Создание панели управления с использованием Python и Dash
Создание панели управления с Python и Dash
Введение
В области науки о данных и аналитики мощность данных освобождается не только путем извлечения понимания, но и путем эффективной коммуникации этих пониманий; именно здесь играет свою роль визуализация данных.

- 9 лучших веб-сайтов по искусственному интеллекту (которые вам обязательно нужно попробовать до смерти)
- Предоставление генеративного искусственного интеллекта в Поиске большему числу людей по всему миру
- Топ-12 генераторов музыки на основе искусственного интеллекта в 2023 году
Визуализация данных – это графическое представление информации и данных. Она использует визуальные элементы, такие как графики, диаграммы и карты, которые облегчают видимость закономерностей, трендов и выбросов в исходных данных. Для ученых по данным и аналитиков визуализация данных является неотъемлемым инструментом, который облегчает более быстрое и точное понимание данных, поддерживает повествование с помощью данных и помогает принимать решения на основе данных.
В этой статье вы узнаете, как использовать фреймворк Python и Dash для создания панели управления для визуализации распределения и классификации контента Netflix.

Что такое Dash?
Dash – это фреймворк с открытым исходным кодом, разработанный компанией Plotly для создания аналитических веб-приложений на чистом Python. Традиционно для таких целей могло потребоваться использование JavaScript и HTML, что требует навыков как в бэкэнд-разработке (Python), так и в фронтэнд-разработке (JavaScript, HTML).
Однако Dash сокращает эту разницу, позволяя ученым по данным и аналитикам создавать интерактивные и эстетичные панели управления, используя только Python. Этот аспект разработки с использованием низкого кода делает Dash подходящим выбором для создания аналитических панелей управления, особенно для тех, кто преимущественно знаком с Python.
Анализ набора данных
Теперь, когда вы познакомились с Dash, давайте начнем наш практический проект. Вы будете использовать набор данных о фильмах и телешоу Netflix, доступный на Kaggle, созданный Шивамом Бансалом.
Этот набор данных содержит сведения о фильмах и телешоу, доступных на Netflix на 2021 год, такие как тип контента, название, режиссер, актеры, страна производства, год выпуска, рейтинг, продолжительность и другие.
Несмотря на то, что набор данных был создан в 2021 году, он до сих пор является ценным ресурсом для развития навыков визуализации данных и понимания трендов в медиа-развлечениях.
Используя этот набор данных, вы будете стремиться создать панель управления, которая позволяет визуализировать следующие моменты:
- Географическое распределение контента: график на карте, показывающий, как производство контента меняется в разных странах с течением времени.
- Классификация контента: эта визуализация делит контент Netflix на телешоу и фильмы, чтобы увидеть, какие жанры наиболее популярны.
Настройка рабочего пространства проекта
Давайте начнем создание каталога для проекта с названием netflix-dashboard, затем инициализируем и активируем виртуальное окружение Python с помощью следующих команд:
# Linux & MacOS
mkdir netflix-dashboard && cd netflix-dashboard
python3 -m venv netflix-venv && source netflix-venv/bin/activate
# Windows Powershell
mkdir netflix-dashboard && cd netflix-dashboard
python -m venv netflix-venv && .\netflix-venv\Scripts\activate
Далее вам понадобится установить некоторые внешние пакеты. Вы будете использовать pandas для обработки данных, dash для создания панели управления, plotly для создания графиков и dash-bootstrap-components для добавления стиля в панель управления:
# Linux & MacOS
pip3 install pandas dash plotly dash-bootstrap-components
# Windows Powershell
pip install pandas dash plotly dash-bootstrap-components
Очистка набора данных
При просмотре набора данных Netflix вы обнаружите отсутствующие значения в столбцах director, cast и country. Также было бы удобно преобразовать значения столбца date_added из типа string в тип datetime для более удобного анализа.
