Data Morph Переходя за пределы «Дюжины Датасаурусов»
Переход за пределы «Дюжины Датасаурусов»

Примечание редактора: Стефани Молин выступает на конференции ODSC West 2023 этой осенью. Обязательно посмотрите ее доклад “Data Morph: A Cautionary Tale of Summary Statistics”!
В этой статье представлен новый пакет на языке Python с открытым исходным кодом под названием Data Morph, который можно использовать для преобразования набора данных из двумерных точек в определенные формы, сохраняя при этом сводные статистические данные до определенного количества десятичных знаков с помощью имитации отжига. Data Morph расширяет исследования компании Autodesk по созданию набора данных Datasaurus Dozen и предназначен для использования в качестве учебного материала для иллюстрации того, почему нельзя полагаться только на сводные статистические данные.
Давайте сыграем в игру. Я думаю о распределении со следующими сводными статистическими данными. Вы можете представить, как будет выглядеть диаграмма рассеяния этих данных?
- Упрощение анализа временных рядов для ученых-данных
- 5 портфельных проектов для студентов последнего курса факультета науки о данных
- Визуализация данных теория и техники
- Среднее значение X = 30.37
- Среднее значение Y = 53.01
- Стандартное отклонение X = 13.44
- Стандартное отклонение Y = 15.53
- Коэффициент корреляции Пирсона = 0.04
Среднее значение является мерой центральности, стандартное отклонение – мерой разброса от центра, а корреляция количественно характеризует, как две переменные x и y движутся вместе, поэтому соблазнительно думать, что это достаточно для описания данных. Однако эти сводные статистические данные недостаточны: для заданного набора сводных статистических данных существует несколько возможных наборов данных. Вот диаграмма рассеяния данных, которые я резюмировал – вы угадали?

Набор данных по музыке, предоставленный Data Morph.
Идея того, что нельзя полагаться только на сводные статистические данные, не нова. Исследователи показали это, создавая множество наборов данных, которые визуально очень различны, но имеют одни и те же сводные статистические данные. В 1973 году Фрэнсис Энском представил набор из четырех таких наборов данных, который известен как Квартет Энскома:
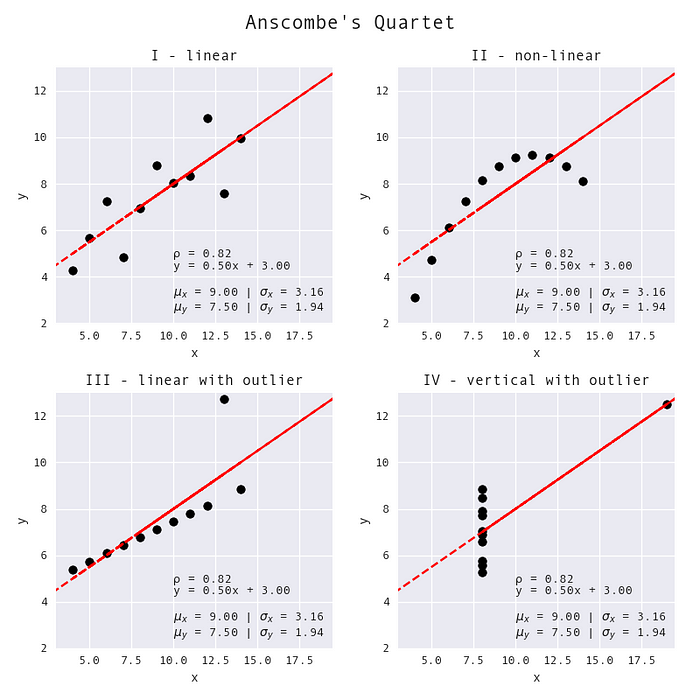
Каждый из этих наборов данных визуально очень различается, однако все они имеют одни и те же сводные статистические данные. (Это изображение было создано Стефани Молин с использованием набора данных Квартета Энскома, предоставленного в seaborn.)
