Обзор нативно поддерживаемых схем квантования в 🤗 Transformers
Обзор схем квантования в 🤗 Transformers
Мы стремимся дать ясный обзор преимуществ и недостатков каждой схемы квантования, поддерживаемой в трансформерах, чтобы помочь вам решить, на какую схему вам следует остановиться.
В настоящее время модели квантования используются для двух основных целей:
- Выполнение вывода большой модели на меньшем устройстве
- Настраивание адаптеров поверх квантованных моделей
До сих пор было предпринято две попытки интеграции, которые естественным образом поддерживаются в трансформерах: bitsandbytes и auto-gptq. Обратите внимание, что в библиотеке оптимум 🤗 также поддерживаются некоторые дополнительные схемы квантования, но это выходит за рамки данного блогпоста.
Чтобы узнать больше о каждой поддерживаемой схеме, пожалуйста, ознакомьтесь с одним из ресурсов, указанных ниже. Пожалуйста, также обратите внимание на соответствующие разделы документации.
- Вариационные трансформаторы для композиции музыки Может ли искусственный интеллект заменить музыканта?
- Какие особенности вредны для вашей модели классификации?
- Неравенства Маркова и Бьене-Шебышева
Также обратите внимание, что указанные ниже детали являются действительными только для моделей PyTorch, это в настоящее время выходит за рамки моделей Tensorflow и Flax/JAX.
Содержание
- Ресурсы
- Преимущества и недостатки bitsandbyes и auto-gptq
- Загрузка скоростных тестов
- Заключение и итоговые слова
- Благодарности
Ресурсы
- Блогпост о GPTQ – дает обзор метода квантования GPTQ и как его использовать.
- Блогпост о 4-битовом квантовании bitsandbytes – В этом блогпосте представлено 4-битовое квантование и эффективный подход к донастройке QLoRa.
- Блогпост о 8-битовом квантовании bitsandbytes – В этом блогпосте объясняется, как работает 8-битовое квантование с использованием bitsandbytes.
- Базовый использование Google Colab для GPTQ – Этот ноутбук показывает, как квантовать вашу модель трансформера с помощью метода GPTQ, как выполнять вывод и как выполнять донастройку с квантованной моделью.
- Базовый использование Google Colab для bitsandbytes – Этот ноутбук показывает, как использовать 4-битовые модели при выводе со всеми их вариантами, и как выполнять запуск GPT-neo-X (модели с 20 миллиардами параметров) на бесплатном экземпляре Google Colab.
- Блогпост Мерве о квантовании – Этот блогпост предоставляет понятное введение в квантование и методы квантования, которые поддерживаются нативно в трансформерах.
Преимущества и недостатки bitsandbyes и auto-gptq
В этом разделе мы рассмотрим преимущества и недостатки квантования bitsandbytes и gptq. Обратите внимание, что они основаны на отзывах от сообщества и могут изменяться со временем, поскольку некоторые из этих функций находятся в планах соответствующих библиотек.
Преимущества bitsandbytes
Простота: bitsandbytes по-прежнему остается самым простым способом квантования любой модели, поскольку он не требует калибровки квантованной модели с помощью входных данных (также называемой квантованием с нулевым срабатыванием). Возможно квантование любой модели сразу из коробки, пока она содержит модули torch.nn.Linear. Всякий раз, когда в трансформерах добавляется новая архитектура, пока они могут быть загружены с помощью device_map=”auto” ускорения, пользователи могут воспользоваться квантованием bitsandbytes с минимальным снижением производительности. Квантование выполняется при загрузке модели, не требуется выполнять какие-либо постобработку или подготовительные шаги.
Взаимодействие между модальностями: Поскольку единственным условием для квантования модели является наличие слоя torch.nn.Linear, квантование работает из коробки для любой модальности, что позволяет загружать модели, такие как Whisper, ViT, Blip2 и т. д., в формате 8-битового или 4-битового квантования.