Чтобы очистить набор данных, вы можете создать новый файл clean_netflix_dataset.py со следующим кодом и затем запустить его:
import pandas as pd
# Загрузка набора данных
df = pd.read_csv('netflix_titles.csv')
# Заполнение отсутствующих значений
df['director'].fillna('Нет режиссера', inplace=True)
df['cast'].fillna('Нет актеров', inplace=True)
df['country'].fillna('Нет страны', inplace=True)
# Удаление отсутствующих и дублирующихся значений
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
# Удаление пробелов из столбца `date_added` и преобразование значений в тип `datetime`
df['date_added'] = pd.to_datetime(df['date_added'].str.strip())
# Сохранение очищенного набора данных
df.to_csv('netflix_titles.csv', index=False)
Начало работы с Dash
После настройки рабочего пространства и очистки набора данных вы готовы приступить к работе над панелью управления. Создайте новый файл app.py со следующим кодом:
from dash import Dash, dash_table, html
import pandas as pd
# Инициализация Dash-приложения
app = Dash(__name__)
# Определение макета приложения
app.layout = html.Div([
html.H1('Панель управления фильмами и ТВ-шоу Netflix'),
html.Hr(),
])
# Запуск Dash-приложения в режиме локальной разработки
if __name__ == '__main__':
app.run_server(debug=True)
Давайте разберем код внутри app.py:
app = Dash(__name__): Эта строка инициализирует новое Dash-приложение. Подумайте о ней как о фундаменте вашего приложения.app.layout = html.Div(…): Атрибутapp.layoutпозволяет вам писать код, похожий на HTML, для создания пользовательского интерфейса вашего приложения. В приведенном выше макете используется элемент заголовкаhtml.H1(…)для заголовка панели управления и элемент разделителяhtml.Hr()под заголовком.app.run(debug=True): Эта строка запускает сервер разработки, который обслуживает ваше Dash-приложение в режиме локальной разработки. Dash использует Flask, легковесный фреймворк веб-сервера, для обслуживания ваших приложений веб-браузерам.
После запуска app.py вы увидите сообщение в терминале, указывающее, что ваше Dash-приложение работает и доступно по адресу http://127.0.0.1:8050/. Откройте этот URL в веб-браузере, чтобы увидеть его:

Результат выглядит слишком просто, верно? Не беспокойтесь! Этот раздел предназначен для демонстрации самой базовой структуры и компонентов Dash-приложения. Вы вскоре добавите больше функций и компонентов, чтобы сделать его потрясающей панелью управления!
Интеграция компонентов Dash Bootstrap
Следующий шаг – написать код для макета вашей панели управления и добавить к ней немного стиля! Для этого вы можете использовать компоненты Dash Bootstrap (DBC), библиотеку, которая предоставляет компоненты Bootstrap для Dash, позволяя разрабатывать стилизованные приложения с адаптивными макетами.
Панель управления будет оформлена в виде вкладочного макета, который обеспечивает компактный способ организации различных типов информации в одном пространстве. Каждая вкладка будет соответствовать отдельной визуализации.
Давайте продолжим и измените содержимое app.py, чтобы включить DBC:
from dash import Dash,dcc, html
import pandas as pd
import dash_bootstrap_components as dbc
# Инициализация Dash-приложения и импорт темы Bootstrap для стилизации панели управления
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = dbc.Container(
[
dcc.Store(id='store'),
html.H1('Панель управления фильмами и ТВ-шоу Netflix'),
html.Hr(),
dbc.Tabs(
[
dbc.Tab(label='Географическое распределение контента', tab_id='tab1'),
dbc.Tab(label='Классификация контента', tab_id='tab2'),
],
id='tabs',
active_tab='tab1',
),
html.Div(id='tab-content', className='p-4'),
]
)
if __name__ == '__main__':
app.run(debug=True)
В этой модифицированной разметке вы увидите новые компоненты:
dbc.Container: Использованиеdbc.Containerв качестве компонента верхнего уровня оборачивает всю разметку панели инструментов в отзывчивый и гибкий контейнер.dcc.Store: Этот компонент Dash Core позволяет хранить данные на стороне клиента (в браузере пользователя), повышая производительность приложения за счет локального хранения данных.dbc.Tabsиdbc.Tab: Каждыйdbc.Tabпредставляет отдельную вкладку, которая будет содержать разные визуализации. Свойствоlabelопределяет название вкладки, аtab_idиспользуется для идентификации вкладки. Свойствоactive_tabкомпонентаdbc.Tabsиспользуется для указания активной вкладки при запуске приложения Dash.
