Применение описательной и инференциальной статистики в Python
Статистика в Python

Статистика – это область, охватывающая деятельность, начиная с сбора данных и их анализа, заканчивая интерпретацией данных. Это наука, которая помогает заинтересованным сторонам принимать решения в условиях неопределенности.
В статистике существуют две основные области: описательная и инференционная. Описательная статистика связана с суммированием данных с использованием различных методов, таких как сводные статистики, визуализация и таблицы. В то время как инференционная статистика больше о генерализации популяции на основе выборки данных.
В этой статье мы рассмотрим несколько важных концепций описательной и инференционной статистики на примере Python. Давайте приступим.
- Алгоритм Рейнгольда-Тилфорда, объясненный с пошаговым руководством
- Разгадайте тайну зубчатой диаграммы COVID
- Как социально-образовательный индекс влияет на результаты выпускников школы? – Байесовский анализ с использованием R и brms
Описательная статистика
Как я уже упоминал ранее, описательная статистика сосредоточена на суммировании данных. Это наука о преобразовании необработанных данных в содержательную информацию. Описательная статистика может выполняться с помощью графиков, таблиц или сводных статистик. Однако наиболее популярным способом выполнения описательной статистики являются сводные статистики, поэтому мы сосредоточимся на них.
В качестве примера мы будем использовать следующий набор данных.
import pandas as pd
import numpy as np
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()
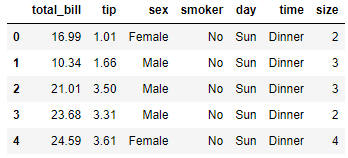
С этими данными мы будем изучать описательную статистику. В сводных статистиках наиболее используемые два показателя: Показатели центральной тенденции и Показатели разброса.
Показатели центральной тенденции
Центральная тенденция – это центр распределения данных или данных набора. Показатели центральной тенденции – это меры, направленные на получение или описание центрального распределения наших данных. Показатели центральной тенденции дают единственное значение, которое определяет центральное положение данных.
Среди показателей центральной тенденции наиболее популярны три измерения:
1. Среднее значение
Среднее значение или среднее арифметическое – это метод получения единственного значения, представляющего наиболее распространенное значение наших данных. Однако среднее значение не обязательно совпадает со значением, наблюдаемым в наших данных.
Мы можем рассчитать среднее значение, сложив существующие значения в наших данных и разделив их на количество значений. Мы можем представить среднее значение с помощью следующего уравнения:
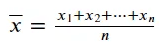
В Python мы можем рассчитать среднее значение данных с помощью следующего кода.
round(tips['tip'].mean(), 3)
2.998
Используя атрибут серии pandas, мы можем получить среднее значение данных. Мы также округляем данные для удобства чтения.
Среднее значение имеет недостаток в качестве показателя центральной тенденции, так как оно сильно зависит от выбросов, которые могут исказить сводную статистику и не лучшим образом представлять фактическую ситуацию. В случае скошенных значений мы можем использовать медиану.
2. Медиана
Медиана – это единственное значение, расположенное в середине данных при их сортировке, представляющее позицию середины данных (50%). Как показатель центральной тенденции, медиана предпочтительна, когда данные скошены, поскольку она может представлять центр данных, так как выбросы или скошенные значения не оказывают на нее сильного влияния.
Медиана рассчитывается путем упорядочивания всех значений данных в порядке возрастания и нахождения среднего значения. Медиана является средним значением для нечетного количества значений данных, но медиана является средним значением двух средних значений для четного количества значений данных.
Мы можем рассчитать медиану с помощью Python, используя следующий код.
tips['tip'].median()
2.9
3. Мода
Мода – это наиболее часто встречающееся значение или наиболее часто встречающаяся частота в данных. Данные могут иметь одну моду (унимодальные), несколько мод (мультимодальные) или вообще не иметь моды (если нет повторяющихся значений).
Режим обычно используется для категориальных данных, но может использоваться и для числовых данных. Однако для категориальных данных может быть использован только режим. Это связано с тем, что категориальные данные не имеют числовых значений для расчета среднего и медианы.
Мы можем вычислить режим данных с помощью следующего кода.
tips['day'].mode()
 Результатом является объект серии с категориальными значениями. Значение ‘Sat’ выделяется, поскольку это режим данных.
Результатом является объект серии с категориальными значениями. Значение ‘Sat’ выделяется, поскольку это режим данных.