Отсутствие снижения производительности при объединении адаптеров: (Подробнее о адаптерах и PEFT можно прочитать в этом блогпосте, если вы не знакомы с ними). Если вы обучаете адаптеры поверх квантованной базовой модели, адаптеры могут быть объединены поверх базовой модели для развертывания без снижения производительности вывода. Вы также можете объединить адаптеры поверх деквантованной модели! Это не поддерживается для GPTQ.
Преимущества autoGPTQ
Быстро для генерации текста: Квантованные модели GPTQ быстрее, чем квантованные модели bitsandbytes, для генерации текста. Мы рассмотрим сравнение скорости в соответствующем разделе.
Поддержка n-битов: Алгоритм GPTQ позволяет квантовать модели до 2 бит! Однако это может привести к серьезному снижению качества. Рекомендуемое количество битов – 4, что является отличным компромиссом для GPTQ в настоящее время.
Легко сериализуемые: Модели GPTQ поддерживают сериализацию для любого количества битов. Загрузка моделей из пространства имен TheBloke: https://huggingface.co/TheBloke (ищите те, которые заканчиваются суффиксом -GPTQ) поддерживается из коробки, при условии, что у вас установлены необходимые пакеты. Bitsandbytes поддерживает сериализацию 8-бит, но на данный момент не поддерживает сериализацию 4-бит.
Поддержка AMD: Интеграция должна работать «из коробки» для графических процессоров AMD!
Недостатки bitsandbytes
Медленнее GPTQ при генерации текста: Модели bitsandbytes с 4-битными весами работают медленнее по сравнению с GPTQ при использовании generate.
4-битные веса не сериализуемы: В настоящее время 4-битные модели не могут быть сериализованы. Это часто запрашивается сообществом, и мы считаем, что это должно быть скоро решено разработчиками bitsandbytes, так как это входит в их планы!
Недостатки autoGPTQ
Калибровочный набор данных: Необходимость наличия калибровочного набора данных может отпугивать некоторых пользователей от использования GPTQ. Кроме того, процесс квантования модели может занимать несколько часов (например, 4 часа на 180B модель с использованием 4 графических процессоров)
Работает только для языковых моделей (пока что): На сегодняшний день API для квантования модели с авто-GPTQ был разработан для поддержки только языковых моделей. Возможно, квантование непростого текста (или мультимодальных) моделей с использованием алгоритма GPTQ возможно, но процесс не был подробно описан в оригинальной статье или в репозитории auto-gptq. Если сообщество заинтересовано в этой теме, это может быть рассмотрено в будущем.
Погружение в скоростные тесты
Мы решили предоставить обширный тест для инференса и адаптеров для тонкой настройки с использованием bitsandbytes и auto-gptq на разном оборудовании. Тест скорости инференса должен дать пользователям представление о разнице в скорости между разными подходами, которые мы предлагаем для инференса, а тест адаптера для тонкой настройки должен дать ясное представление пользователям о выборе подхода при настройке адаптеров на основе базовых моделей bitsandbytes и GPTQ.
Мы будем использовать следующую настройку:
- bitsandbytes: квантование 4 бита с
bnb_4bit_compute_dtype=torch.float16. Убедитесь, что используетеbitsandbytes>=0.41.1для быстрых 4-битных ядер. - auto-gptq: квантование 4 бита с ядрами exllama. Вам понадобится
auto-gptq>=0.4.0, чтобы использовать ядра ex-llama.
Скорость инференса (только прямой проход)
Этот тест измеряет только шаг предварительного заполнения, который соответствует прямому проходу во время обучения. Он был запущен на одном графическом процессоре NVIDIA A100-SXM4-80GB с длиной промпта 512. Модель, которую мы использовали, была meta-llama/Llama-2-13b-hf.
с размером пакета = 1:
с размером пакета = 16:
Из результатов теста мы видим, что bitsandbytes и GPTQ эквивалентны, при этом GPTQ немного быстрее для большого размера пакета. Чтобы получить более подробные сведения об этих тестах, перейдите по этой ссылке.