В 2017 году исследователи компании Autodesk развили идею Квартета Энскома, создав набор точек в форме динозавра (Datasaurus Альберто Каиро) и превратив его в 12 различных форм с использованием имитации отжига, которая является техникой поиска глобальных оптимумов, в проекте Same Stats, Different Graphs:
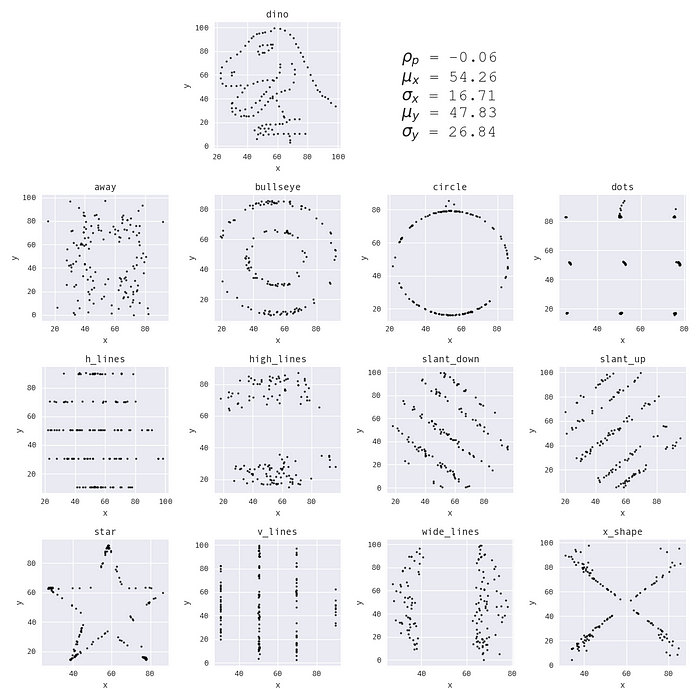
Набор данных Datasaurus Dozen. (Это изображение было создано Стефани Молин с использованием набора данных Datasaurus Dozen, предоставленного jmatejka/same-stats-different-graphs.)
Для создания набора данных Datasaurus Dozen алгоритм повторно выбирает точку из набора данных случайным образом и пытается переместить ее в новую позицию, незначительно изменяя ее случайным образом. Чтобы новая позиция была принята, изменение сводных статистических данных должно быть достаточно малым, чтобы старые и новые значения по-прежнему были эквивалентны двум десятичным знакам. Если изменение позиции уменьшает расстояние до целевой формы, то алгоритм перемещает эту точку в новую позицию. Однако, если оно увеличивает расстояние до целевой формы, алгоритм будет перемещать точку в новую позицию только с некоторой вероятностью, которая уменьшается со временем. В начальных итерациях алгоритм более вероятно принимает новые позиции, которые удаляют его от целевой формы; по мере прохождения итераций эта вероятность уменьшается. Этот процесс помогает избежать застревания в локальных оптимумах и позволяет создавать более разнообразные формы, так как исследуется больше пространства.
По сравнению с Квартетом Энскома, наблюдать, как Datasaurus превращается в набор наклонных линий, сохраняя сводные статистические данные, вызывает большее ощущение шока. Я считаю, что этот фактор шока более эффективен, когда речь идет о объяснении необходимости визуализации данных – просто посмотрите на реакции на этот пост в LinkedIn.
