Связь идей Сравнение SQL и Python запросов с использованием аналитики книжного магазина
Сравнение SQL и Python запросов в аналитике книжного магазина.
Какой подход лучше для ваших исследовательских анализов данных?
SQL – основа инструментария любого специалиста по обработке данных – возможность быстро извлекать данные из источника для анализа является важным навыком для всех, кто работает с большим объемом данных. В этой статье я хотел бы привести несколько примеров нескольких базовых запросов, которые я обычно использую в SQL в ходе процесса EDA. Я сравню эти запросы с аналогичными сценариями на Python, которые дают тот же результат, чтобы сравнить два подхода.
Для данного анализа я буду использовать некоторые синтетические данные о самых высоко оцененных книгах прошлого года от гипотетической сети книжных магазинов (Total Fiction Bookstore). Ссылка на папку проекта на GitHub может быть найдена здесь, где я подробнее описываю запуск анализа.
Кстати – хотя я в основном фокусируюсь на SQL-запросах в этой статье, стоит отметить, что эти запросы могут быть легко интегрированы с Python с использованием библиотеки pandaSQL (как я сделал для этого проекта). Подробности можно увидеть в Jupyter-ноутбуке по ссылке на GitHub этого проекта, но структура этого запроса обычно выглядит следующим образом:
query = """SELECT * FROM DATA"""output = sqldf(query,locals())outputPandaSQL – очень практичная библиотека для тех, кто имеет больше опыта в запросах на SQL, чем в типичной манипуляции наборами данных Pandas – и зачастую гораздо проще в чтении, как я покажу здесь.
- OpenAI открывает ворота для предприятий искусственного интеллекта
- Как создать хранилище функций AI/ML с помощью NoSQL-базы данных ScyllaDB
- Руководство по Pandas 7 необходимых всесторонних функций для работы с данными
Набор данных
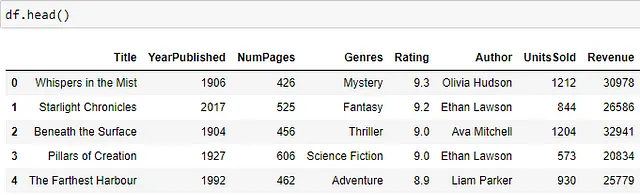
Ниже показан фрагмент набора данных – есть столбцы для названия книги и года ее публикации, количества страниц, жанров, среднего рейтинга книги, автора, количества проданных единиц и выручки от книг.
Анализ выручки по десятилетиям
Предположим, я хочу узнать, в каком десятилетии были опубликованы наиболее прибыльные книги для книжного магазина. В исходном наборе данных нет столбца, указывающего, в каком десятилетии были опубликованы книги, однако это относительно просто добавить в данные. Я выполняю подзапрос для деления года с помощью целочисленного деления и умножения на 10 для получения данных о десятилетии, затем агрегирую и усредняю голоса по десятилетиям. Затем сортирую результаты по общей выручке, чтобы получить наиболее прибыльные десятилетия опубликованных книг в книжном магазине.
WITH bookshop AS(SELECT TITLE, YEARPUBLISHED,(YEARPUBLISHED/10) * 10 AS DECADE,NUMPAGES, GENRES, RATING, AUTHOR, UNITSSOLD,REVENUEfrom df)SELECT DECADE, SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUEFROM bookshopGROUP BY DECADEORDER BY TOTAL_REVENUE DESCВ сравнении, эквивалентный вывод на Python будет выглядеть примерно так, как фрагмент кода ниже. Я применяю лямбда-функцию, которая выполняет целочисленное деление и выводит десятилетие, а затем агрегирую голоса по десятилетиям и сортирую результаты по общей выручке.
# создание df bookshopbookshop = df.copy()bookshop['Decade'] = (bookshop['YearPublished'] // 10) * 10# группировка по десятилетиям, агрегация выручки по сумме и среднему результат = bookshop.groupby('DECADE') \ .agg({'Revenue': ['sum', 'mean']}) \ .reset_index()result.columns = ['Decade', 'Total_Revenue', 'Avg_Revenue']# сортировка по десятилетиямresult = result.sort_values('Total_Revenue')Обратите внимание на большее количество отдельных шагов в python-скрипте для достижения того же результата – функции неудобны и сложны для понимания с первого взгляда. По сравнению с этим SQL-скрипт гораздо более ясен в своем представлении и намного легче читается.
