Разместите сотни моделей NLP, используя многофункциональные точки доступа SageMaker, поддерживаемые GPU-экземплярами.
Разместите много моделей NLP с помощью SageMaker, используя GPU-экземпляры.
Интеграция Triton Inference Server с Amazon SageMaker
В прошлом мы исследовали многофункциональные модельные конечные точки SageMaker (MME) как экономически эффективный вариант для размещения нескольких моделей за одной конечной точкой. В то время как размещение небольших моделей возможно на MME с использованием экземпляров на основе ЦП, по мере увеличения размера и сложности этих моделей иногда может потребоваться использование вычислений на графическом процессоре.
ММЕ, основанные на графическом процессоре, являются специфической функцией инференции SageMaker, которую мы будем использовать в этой статье, чтобы показать, как мы можем эффективно размещать сотни моделей NLP на одной конечной точке. Обратите внимание, что на момент написания этой статьи MME GPU на SageMaker поддерживает следующие семейства экземпляров на основе одного графического процессора: p2, p3, g4dn и g5.
MME GPU в настоящее время также использует две стеки обслуживания моделей:
- Nvidia Triton Inference Server
- TorchServe
Для целей этой статьи мы будем использовать Triton Inference Server с бэкэндом PyTorch для размещения моделей на основе BERT на нашем графическом процессоре. Если вы новичок в Triton, мы предоставим небольшое введение, но я рекомендую ознакомиться с моей стартовой статьей здесь.
- Расходы на искусственный интеллект выросли более чем на 80%, показывает отчет ABBYY о состоянии интеллектуальной автоматизации.
- ИИ для всех ориентирование в новой эпохе демократизированного интеллекта
- Два новых доклада подробно анализируют вселенную белков, раскрытую 200 миллионами моделей AlphaFold 2
ПРИМЕЧАНИЕ: В этой статье предполагается средний уровень понимания развертывания SageMaker и инференции в режиме реального времени. Я рекомендую прочитать эту статью для более глубокого понимания развертывания/инференции. Мы также рассмотрим многофункциональные модельные конечные точки, но для более подробной информации обратитесь к этой документации.
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: Я являюсь архитектором машинного обучения в AWS, и мои мнения выражают только мое личное мнение.
Что такое MME? Обзор решения
Зачем нужны многофункциональные модельные конечные точки и когда их следует использовать? MME является экономически эффективным вариантом размещения. Традиционная настройка конечной точки SageMaker будет выглядеть следующим образом:
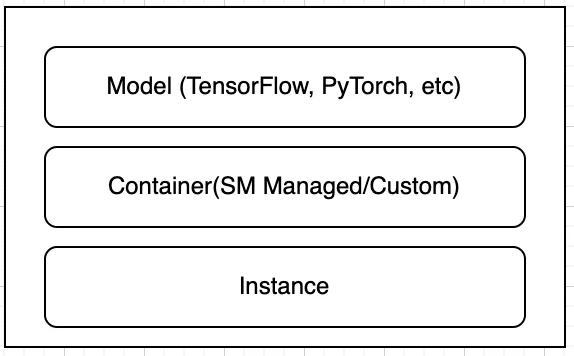
Когда у вас есть сотни или даже тысячи моделей, становится сложно управлять таким большим количеством различных конечных точек, и вам приходится платить…