Показатели разброса
Показатели разброса (или изменчивости, дисперсии) – это измерение, описывающее распределение значений данных. Эти показатели предоставляют информацию о том, как варьируются значения данных внутри набора данных. Они часто используются вместе с показателями центральной тенденции, так как они дополняют общую информацию о данных.
Показатели разброса также помогают понять, насколько хорошо наши показатели центральной тенденции работают. Например, больший разброс данных может указывать на значительное отклонение между наблюдаемыми данными и средним значением данных, которое может не лучше всего представлять данные.
Вот несколько показателей разброса, которые можно использовать.
- Диапазон
Диапазон – это разница между наибольшим (Макс) и наименьшим (Мин) значениями данных. Это самое прямое измерение, поскольку информация использует только два аспекта данных.
Использование может быть ограничено, поскольку это не говорит много о распределении данных, но это может помочь нашим предположениям, если у нас есть определенный порог для использования наших данных. Давайте попробуем вычислить диапазон данных с помощью Python.
tips['tip'].max() - tips['tip'].min()
9.0
2. Дисперсия
Дисперсия – это показатель разброса, который информирует о разбросе данных на основе среднего значения данных. Мы вычисляем дисперсию, возводя в квадрат разности каждого значения от среднего значения данных и деля это на количество значений данных. Поскольку мы обычно работаем с выборками данных, а не с популяциями, мы вычитаем из количества значений данных единицу. Уравнение для выборочной дисперсии приведено на изображении ниже.
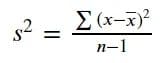
Дисперсию можно интерпретировать как значение, указывающее, насколько данные распределены относительно среднего значения и друг друга. Большая дисперсия означает более широкий разброс данных. Однако вычисление дисперсии чувствительно к выбросу, поскольку мы возвели в квадрат отклонения оценок от среднего значения; это означает, что мы уделили больше внимания выбросу.
Давайте попробуем вычислить дисперсию данных с помощью Python.
round(tips['tip'].var(),3)
1.914
Дисперсия выше может указывать на высокую дисперсию в наших данных, но мы можем использовать стандартное отклонение для получения фактического значения измерения разброса данных.
3. Стандартное отклонение
Стандартное отклонение – наиболее распространенный способ измерения разброса данных, и оно вычисляется извлечением квадратного корня из дисперсии.
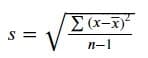
Разница между дисперсией и стандартным отклонением заключается в информации, которую они предоставляют. Значение дисперсии указывает только на то, как сильно значения распределены относительно среднего значения, и единица дисперсии отличается от исходного значения, так как мы возвели в квадрат исходные значения. Однако значение стандартного отклонения имеет ту же единицу, что и исходное значение данных, что означает, что значение стандартного отклонения можно использовать напрямую для измерения разброса наших данных.
Давайте попробуем вычислить стандартное отклонение с помощью следующего кода.
round(tips['tip'].std(),3)
1.384
Одним из наиболее распространенных применений стандартного отклонения является оценка интервала данных. Мы можем оценить интервал данных, используя эмпирическое правило или правило 68-95-99,7. Эмпирическое правило гласит, что 68% данных предполагается попадает в интервал среднего значения данных ± одно стандартное отклонение, 95% данных – в интервал среднего значения ± два стандартных отклонения, и 99,7% данных – в интервал среднего значения ± три стандартных отклонения. За пределами этого интервала можно считать выбросом.
4. Межквартильный размах
Межквартильный размах (IQR) – это мера разброса, рассчитываемая с использованием разницы между данными первого и третьего квартилей. Сам квартиль – это значение, которое разделяет данные на четыре разные части. Чтобы лучше понять, давайте взглянем на следующее изображение.
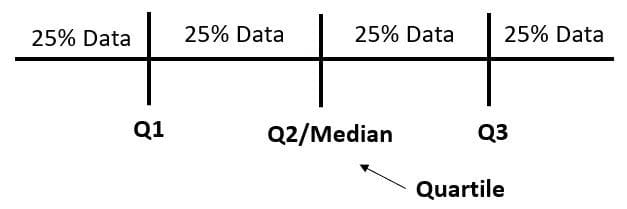
Квартиль – это значение, которое делит данные, а не результат деления. Мы можем использовать следующий код для нахождения значений квартилей и IQR.
q1, q3= np.percentile(tips['tip'], [25 ,75])
iqr = q3 - q1
print(f'Q1: {q1}\nQ3: {q3}\nIQR: {iqr}')
Q1: 2.0
Q3: 3.5625
IQR: 1.5625
С помощью функции перцентиля numpy мы можем получить квартиль. Вычисляя разницу между третьим квартилем и первым квартилем, мы получаем IQR.