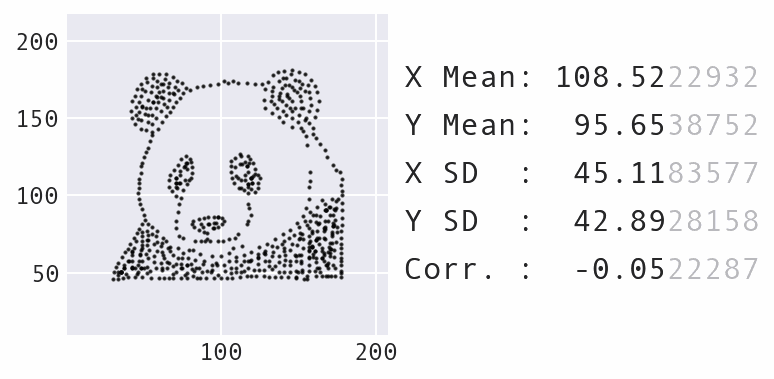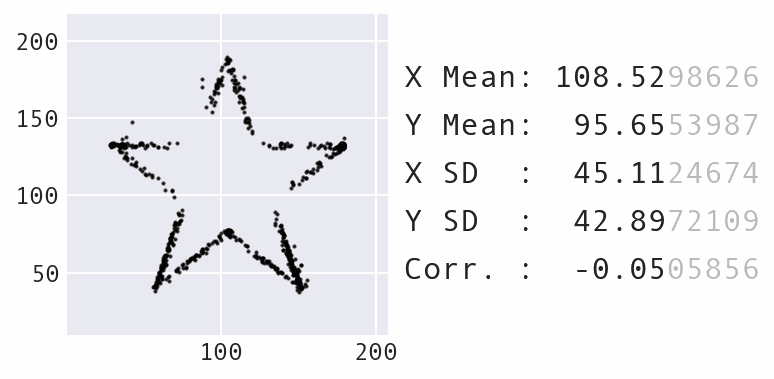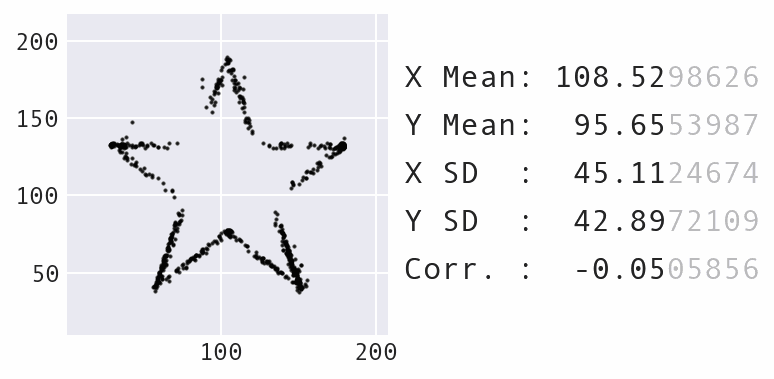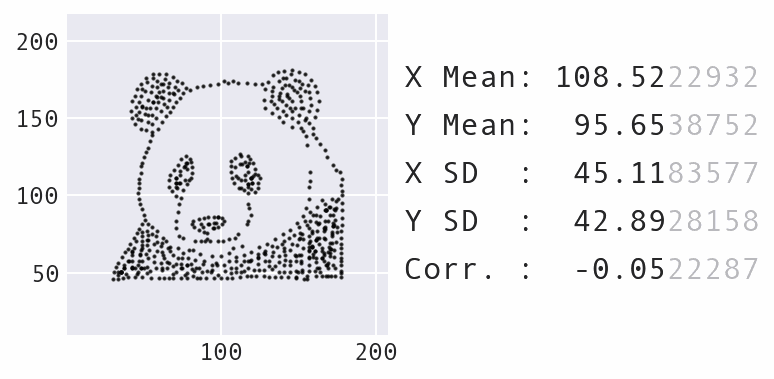
Я хотел использовать этот шокирующий фактор в моем семинаре о пандас для мотивации раздела о визуализации данных. После раздела о обработке данных, важно подчеркнуть важность визуализации данных в этот момент, потому что написание визуализаций может быть более сложным. Люди часто искушены использовать только сводные статистики для описания данных. Однако использование динозавра для анимации не соответствовало концепции семинара, который изображает панду на протяжении всего семинара – мне нужно было создать набор данных, сформированный в форме панды. Я дал несколько советов о том, как перейти от идеи к входному набору данных здесь.
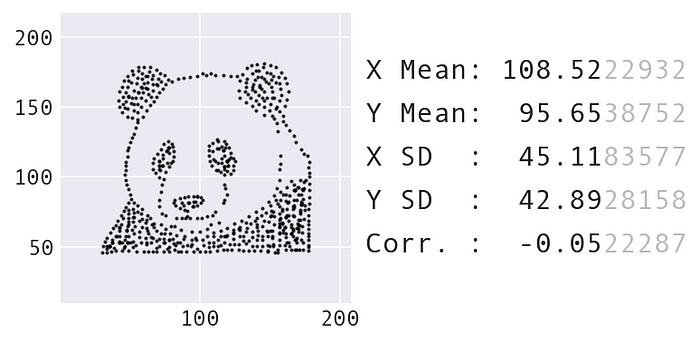
Новый исходный набор данных, сформированный в форме панды.
