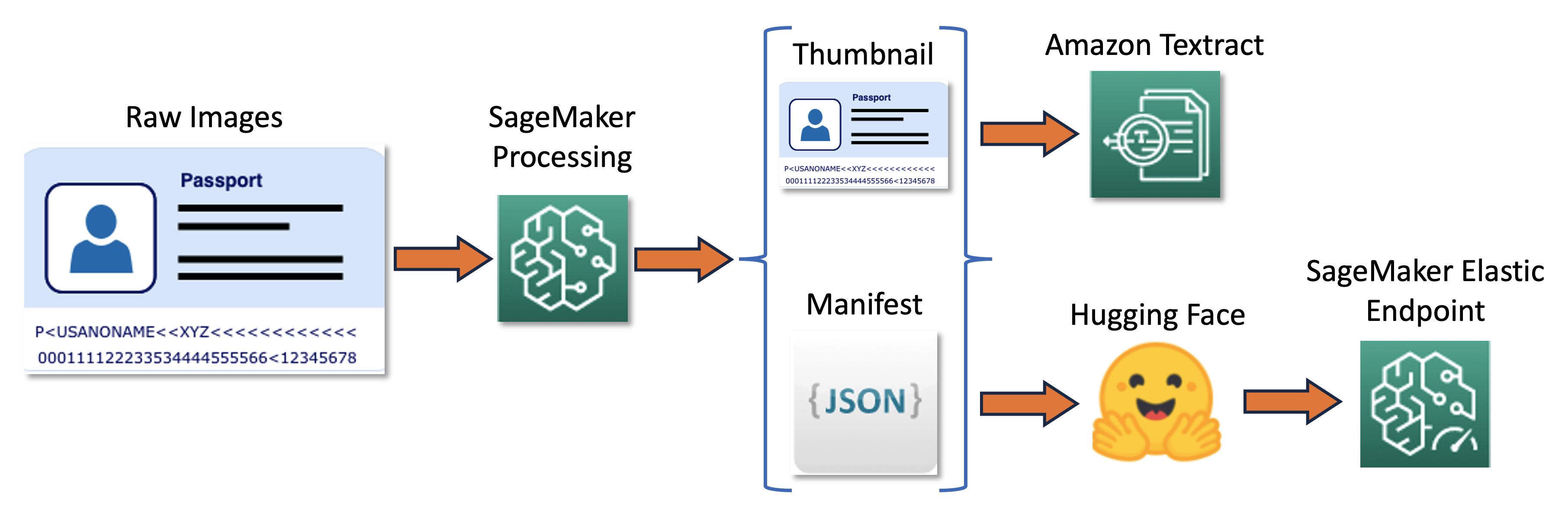
Сначала мы изменяем размер и нормализуем пакет сырых изображений до миниатюрного размера. В то же время создается JSON-файл манифеста с одной строкой на изображение, содержащей информацию о сырых и миниатюрных изображениях из пакета. Затем мы используем Amazon Textract для извлечения ограничивающих рамок текста на миниатюрных изображениях. Все информация, полученная с помощью Amazon Textract, записывается в тот же файл манифеста. Наконец, мы используем миниатюрные изображения и данные манифеста для обучения модели, которая позднее развертывается в виде конечной точки SageMaker.
Автоматизированный конвейер разметки
Мы разработали автоматизированный конвейер разметки, предназначенный для выполнения следующих функций:
- Выполнение периодической пакетной инференции на неразмеченном наборе данных.
- Фильтрация результатов на основе определенной стратегии выборки с наименьшей неопределенностью.
- Запуск задачи SageMaker Ground Truth для разметки выбранных изображений с помощью человеческого труда.
- Добавление новых размеченных изображений в обучающий набор данных для последующего уточнения модели.
Стратегия выборки с наименьшей неопределенностью сокращает количество изображений, отправляемых на задачу разметки человеком, выбирая изображения, которые, вероятно, больше всего способствуют улучшению точности модели. Поскольку разметка человеком является дорогостоящей задачей, такая выборка является важной техникой сокращения затрат. Мы поддерживаем четыре стратегии выборки, которые могут быть выбраны в качестве параметра, сохраненного в Parameter Store, возможности AWS Systems Manager:
- Наименьшая уверенность
- Уверенность отступа
- Соотношение уверенности
- Энтропия
Весь рабочий процесс автоматической разметки был реализован с помощью AWS Step Functions, которая оркестрирует задание обработки (называемое упругой конечной точкой для пакетной инференции), выборку с наименьшей неопределенностью и SageMaker Ground Truth. Следующая диаграмма иллюстрирует рабочий процесс Step Functions.