Теперь я могу взять этот запрос и визуализировать его, чтобы получить представление о тенденциях в доходах от книг на протяжении десятилетий, настроив график matplotlib с помощью следующего скрипта – столбчатые диаграммы показывают общий доход по десятилетиям, с диаграммой рассеяния на вторичной оси, показывающей средний доход от книг.
# Создание первой оси y (общий доход)fig, ax1 = plt.subplots(figsize=(15, 9))ax1.bar(agg_decade['DECADE'], agg_decade['TOTAL_REVENUE'], width = 0.4, align='center', label='Общий доход (доллары)')ax1.set_xlabel('Десятилетие')ax1.set_ylabel('Общий доход (доллары)', color='blue')# Настройка сетки на первой оси уax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# Создание второй оси y (средний доход)ax2 = ax1.twinx()ax2.scatter(agg_decade['DECADE'], agg_decade['AVG_REVENUE'], marker='o', color='red', label='Средний доход (доллары)')ax2.set_ylabel('Средний доход (доллары)', color='red')# Настройка сетки на второй оси уax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# Установка одинаковых границ для осей ax1 и ax2ax1.set_ylim(0, 1.1*max(agg_decade['TOTAL_REVENUE']))ax2.set_ylim(0, 1.1*max(agg_decade['AVG_REVENUE']))# Объединение легенд для обеих осейlines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax2.legend(lines + lines2, labels + labels2, loc='верхний левый')# Заголовокplt.title('Общий и средний доход по десятилетию')# Показать графикplt.show()Визуализацию можно увидеть ниже – книги, опубликованные в 1960-х годах, являются, по-видимому, наиболее прибыльными для книжного магазина, принося около $192,000 дохода для Total Fiction Bookstore. По сравнению с этим, книги из списка 1900-х годов в среднем прибыльнее, хотя и не продавались так хорошо, как книги 1960-х годов.

Средний доход от книг следует похожей тенденции к общему доходу на протяжении всех десятилетий издания книг – за исключением книг 1900-х и 1980-х годов, которые в среднем прибыльнее, но не в целом.
Анализ автора
Теперь предположим, что я хочу получить данные о 10 лучших авторах из списка, упорядоченных по их общему сгенерированному доходу. Для этого запроса я хочу узнать количество книг, которые они создали и которые присутствуют в списке, общий доход, сгенерированный на этих книгах, их средний доход на книгу и средний рейтинг этих книг в книжном магазине. Достаточно простой вопрос для ответа с использованием SQL – я могу использовать оператор count, чтобы получить общее количество книг, которые они создали, и операторы avg, чтобы получить средний доход и рейтинг для каждого автора. Затем я могу сгруппировать эти операторы по режиссеру.
SELECT AUTHOR,COUNT(TITLE) AS NUM_BOOKS,SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUE,ROUND(AVG(RATING),2) AS AVG_RATING_PER_BOOKFROM bookshopGROUP BY AUTHORORDER BY TOTAL_REVENUE DESCLIMIT 10Эквивалентный скрипт на Python будет выглядеть следующим образом – примерно та же длина, но гораздо более сложный для получения того же результата. Я группирую значения по автору перед указанием, как агрегировать каждый столбец в функции agg, затем сортирую значения по общему доходу. Снова SQL-скрипт намного более понятен по сравнению.
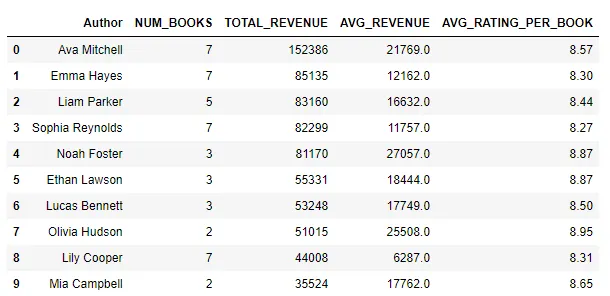
result = bookshop.groupby('Author') \ .agg({ 'Title': 'count', 'Revenue': ['sum', 'mean'], 'Rating': 'mean' }) \ .reset_index()result.columns = ['Author', 'Num_Books', 'Total_Revenue', 'Avg_Revenue', 'Avg_Rating_per_Book']# Сортировка по общему доходуresult = result.sort_values('Total_Revenue', ascending=False)# Топ 10result_top10 = result.head(10)Результаты этого запроса можно увидеть ниже — Ава Митчелл лидирует, с общим доходом более 152 000 долларов от продаж своих книг. Эмма Хейс занимает второе место с более чем 85 000 долларов, а Лиам Паркер немного отстает с более чем 83 000 долларов.