Скорость генерации
Следующие тесты измеряют скорость генерации модели во время инференса. Скрипт для проведения тестов можно найти здесь для воспроизводимости.
use_cache
Давайте протестируем use_cache, чтобы лучше понять влияние кэширования скрытого состояния во время генерации.
Тест был запущен на A100 с длиной промпта 30, и мы сгенерировали ровно 30 токенов. Модель, которую мы использовали, была meta-llama/Llama-2-7b-hf.
с use_cache=True
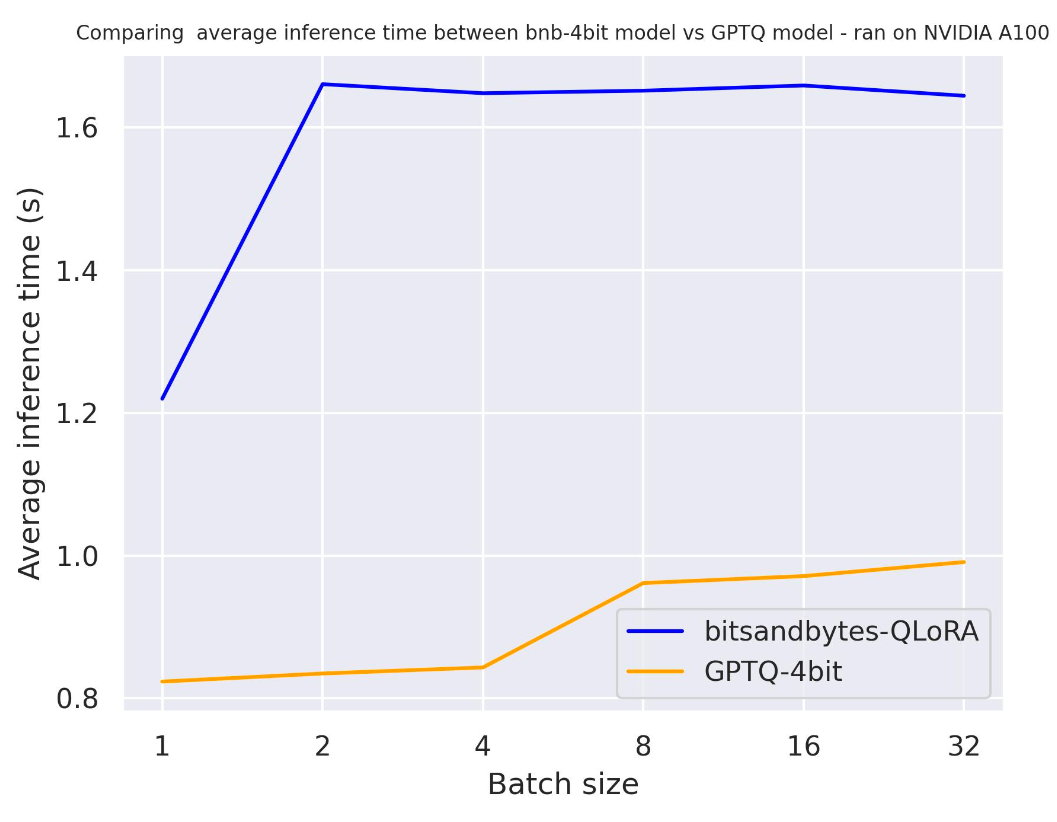