IQR можно использовать для определения выбросов данных, рассчитывая верхний/нижний предел данных. Формула верхнего предела – это Q3 + 1.5 * IQR, а нижнего предела – это Q1 – 1.5 * IQR. Любые значения, превышающие этот предел, считаются выбросами.
Для лучшего понимания мы можем использовать ящик с усами, чтобы понять обнаружение выбросов с помощью IQR.
sns.boxplot(tips['tip'])
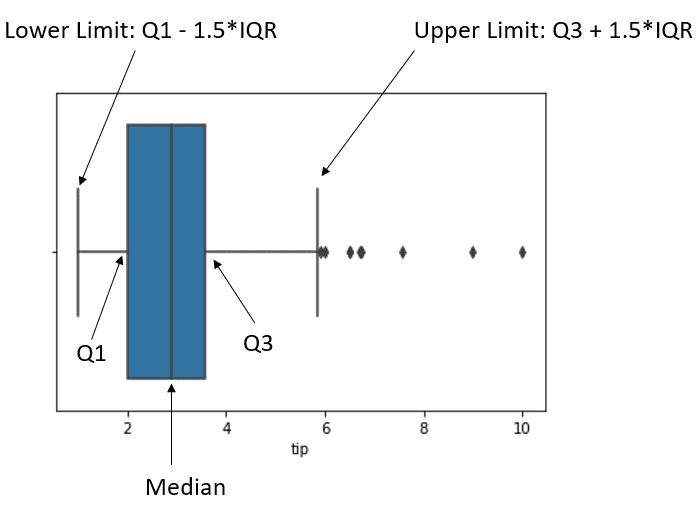
На приведенном выше изображении показана диаграмма размаха данных и положение данных. Черная точка после верхнего предела – это то, что мы считаем выбросом.
Инференциальная статистика
Инференциальная статистика – это раздел, который обобщает информацию о популяции на основе выборки данных, полученных из нее. Инференциальная статистика используется, потому что часто невозможно получить все данные популяции, и нам нужно делать выводы из выборки данных. Например, мы хотим понять, какие мнения у индонезийских людей о искусственном интеллекте. Однако исследование займет слишком много времени, если мы опросим всех людей в индонезийской популяции. Поэтому мы используем выборочные данные, представляющие популяцию, и делаем выводы о мнении индонезийской популяции о искусственном интеллекте.
Давайте изучим различные инференциальные статистики, которые мы могли бы использовать.
1. Стандартная ошибка
Стандартная ошибка – это измерение инференциальной статистики, предназначенное для оценки истинного параметра популяции на основе выборочной статистики. Информация о стандартной ошибке заключается в том, как статистика выборки будет варьироваться, если мы повторим эксперимент с выборками данных из одной и той же популяции.
Стандартная ошибка среднего (SEM) является наиболее часто используемым типом стандартной ошибки, поскольку она показывает, насколько хорошо среднее значение будет представлять популяцию на основе выборочных данных. Чтобы рассчитать SEM, мы будем использовать следующее уравнение.
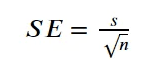 Изображение автора
Изображение автора
Стандартная ошибка среднего будет использовать стандартное отклонение для расчета. Стандартная ошибка данных будет меньше, чем больше количество выборки, где меньший SE означает, что наша выборка будет отлично представлять популяцию данных.
Чтобы получить стандартную ошибку среднего, мы можем использовать следующий код.
from scipy.stats import sem
round(sem(tips['tip']),3)
0.089
Мы часто сообщаем SEM вместе с средним значением данных, где истинное среднее значение популяции будет оцениваться в диапазоне от среднего значения + SEM до среднего значения – SEM.
data_mean = round(tips['tip'].mean(),3)
data_sem = round(sem(tips['tip']),3)
print(f'Оценивается, что истинное среднее значение популяции находится в диапазоне от {data_mean+data_sem} до {data_mean-data_sem}')Среднее значение истинной генеральной совокупности оценивается в диапазоне от 3.087 до 2.90900000000000032. Доверительный интервал
Доверительный интервал также используется для оценки истинного параметра генеральной совокупности, но он вводит уровень доверия. Уровень доверия оценивает диапазон истинных параметров генеральной совокупности с определенным процентом доверия.