Визуализируя это в matplotlib с использованием следующего скрипта, мы можем создать столбчатые диаграммы общего дохода с точками данных, показывающими средний доход от книги на автора. Средний рейтинг на автора также отображается на вторичной оси.
# Создание фигуры и осиfig1, ax1 = plt.subplots(figsize=(15, 9))# Построение столбчатой диаграммы общего доходаax1.bar(agg_author['Author'], agg_author['TOTAL_REVENUE'], width=0.4, align='center', color='silver', label='Общий доход (доллары)')ax1.set_xlabel('Автор')ax1.set_xticklabels(agg_author['Author'], rotation=-45, ha='left')ax1.set_ylabel('Общий доход (доллары)', color='blue')# Настройка линий сетки на основной оси yax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# Создание точечной диаграммы среднего доходаax1.scatter(agg_author['Author'], agg_author['AVG_REVENUE'], marker="D", color='blue', label='Средний доход за книгу (доллары)')# Создание точечной диаграммы среднего рейтинга на вторичной осиax2 = ax1.twinx()ax2.scatter(agg_author['Author'], agg_author['AVG_RATING_PER_BOOK'], marker='^', color='red', label='Средний рейтинг за книгу')ax2.set_ylabel('Средний рейтинг', color='red')# Настройка линий сетки на вторичной оси yax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# Комбинирование легенд для обеих осейlines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax1.legend(lines + lines2, labels + labels2, loc='upper right')# Установка заголовкаplt.title('Топ 10 авторов по доходу, рейтингу')# Показать графикplt.show()Запустив это, мы получаем следующий график:
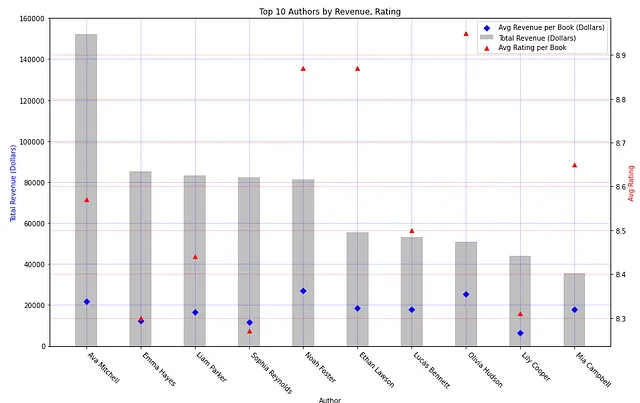
Этот график указывает на довольно явное утверждение — доход не коррелирует с средним рейтингом для каждого автора. Ава Митчелл имеет самый высокий доход, но находится в среднем в терминах рейтинга среди указанных выше авторов. Оливия Хадсон имеет самый высокий средний рейтинг, но занимает 8-е место по общему количеству голосов; нет заметной тенденции между доходом автора и его популярностью.
Сравнение длины книги и дохода
Наконец, предположим, что я хочу показать, как доход от книги отличается в зависимости от длины книги. Чтобы ответить на этот вопрос, я сначала хочу разделить книги на 4 категории на основе квартилей длины книги, что даст лучшее представление о тенденциях общего дохода по длине книги.
Сначала я определяю квартили в SQL, используя подзапрос для генерации этих значений, а затем сортирую книги в эти группы с использованием оператора case when.
WITH PERCENTILES AS ( SELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_25, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY NUMPAGES) AS MEDIAN, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_75 FROM bookshop)SELECT TITLE, TITLE, REVENUE, NUMPAGES, CASE WHEN NUMPAGES< (SELECT PERCENTILE_25 FROM PERCENTILES) THEN 'Квартиль 1' WHEN NUMPAGES BETWEEN (SELECT PERCENTILE_25 FROM PERCENTILES) AND (SELECT MEDIAN FROM PERCENTILES) THEN 'Квартиль 2' WHEN NUMPAGES BETWEEN (SELECT MEDIAN FROM PERCENTILES) AND (SELECT PERCENTILE_75 FROM PERCENTILES) THEN 'Квартиль 3' WHEN NUMPAGES > (SELECT PERCENTILE_75 FROM PERCENTILES) THEN 'Квартиль 4' END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESCВ альтернативе (для SQL диалектов, которые не поддерживают функции процентилей, например SQLite), квартили могут быть вычислены отдельно, а затем вручную введены в оператор case when.