с use_cache=False
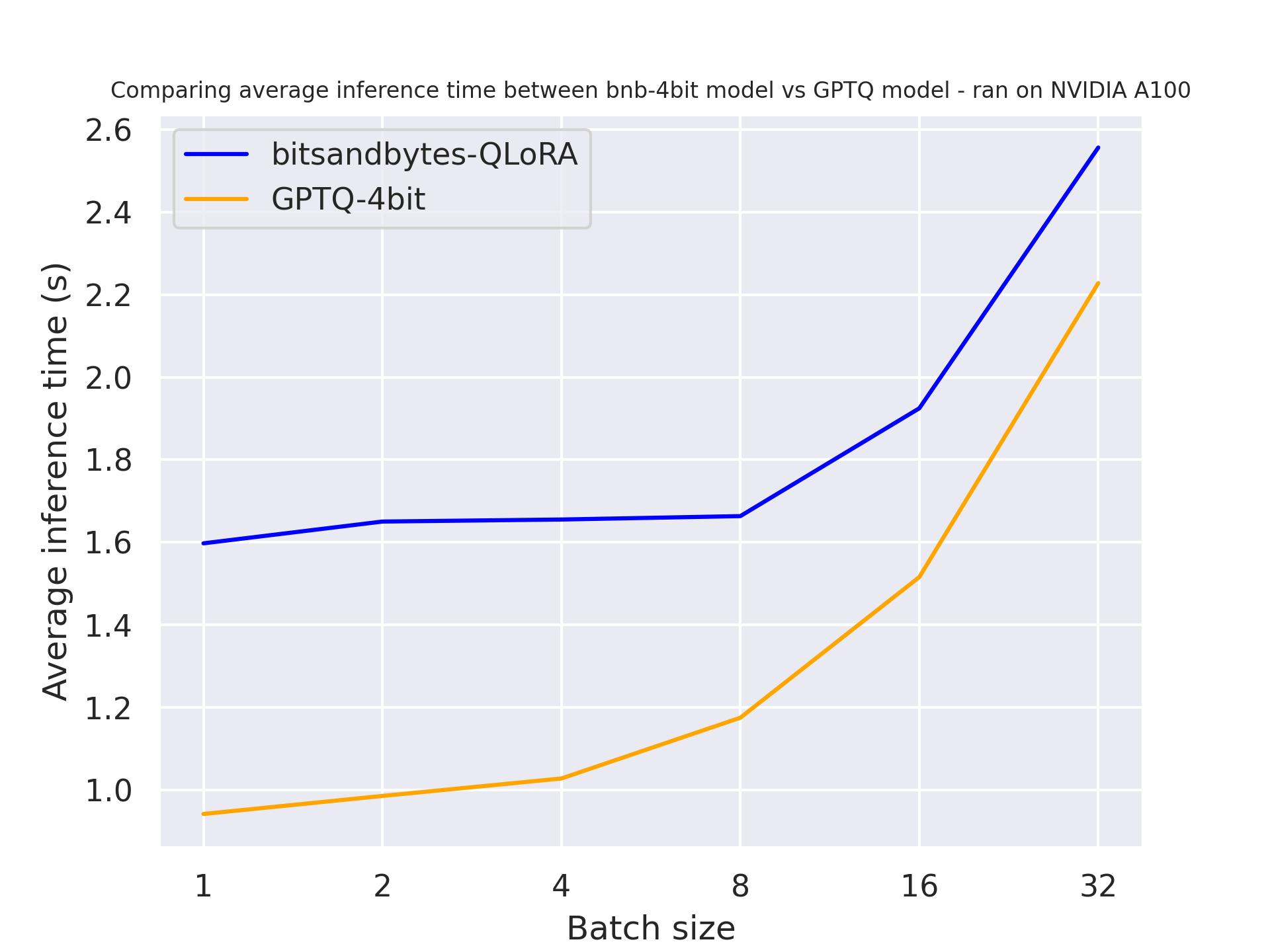
Из двух результатов тестирования мы приходим к выводу, что генерация происходит быстрее при использовании кэширования внимания, как и ожидалось. Кроме того, GPTQ, в целом, быстрее, чем bitsandbytes. Например, при batch_size=4 и use_cache=True, он в два раза быстрее! Поэтому давайте использовать use_cache для следующих тестовых наборов. Обратите внимание, что использование use_cache потребляет больше памяти.