Я быстро понял, что индивидуальные, влиятельные визуальные средства не только помогут моему семинару, но и тем, кто учится и преподает анализ данных. Так что в 2023 году я исследовал, как код от исследователей Autodesk можно обобщить для произвольного набора данных, т.е. вместо Datasaurus или панды. Это привело меня к созданию Data Morph, открытого пакета на языке Python, который может использоваться для преобразования входного набора данных из 2D точек в выбранные формы, сохраняя сводные статистики с заданным числом десятичных знаков с использованием той же техники имитационного отжига.
Требовалось значительное рефакторинг для обобщения кода Same Stats, Different Graphs, чтобы он работал с другим входом. Весь логический код для целевых форм (думайте о центре и радиусе для круга, конечных точках для линии и т.д.) был встроен в код и был, следовательно, специфичен для наборов данных, включенных в код команды Autodesk. Положение и атрибуты целевых форм должны быть рассчитаны на основе исходного набора данных, причем некоторые формы намного проще кодировать, чем другие. Например, для преобразования в форму круга центр круга может находиться в среднем значении значений x и y, радиус может быть кратным стандартному отклонению (x или y, выберите одно):
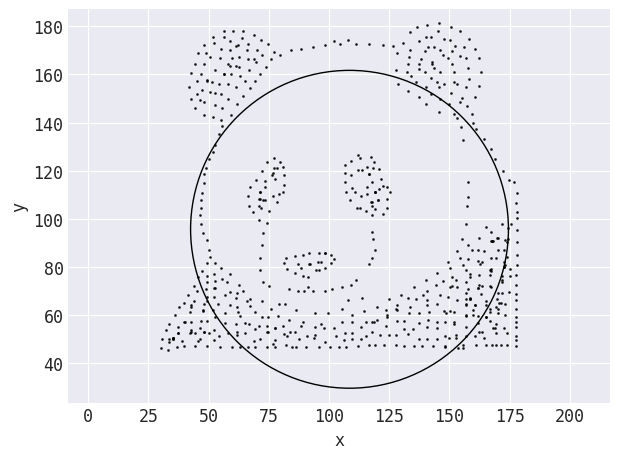
Целевая форма, рассчитанная Data Morph при попытке преобразовать показанную ранее панду в круг. Расстояния рассчитываются от точек до линии, образующей круг.
Data Morph предоставляет иерархию классов форм для создания составных форм (например, форма круга используется для создания формы мишени, которая состоит из двух концентрических окружностей) и централизации расчета расстояний для оптимизации кода. Однако для некоторых форм использование информации из данных не всегда работает: иногда точки должны перемещаться за пределы исходного набора данных. Для обработки такой логики Data Morph включает автоматические расчеты границ, в которые включаются формы и функциональность графического представления:
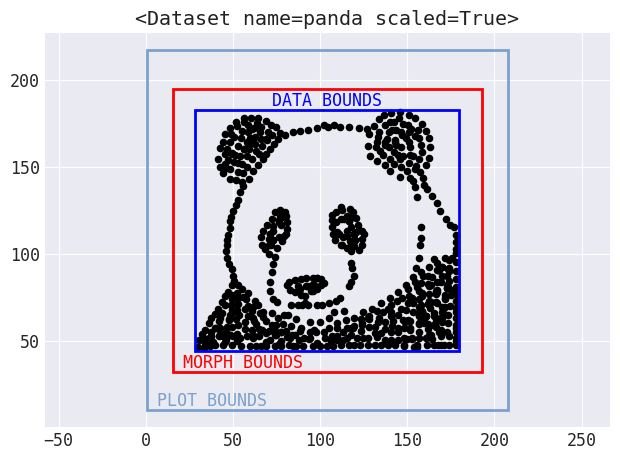
Пределы автоматически рассчитываются для использования при преобразовании и построении графиков.