Теперь запустите app.py. В результате панель инструментов будет иметь макет в стиле Bootstrap с двумя пустыми вкладками:
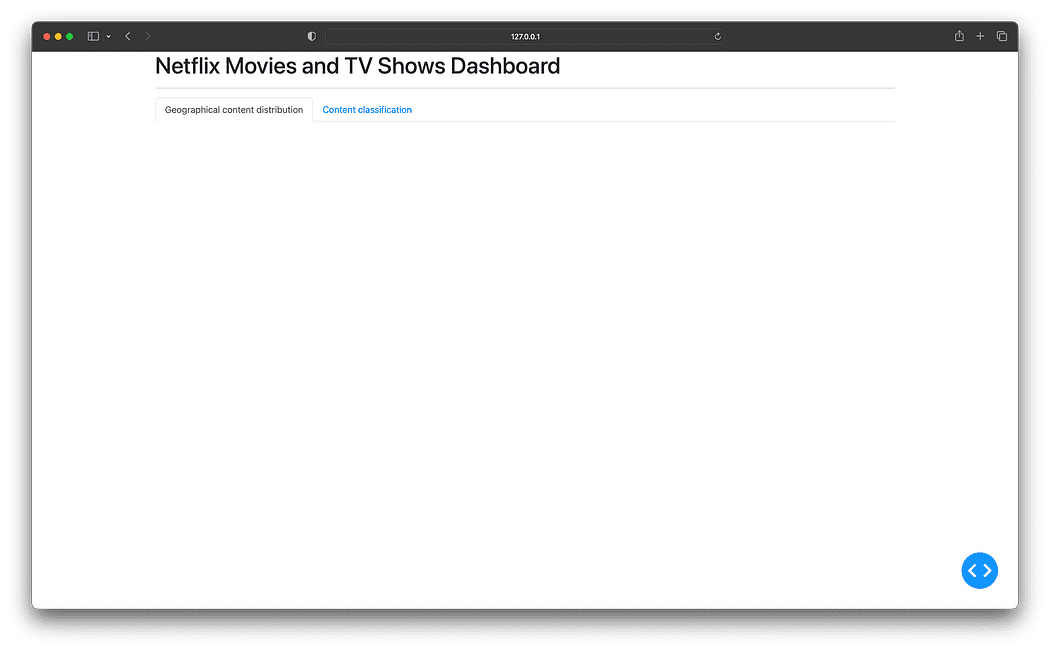
Хорошая работа! Теперь вы готовы добавить визуализации на панель инструментов.
Добавление обратных вызовов и визуализаций
При работе с Dash интерактивность достигается с помощью функций обратного вызова. Функция обратного вызова – это функция, которая автоматически вызывается при изменении свойства ввода. Она называется “обратный вызов”, потому что Dash автоматически “возвращает вызов” этой функции при каждом изменении в приложении.
В этой панели инструментов вы будете использовать обратные вызовы для отображения соответствующей визуализации на выбранной вкладке, и каждая визуализация будет храниться в собственном файле Python в новом каталоге components для лучшей организации и модульности структуры проекта.