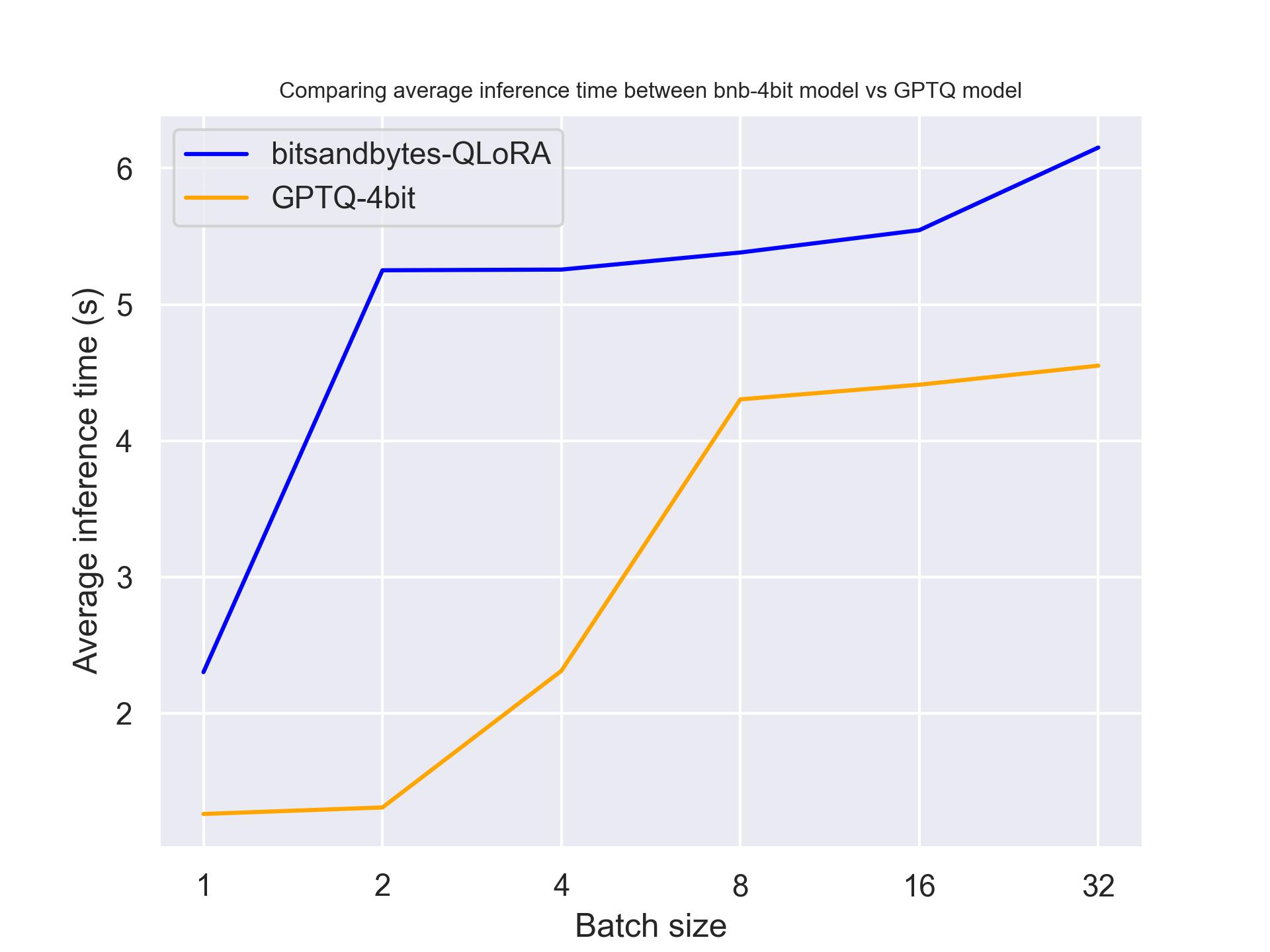
Аппаратное обеспечение
В следующем тесте мы попробуем разное аппаратное обеспечение, чтобы увидеть его влияние на квантованную модель. Мы использовали длину запроса 30 и сгенерировали ровно 30 токенов. Модель, которую мы использовали, была meta-llama/Llama-2-7b-hf.