Экономичность
Основным фактором, влияющим на стоимость разметки, является ручная разметка. До внедрения этого решения команда United должна была использовать правила, требующие дорогостоящей ручной разметки данных и техники парсинга OCR от третьих сторон. С нашим решением United сократила объем ручной разметки, размечая только те изображения, которые приведут к наибольшим улучшениям модели. Поскольку фреймворк не привязан к конкретной модели, он может использоваться в других подобных сценариях, расширяя свою ценность за пределы паспортных фотографий на более широкий набор документов.
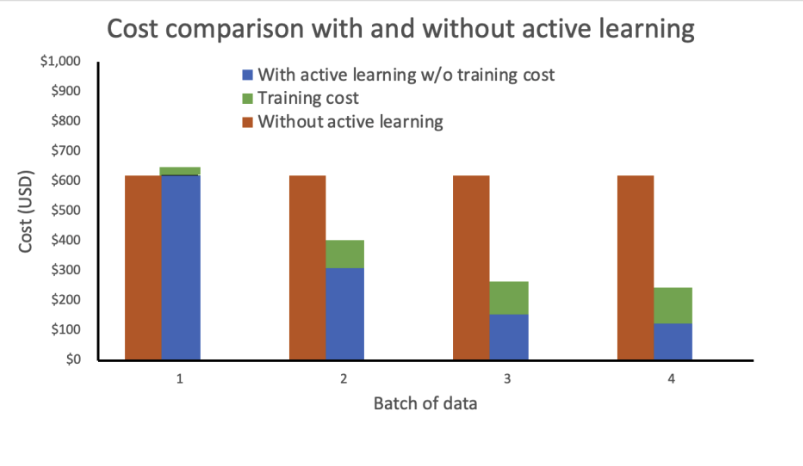
Мы провели анализ стоимости на основе следующих предположений:
- Каждая партия содержит 1000 изображений
- Обучение выполняется с использованием экземпляра mlg4dn.16xlarge
- Вывод выполняется на экземпляре mlg4dn.xlarge
- Обучение выполняется после каждой партии с использованием 10% размеченных меток
- Каждый раунд обучения приводит к следующим улучшениям точности:
- 50% после первой партии
- 25% после второй партии
- 10% после третьей партии
Наш анализ показывает, что стоимость обучения без активного обучения остается постоянной и высокой. Внедрение активного обучения приводит к экспоненциальному снижению затрат с каждой новой партией данных.
Мы также снизили затраты, развернув конечную точку вывода в виде масштабируемой конечной точки, добавив политику автоматического масштабирования. Ресурсы конечной точки могут масштабироваться вверх или вниз от нуля до настроенного максимального количества экземпляров.
Итоговая архитектура решения
Наши усилия были направлены на помощь команде United в достижении их функциональных требований при создании масштабируемого и гибкого облачного приложения. Команда ML Solutions Lab разработала полностью готовое к производству решение с помощью AWS CDK, автоматизируя управление и предоставление всех облачных ресурсов и сервисов. Конечное облачное приложение было развернуто в виде одного стека AWS CloudFormation с четырьмя вложенными стеками, каждый из которых представлял собой отдельный функциональный компонент.