В статистике доверие может быть описано как вероятность. Например, доверительный интервал с уровнем доверия 90% означает, что истинная оценка среднего значения генеральной совокупности будет находиться в пределах верхних и нижних значений доверительного интервала в 90 случаях из 100. Доверительный интервал рассчитывается по следующей формуле.
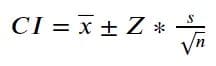 Изображение Автора
Изображение Автора
Формула выше имеет знакомую нотацию, за исключением Z. Обозначение Z – это Z-оценка, полученная путем определения уровня доверия (например, 95%) и использования таблицы критических значений Z-оценки для определения Z-оценки (1.96 для уровня доверия 95%). Кроме того, если наша выборка мала или меньше 30, мы должны использовать таблицу t-распределения.
Мы можем использовать следующий код для получения доверительного интервала с помощью Python.
import scipy.stats as st
st.norm.interval(confidence=0.95, loc=data_mean, scale=data_sem)(2.8246682963727068, 3.171889080676473)Вышеуказанный результат можно интерпретировать так, что истинное среднее значение генеральной совокупности наших данных находится в диапазоне от 2.82 до 3.17 с уровнем доверия 95%.
3. Проверка гипотез
Проверка гипотез является методом в выводной статистике для получения выводов из выборок данных о генеральной совокупности. Оцениваемая генеральная совокупность может быть параметром генеральной совокупности или вероятностью.
При проверке гипотез нам нужно иметь предположение, называемое нулевой гипотезой (H0), и альтернативную гипотезу (Ha). Нулевая гипотеза и альтернативная гипотеза всегда противоположны друг другу. Затем процедура проверки гипотезы использовала бы выборочные данные для определения того, можно ли отклонить нулевую гипотезу или мы не можем отклонить ее (что означает, что мы принимаем альтернативную гипотезу).
Когда мы применяем метод проверки гипотезы, чтобы увидеть, должна ли быть отклонена нулевая гипотеза, нам нужно определить уровень значимости. Уровень значимости – это максимальная вероятность первого рода ошибки (отклонение H0, когда H0 истинна), которая разрешена в тесте. Обычно уровень значимости составляет 0,05 или 0,01.
Для получения вывода из выборки проверка гипотезы использует P-значение при предположении, что нулевая гипотеза истинна, чтобы измерить, насколько вероятны результаты выборки. Когда P-значение меньше уровня значимости, мы отклоняем нулевую гипотезу; в противном случае мы не можем отклонить ее.
Проверка гипотез – это метод, который может выполняться для любого параметра генеральной совокупности и может выполняться также для нескольких параметров. Например, нижеприведенный код выполнит t-тест для двух разных генеральных совокупностей, чтобы увидеть, являются ли эти данные значительно отличными от других.
st.ttest_ind(tips[tips['sex'] == 'Male']['tip'], tips[tips['sex'] == 'Female']['tip'])Ttest_indResult(statistic=1.387859705421269, pvalue=0.16645623503456755)В t-тесте мы сравниваем средние значения между двумя группами (парный тест). Нулевая гипотеза для t-теста заключается в том, что нет различий между средними значениями двух групп, в то время как альтернативная гипотеза состоит в том, что есть различия между средними значениями двух групп.
Результат теста показывает, что чаевые между мужчинами и женщинами не значительно отличаются, так как P-значение выше уровня значимости 0,05. Это означает, что мы не смогли отклонить нулевую гипотезу и заключаем, что нет различий между средними значениями двух групп.
Конечно, приведенный выше тест упрощает пример проверки гипотезы. Есть много предположений, о которых нам нужно знать при выполнении проверки гипотезы, и есть много тестов, которые мы можем провести для удовлетворения наших потребностей.
Заключение
В области статистики выделяются две основные ветви: описательная и инференциальная статистика. Описательная статистика занимается суммированием данных, в то время как инференциальная статистика обобщает данные для получения выводов о популяции. В этой статье мы обсудим описательную и инференциальную статистику, приведя примеры с использованием языка программирования Python. Корнелиус Юдха Виджая является помощником руководителя по науке о данных и автором данных. В свободное время, работая на полную ставку в Allianz Indonesia, он любит делиться советами по использованию Python и работой с данными через социальные сети и публикации.