с использованием NVIDIA A100:
с использованием NVIDIA T4:
с использованием Titan RTX:
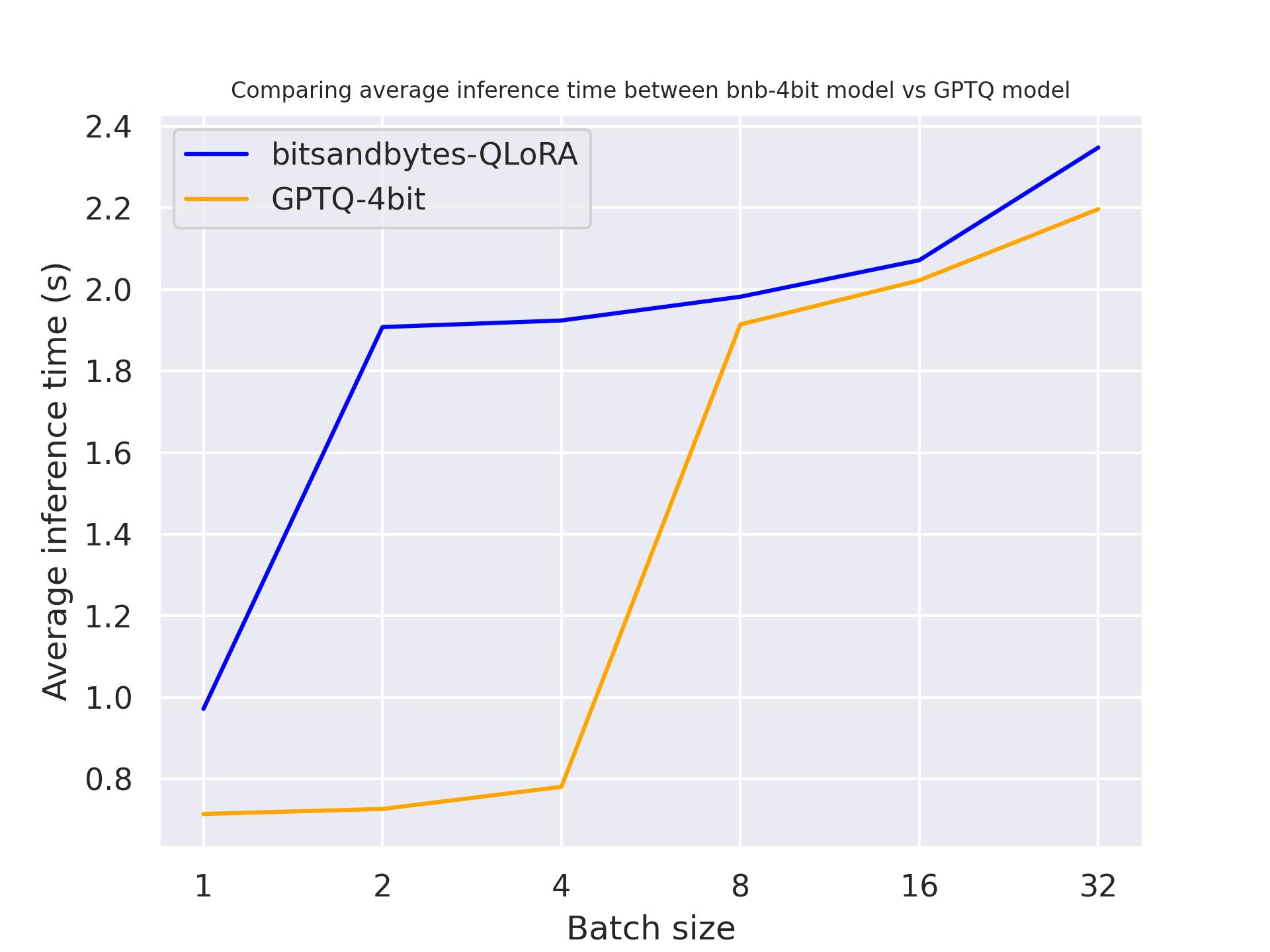
Из результатов тестирования выше мы можем сделать вывод, что GPTQ быстрее, чем bitsandbytes для этих трех графических процессоров.