--Для диалекта SQLiteSELECT TITLE, REVENUE, NUMPAGES,CASEWHEN NUMPAGES < 318 THEN 'Квартиль 1'WHEN NUMPAGES BETWEEN 318 AND 375 THEN 'Квартиль 2'WHEN NUMPAGES BETWEEN 375 AND 438 THEN 'Квартиль 3'WHEN NUMPAGES > 438 THEN 'Квартиль 4'END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESCЗапуская этот же запрос в Python, я определяю процентили с помощью библиотеки numpy, а затем использую функцию cut для сортировки книг по их группам, с последующей сортировкой значений по длине книги в страницах. Как и раньше, этот процесс заметно более сложный, чем эквивалентный скрипт на SQL.
# Определение процентилей с использованием numpypercentiles = np.percentile(bookshop['NumPages'], [25, 50, 75])# Определение границ корзин с использованием вычисленных процентилейbin_edges = [-float('inf'), *percentiles, float('inf')]# Определение меток для корзинbucket_labels = ['Квартиль 1', 'Квартиль 2', 'Квартиль 3', 'Квартиль 4']# Создание столбца 'RUNTIME_BUCKET' на основе границ корзин и метокbookshop['RUNTIME_BUCKET'] = pd.cut(bookshop['NumPages'], bins=bin_edges, labels=bucket_labels)result = bookshop[['Title', 'Revenue', 'NumPages', 'PAGELENGTH_QUARTILE']].sort_values(by='NumPages', ascending=False)Результат этого запроса можно визуализировать с помощью boxplot, используя библиотеку seaborn. Ниже приведен фрагмент скрипта, используемого для создания boxplot. Обратите внимание, что группы времени выполнения были вручную отсортированы в правильном порядке для их корректного представления.
# Установка стиля для графикасns.set(style="whitegrid")# Установка порядка групп прибыльных корзинpagelength_bucket_order = ['Квартиль 1', 'Квартиль 2', 'Квартиль 3', 'Квартиль 4']# Создание boxplotplt.figure(figsize=(16, 10))sns.boxplot(x='PAGELENGTH_QUARTILE', y='Revenue', data=pagelength_output, order = pagelength_bucket_order, showfliers=True)# Добавление меток и заголовкаplt.xlabel('Квартиль длины страницы')plt.ylabel('Прибыль (Доллары)')plt.title('Boxplot прибыли по квартилю длины страницы')# Показать графикplt.show()Boxplot можно увидеть ниже — обратите внимание, что медианная прибыль для каждого квартиля длины книги увеличивается по мере увеличения длины книг. Это говорит о том, что более длинные книги являются более прибыльными в книжном магазине.
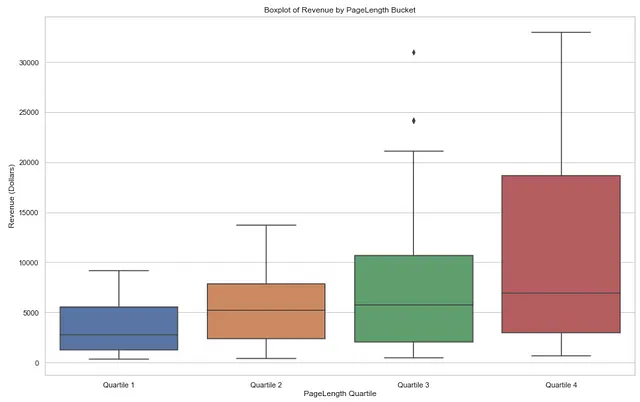
Кроме того, диапазон 4-го квартиля гораздо шире по сравнению с другими квартилями, что указывает на большую вариацию в ценовом диапазоне для более крупных книг.
Заключительные мысли и дальнейшие применения
В заключение, использование SQL для запросов анализа данных обычно намного проще, чем использование эквивалентных операций в Python; язык проще в написании, чем запросы на Python, но в целом способен давать те же результаты. Я не буду утверждать, что один лучше другого — я использовал комбинацию обоих языков в этом анализе — скорее, я считаю, что использование обоих языков вместе может обеспечить более эффективный и эффективный анализ данных.
Следовательно, учитывая большую ясность при написании запросов на SQL по сравнению с запросами на Python, я считаю, что гораздо естественнее использовать его при выполнении начального EDA для проекта. SQL гораздо проще читать и писать, как я показал в этой статье, что особенно выгодно для этих ранних исследовательских задач. Я часто использую его, начиная работу над проектом, и рекомендую такой подход всем, кто уже хорошо владеет SQL.






