Исследователи Google представляют новый подход искусственного интеллекта к моделированию предпочтения изображения в динамике сцены
Google researchers present a new approach to artificial intelligence in modeling image preferences in dynamic scenes.


Даже на первый взгляд неподвижные изображения содержат мельчайшие колебания из-за таких вещей, как ветер, течения воды, дыхание или другие природные ритмы. Это происходит потому, что природа постоянно движется. Человек особенно чувствителен к движению, что делает его одним из наиболее заметных визуальных сигналов. Изображения, снятые без движения (или даже с некоторым фантастическим движением), иногда кажутся тревожными или сюрреалистическими. Однако людям легко воспринимать или представлять движение в сцене. Обучение модели улавливать реалистичное движение является более сложной задачей. Физическая динамика сцены или силы, действующие на объекты из-за их конкретных физических характеристик, таких как масса, упругость и т. д., создают движение, которое люди видят во внешнем мире.
Эти силы и свойства сложно количественно описать и зафиксировать в масштабе, но, к счастью, часто не требуется точного описания, так как они могут быть уловлены и изучены на основе наблюдаемого движения. Хотя это наблюдаемое движение многомодально и основано на сложных физических процессах, оно часто предсказуемо: свечи мерцают в определенных узорах, а деревья колышутся и шевелят своими листьями. Из статичного изображения они могут представить правдоподобные движения, которые могли происходить в момент съемки, или, если возможно было несколько таких движений, распределение естественных движений, условионированных этим изображением. Эта предсказуемость вложена в их восприятие реальных сцен.
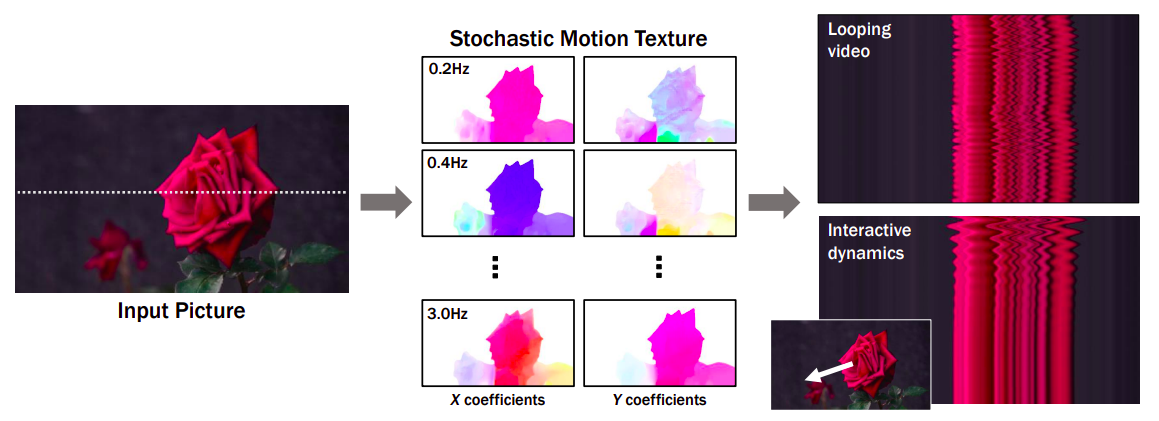
Рисунок 1: Можно увидеть, как метод симулирует генеративный приоритет в пространстве изображений для динамики сцены. Начиная с одного RGB-изображения, модель создает нейронную стохастическую текстуру движения, представление движения, которое симулирует плотные долгосрочные траектории движения в пространстве Фурье. Они демонстрируют, как их приоритеты движения можно использовать для таких задач, как преобразование одного изображения в плавно циклическое видео или имитация динамики объекта в ответ на интерактивное пользовательское воздействие (например, перетаскивание и отпускание точки объекта). Они используют пространственно-временные срезы X-t в течение 10 секунд видео (вдоль отображаемой на входном изображении линии сканирования) для визуализации выходных фильмов справа.
- Каталог генетических мутаций для определения причины заболеваний
- Что дальше в проектировании белков? Исследователи Microsoft представляют EvoDiff революционный фреймворк искусственного интеллекта для инженерии белков на основе последовательности.
- Исследователи из Университета Мэриленда и Meta AI предлагают OmnimatteRF новый метод видео-матирования, который объединяет динамические 2D передние слои и 3D модель фона.
Симулировать подобное распределение в цифровой форме – это естественный объект исследования, учитывая, насколько легко люди могут представлять себе эти потенциальные движения. Благодаря последним достижениям в области генеративных моделей, особенно условных моделей диффузии, мы теперь можем симулировать чрезвычайно богатые и сложные распределения, включая распределения реальных изображений, условионированных по тексту. Благодаря этой возможности стали возможными многие ранее невозможные применения, включая условное создание случайного, разнообразного и реалистичного визуального материала. Недавние исследования показали, что моделирование дополнительных областей, таких как видео и 3D-геометрия, может быть так же полезным для последующих применений в свете успеха этих моделей изображений.
В этой статье исследователи из Google Research исследуют моделирование генеративного приоритета для движения каждого пикселя на одном изображении, также известного как движение сцены в пространстве изображений. Эта модель обучается с использованием автоматически извлеченных траекторий движения из большого количества реальных видео последовательностей. Обученная модель прогнозирует нейронную стохастическую текстуру движения на основе входного изображения, набора коэффициентов движения, описывающих будущую траекторию каждого пикселя. Они выбирают ряд Фурье в качестве своих базисных функций, чтобы ограничить свой анализ реальными сценами с колеблющейся динамикой, такими как деревья и цветы, движущиеся на ветру. Они прогнозируют нейронную стохастическую текстуру движения с использованием модели диффузии, которая создает коэффициенты для одной частоты за один раз, но координирует эти прогнозы по частотным полосам.
Как показано на рис. 1, сгенерированные текстуры в пространстве частот могут быть преобразованы в плотные долгосрочные траектории движения пикселей, синтезируя предстоящие кадры с помощью модели рендеринга на основе изображений, превращая статические изображения в живописные анимации. Приоритеты движения захвата имеют более простую, более низкоразмерную внутреннюю структуру, чем приоритеты для обработки сырых RGB-пикселей, что более эффективно объясняет флуктуации значений пикселей. В отличие от ранее использовавшихся методов, осуществляющих визуальную анимацию с использованием синтеза сырого видео, их представление движения позволяет более связанное долгосрочное производство и более тонкую контроль над анимациями. Кроме того, они показывают, как их сгенерированное представление движения легко использовать для различных последующих применений, включая создание видео с плавным циклом, редактирование вызванного движения и создание интерактивных динамических изображений, которые имитируют реакцию объекта на силы, приложенные пользователем.