Длина генерации
В следующем тесте мы попробуем разную длину генерации, чтобы увидеть их влияние на квантованную модель. Тест был выполнен на A100, мы использовали длину запроса 30 и варьировали количество сгенерированных токенов. Модель, которую мы использовали, была meta-llama/Llama-2-7b-hf.
сгенерировано 30 токенов:
сгенерировано 512 токенов:
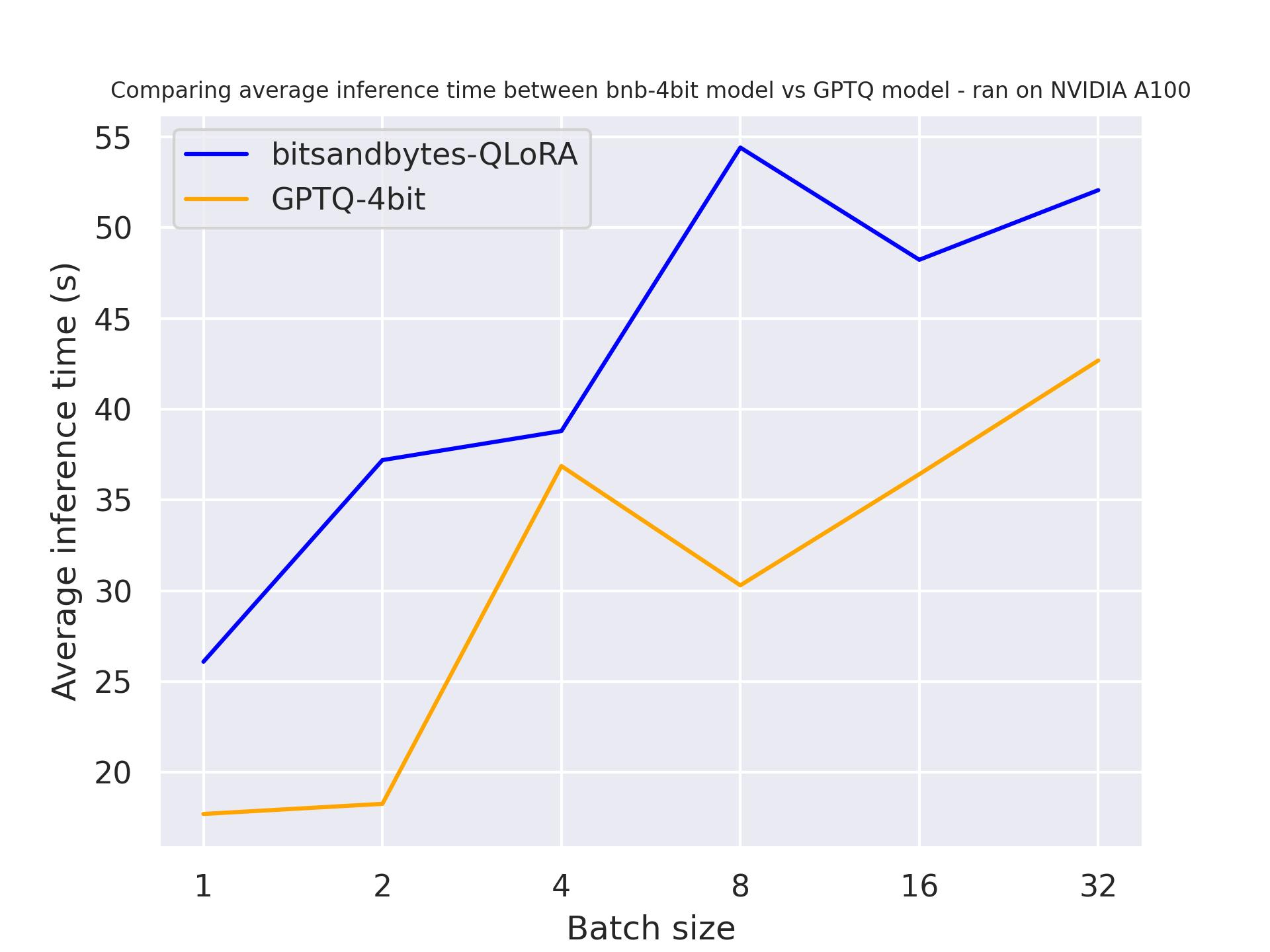
Из результатов тестирования выше мы можем сделать вывод, что GPTQ быстрее, чем bitsandbytes независимо от длины генерации.