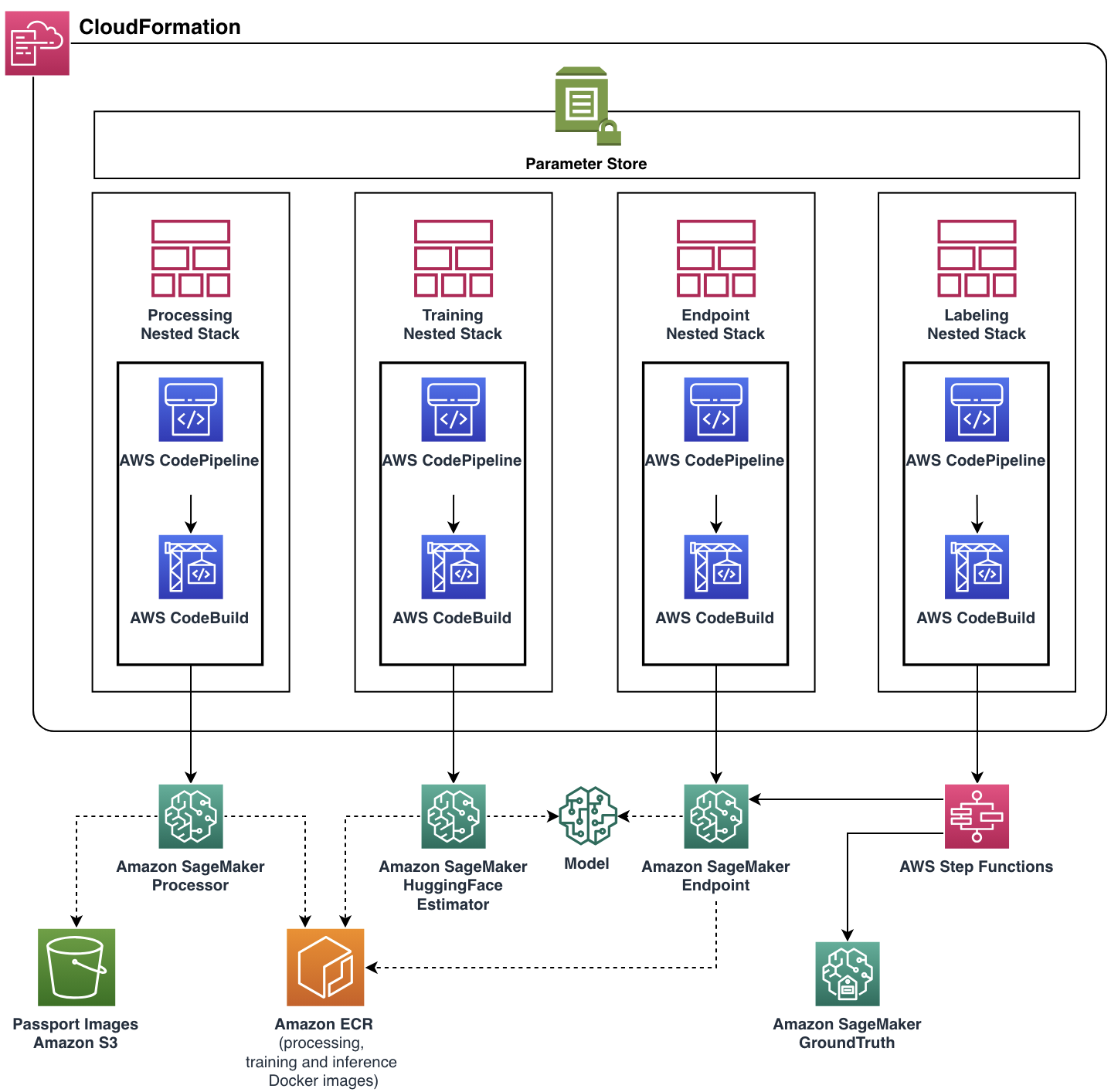
Почти каждая функция конвейера, включая Docker-образы, политику автоматического масштабирования конечной точки и другие, была параметризована через Parameter Store. Благодаря такой гибкости один и тот же экземпляр конвейера может запускаться с широким набором настроек, что добавляет возможность проведения экспериментов.
Вывод
В данной статье мы обсудили, как авиакомпания United Airlines совместно с командой ML Solutions Lab создала фреймворк активного обучения на AWS для автоматизации обработки пассажирских документов. Решение имело значительное влияние на два важных аспекта автоматизации United:
- Повторное использование – Благодаря модульному дизайну и реализации, не привязанной к конкретной модели, авиакомпания United может повторно использовать это решение практически в любом другом случае использования ML для автоматической разметки.
- Снижение регулярных затрат – Интеллектуальное сочетание процессов ручной и автоматической разметки позволяет команде United снизить средние затраты на разметку и заменить дорогостоящие услуги разметки от третьих сторон.
Если вас интересует внедрение подобного решения или вы хотите узнать больше о ML Solutions Lab, свяжитесь с вашим менеджером по контрактам или посетите нас на сайте Amazon Machine Learning Solutions Lab.