Визуализация географического распределения контента
Создадим новый каталог с именем components, а внутри него создадим файл geographical_content.py, который будет генерировать хороплет-карту, иллюстрирующую изменение производства контента Netflix по странам в течение лет:
import pandas as pd
import plotly.express as px
from dash import dcc, html
df = pd.read_csv('netflix_titles.csv')
# Отфильтровать записи без информации о стране и в случае наличия нескольких стран-производителей
# рассматривать первую страну как страну-производителя
df['country'] = df['country'].str.split(',').apply(lambda x: x[0].strip() if isinstance(x, list) else None)
# Извлечь год из столбца date_added
df['year_added'] = pd.to_datetime(df['date_added']).dt.year
df = df.dropna(subset=['country', 'year_added'])
# Вычислить количество контента, произведенного каждой страной для каждого года
df_counts = df.groupby(['country', 'year_added']).size().reset_index(name='count')
# Отсортировать DataFrame по 'year_added' для обеспечения возрастающего порядка анимационных кадров
df_counts = df_counts.sort_values('year_added')
# Создать хороплет-карту с ползунком для года
fig1 = px.choropleth(df_counts,
locations='country',
locationmode='country names',
color='count',
hover_name='country',
animation_frame='year_added',
projection='natural earth',
title='Контент, произведенный странами за годы',
color_continuous_scale='YlGnBu',
range_color=[0, df_counts['count'].max()])
fig1.update_layout(width=1280, height=720, title_x=0.5)
# Вычислить количество контента, произведенного для каждого года по типу и заполнить нулями отсутствующие пары тип-год
df_year_counts = df.groupby(['year_added', 'type']).size().reset_index(name='count')
# Создать линейную диаграмму с использованием plotly express
fig2 = px.line(df_year_counts, x='year_added', y='count', color='type',
title='Распределение контента по типу в течение лет',
markers=True, color_discrete_map={'Movie': 'dodgerblue', 'TV Show': 'darkblue'})
fig2.update_traces(marker=dict(size=12))
fig2.update_layout(width=1280, height=720, title_x=0.5)
layout = html.Div([
dcc.Graph(figure=fig1),
html.Hr(),
dcc.Graph(figure=fig2)
])
Вышеуказанный код фильтрует и группирует данные по столбцам 'country' и 'year_added', затем вычисляет количество контента, произведенного каждой страной для каждого года в DataFrame df_counts.
Затем функция px.choroplet создает график-карту, используя столбцы из DataFrame df_counts в качестве значений для своих аргументов:
locations='country': Позволяет указать географические значения местоположения, содержащиеся в столбце'country'.locationmode='country names': Этот аргумент “говорит функции”, что предоставленные значенияlocations– это названия стран, поскольку Plotly Express также поддерживает другие режимы расположения, такие как коды стран ISO-3 или штаты США.color='count': Используется для указания числовых данных, используемых для раскраски карты. Здесь он относится к столбцу'count', который содержит количество контента, произведенного каждой страной для каждого года.color_continuous_scale='YlGnBu': Создает непрерывную цветовую шкалу для каждой страны на карте, когда столбец, обозначенный какcolor, содержит числовые данные.animation_frame='year_added': Этот аргумент создает анимацию по столбцу'year_added'. Он добавляет слайдер года к графику-карте, позволяя просматривать анимацию, которая представляет собой развитие производства этого контента в каждой стране из года в год.projection='natural earth': Этот аргумент не использует столбцы из DataFramedf_counts; однако значение'natural earth'необходимо для установки проекции с картой мира Земли.
И прямо под картой хороплета включен график линии с маркерами, отображающий изменение объема контента, категоризированного по типу (телешоу или фильмы), на протяжении лет.
Для создания линейного графика создается новый DataFrame df_year_counts, который группирует исходные данные DataFrame df по столбцам 'year_added' и 'type', подсчитывая количество контента для каждой комбинации.
Эти сгруппированные данные затем используются с px.line, где аргументы 'x' и 'y' назначаются соответственно столбцам 'year_added' и 'count', а аргумент 'color' устанавливается в 'type' для различения между телешоу и фильмами.
Визуализация классификации контента
Следующим шагом является создание нового файла с именем content_classification.py, который будет генерировать график дерева, чтобы визуализировать контент Netflix с точки зрения типа и жанра:
import pandas as pd
import plotly.express as px
from dash import dcc, html
df = pd.read_csv('netflix_titles.csv')
# Разделите столбец listed_in и разорвите его, чтобы обработать несколько жанров
df['listed_in'] = df['listed_in'].str.split(', ')
df = df.explode('listed_in')
# Вычислите количество каждой комбинации типа и жанра
df_counts = df.groupby(['type', 'listed_in']).size().reset_index(name='count')
fig = px.treemap(df_counts, path=['type', 'listed_in'], values='count', color='count',
color_continuous_scale='Ice', title='Контент по типу и жанру')
fig.update_layout(width=1280, height=960, title_x=0.5)
fig.update_traces(textinfo='label+percent entry', textfont_size=14)
layout = html.Div([
dcc.Graph(figure=fig),
])
В приведенном выше коде, после загрузки данных, столбец 'listed_in' регулируется для обработки нескольких жанров на контент путем разделения и разрыва жанров, создавая новую строку для каждого жанра на контент.