Настройка адаптера (прямой + обратный проход)
Невозможно выполнять чистую тренировку на квантованной модели. Однако вы можете настраивать квантованные модели, используя эффективные методы тренировки с параметром (PEFT) и тренировать адаптеры поверх них. Метод настройки будет основан на недавнем методе под названием “Low Rank Adapters” (LoRA): вместо настройки всей модели вам нужно только настроить эти адаптеры и правильно загрузить их внутрь модели. Давайте сравним скорость настройки!
Тестирование было выполнено на графическом процессоре NVIDIA A100, и мы использовали модель meta-llama/Llama-2-7b-hf из Hub. Обратите внимание, что для модели GPTQ мы должны отключить ядра exllama, так как они не поддерживаются для настройки.
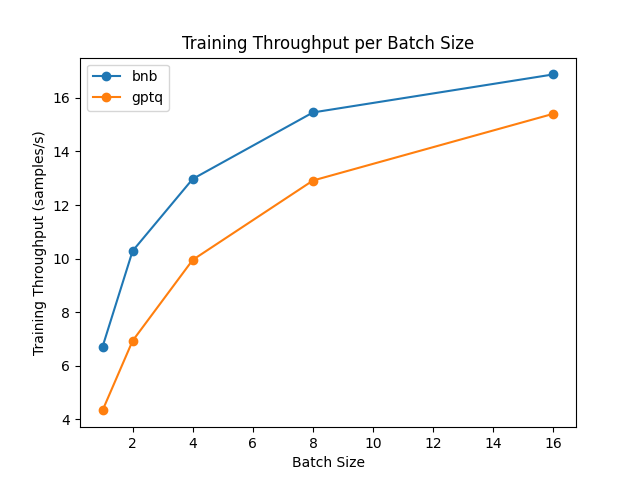
Из результатов мы приходим к выводу, что bitsandbytes быстрее, чем GPTQ, для настройки.
Снижение производительности
Квантование отлично подходит для снижения использования памяти. Однако, это сопряжено с снижением производительности. Давайте сравним производительность с использованием рейтинга Open-LLM!
с 7b моделью:
с 13b моделью:
Из полученных выше результатов мы приходим к выводу, что у больших моделей происходит меньшее ухудшение. Интересно, что ухудшение минимально!
Заключение и окончательные слова
В этом блогпосте мы сравнили квантование bitsandbytes и GPTQ в нескольких настройках. Мы видели, что bitsandbytes лучше подходит для тонкой настройки, в то время как GPTQ лучше подходит для генерации. Исходя из этого наблюдения, одним из способов получить лучшие объединенные модели будет:
- (1) квантовать базовую модель с использованием bitsandbytes (квантование без обучения)
- (2) добавить и настроить адаптеры
- (3) объединить обученные адаптеры поверх базовой модели или деквантованной модели !
- (4) квантовать объединенную модель с использованием GPTQ и использовать ее для развертывания
Мы надеемся, что этот обзор сделает использование языковых моделей более простым для всех ваших приложений и случаев использования, и с нетерпением ждем, чему вы научитесь с их помощью!
Благодарности
Мы хотели бы поблагодарить Ильяса, Клементину и Феликса за их помощь в проведении бенчмаркинга.
Наконец, мы хотели бы поблагодарить Педро Куенку за его помощь в написании этого блогпоста.