Еще одно большое изменение заключалось в уменьшении максимального количества перемещений точек со временем, а не в его статическом сохранении, что создает более приятный визуальный эффект при перемещении точек. Вот пример преобразования набора данных панды в звезду:
Преобразование набора данных панды в звезду с помощью Data Morph.
Как показывает анимация выше, панда и звезда имеют не только одинаковые сводные статистики, но и каждый отдельный набор данных, с которым они встречаются в процессе преобразования. В сочетании с тем, что панда также может превратиться в несколько других узнаваемых форм, например, в круг, показанный ранее, у вас есть бесконечное количество возможных наборов данных, соответствующих сводным статистикам.
Однако есть некоторые ограничения: вы не всегда можете преобразовать набор данных во все целевые формы, предлагаемые Data Morph. Если в определенной области, входящей в целевую форму, нет точек из исходной формы, может оказаться невозможным переместить точки туда без изменения сводных статистик. Например, при преобразовании некоторого входного набора данных в форму прямоугольника, некоторые части линии(линий) могут отсутствовать. Используя различные входные наборы данных, вы приобретете интуицию о том, какие формы будут работать и какие нет (и почему).
На данный момент Data Morph поставляется с 6 встроенными формами и 15 целевыми формами, и количество форм будет увеличиваться. Преобразование такое простое:
$ pip install data-morph-ai
$ data-morph --start-shape panda --target-shape starПроизвольные/настраиваемые начальные формы могут быть предоставлены через файлы CSV, например, такой (см. документацию здесь для советов по созданию своих собственных):
Пример, созданный с использованием файла CSV.
Data Morph также предоставляет документацию для использования как в командной строке, так и в интерпретаторе Python, набор тестов, модульный код и гибкую иерархию классов для добавления новых целевых форм. Более подробную информацию о основных улучшениях можно найти в заметках о выпуске здесь.
В следующий раз, когда вы будете объяснять или преподавать суммарную статистику, приглашаю вас использовать Data Morph для создания интересной настраиваемой анимации, чтобы подчеркнуть важность визуализации данных. Попросите студентов или участников предложить свои собственные анимации. Видение множества примеров, начинающихся с знакомых форм (например, логотип вашей школы, талисман и т. д.), будет помогать сохранять эту важную концепцию в голове. Если вы используете Data Morph с настраиваемым набором данных и/или для образовательных целей, буду рад услышать об этом – отметьте меня в своих постах на LinkedIn или Twitter.
Счастливого морфинга!
Статья изначально опубликована здесь. Перепубликовано с разрешения.
 Стефани Молин – программист и специалист по обработке данных в Bloomberg в Нью-Йорке, где она решает сложные проблемы в области информационной безопасности, особенно те, которые связаны с обработкой/визуализацией данных, созданием инструментов для сбора данных и обменом знаниями. Она также является автором книги “Hands-On Data Analysis with Pandas”, которая в настоящее время находится во втором издании. Она имеет степень бакалавра по исследованию операций от Факультета инженерии и прикладных наук Университета Колумбии, а также степень магистра по компьютерным наукам с особым уклоном в машинном обучении от Технологического института Джорджии. В свободное время она любит путешествовать по миру, изобретать новые рецепты и изучать новые языки, используемые как людьми, так и компьютерами.
Стефани Молин – программист и специалист по обработке данных в Bloomberg в Нью-Йорке, где она решает сложные проблемы в области информационной безопасности, особенно те, которые связаны с обработкой/визуализацией данных, созданием инструментов для сбора данных и обменом знаниями. Она также является автором книги “Hands-On Data Analysis with Pandas”, которая в настоящее время находится во втором издании. Она имеет степень бакалавра по исследованию операций от Факультета инженерии и прикладных наук Университета Колумбии, а также степень магистра по компьютерным наукам с особым уклоном в машинном обучении от Технологического института Джорджии. В свободное время она любит путешествовать по миру, изобретать новые рецепты и изучать новые языки, используемые как людьми, так и компьютерами.







{kind=link}