Далее создается DataFrame df_counts, чтобы сгруппировать данные по столбцам 'type' и 'listed_in', и вычислить количество каждой комбинации типа и жанра.
Затем столбцы из DataFrame df_counts используются в качестве значений для аргументов функции px.treemap следующим образом:
path=['type', 'listed_in']: Это иерархические категории, представленные в древовидной картограмме. Столбцы'type'и'listed_in'содержат типы контента (телесериалы или фильмы) и жанры соответственно.values='count': Размер каждого прямоугольника в древовидной картограмме соответствует столбцу'count', представляющему количество контента для каждой комбинации типа и жанра.color='count': Столбец'count'также используется для окрашивания прямоугольников в древовидной картограмме.color_continous_scale='Ice': Создает непрерывную цветовую шкалу для каждого прямоугольника в древовидной картограмме, когда столбец, обозначенныйcolor, содержит числовые данные.
После создания двух новых файлов визуализации, структура текущего проекта должна выглядеть следующим образом:
netflix-dashboard
├── app.py
├── clean_netflix_dataset.py
├── components
│ ├── content_classification.py
│ └── geographical_content.py
├── netflix-venv
│ ├── bin
│ ├── etc
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
└── netflix_titles.csv
Реализация обратных вызовов
Последний шаг – изменить файл app.py для импорта двух новых визуализаций из каталога components и реализации функций обратного вызова для отображения графиков при выборе вкладок:
from dash import Dash, dcc, html, Input, Output
import dash_bootstrap_components as dbc
from components import (
geographical_content,
content_classification
)
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = dbc.Container(
[
dcc.Store(id='store'),
html.H1('Netflix Movies and TV Shows Dashboard'),
html.Hr(),
dbc.Tabs(
[
dbc.Tab(label='Geographical content distribution', tab_id='tab1'),
dbc.Tab(label='Content classification', tab_id='tab2'),
],
id='tabs',
active_tab='tab1',
),
html.Div(id='tab-content', className='p-4'),
]
)
# Эта функция обратного вызова переключает вкладки в панели управления на основе выбора пользователя.
# Она обновляет компонент 'tab-content' макетом новой выбранной вкладки.
@app.callback(Output('tab-content', 'children'), [Input('tabs', 'active_tab')])
def switch_tab(at):
if at == 'tab1':
return geographical_content.layout
elif at == 'tab2':
return content_classification.layout
if __name__ == '__main__':
app.run(debug=True)
Декоратор обратного вызова @app.callback слушает изменения свойства 'active_tab' компонента 'tabs', представленного объектом Input.
Когда изменяется 'active_tab', вызывается функция switch_tab. Эта функция проверяет идентификатор 'active_tab' и возвращает соответствующий макет для отображения в блоке 'tab-content', как указано объектом Output. Таким образом, при переключении вкладок появляется соответствующая визуализация.
Наконец, запустите app.py еще раз, чтобы увидеть обновленную панель управления с новыми визуализациями:

Заключение
В этой статье вы узнали, как создать панель управления для исследования и визуализации распределения и классификации контента Netflix. Благодаря использованию Python и Dash вы теперь оснащены инструментами для создания собственных визуализаций, предоставляющих ценные инсайты в ваши данные.
Вы можете ознакомиться с полным кодом этого проекта в следующем репозитории GitHub: https://github.com/gutyoh/netflix-dashboard
Если вы нашли эту статью полезной и хотите расширить свои знания в Python и Data Science, рекомендую ознакомиться с треком Введение в Data Science на Hyperskill.
Оставьте свои вопросы или отзывы в комментариях ниже, если у вас есть какие-либо вопросы или отзывы по поводу этого блога.
Германн Рёш является техническим автором трека по программированию на языке Go в Hyperskill, где он сочетает свою страсть к EdTech для поддержки следующего поколения программных инженеров. В то же время он погружается в мир данных как студент магистратуры в Университете Иллинойса в Урбане-Шампейне.
Оригинал. Размещено с разрешения.