Почему вашим потокам данных нужна обратная связь в замкнутом контуре управления
Зачем обратная связь в замкнутом контуре управления для ваших данных
Реальности сложностей компании и облака требуют новых уровней контроля и автономии для достижения бизнес-целей в масштабе
По мере масштабирования команды данных в облаке, команде платформы данных необходимо обеспечить выполнение рабочих нагрузок, за которые они отвечают, с учетом бизнес-целей. В масштабе с десятками инженеров данных, создающих сотни производственных заданий, контроль их работы в масштабе становится невозможным по множеству причин, от технических до человеческих.
Отсутствующим звеном на сегодняшний день является создание системы обратной связи, которая автоматически помогает направлять инфраструктуру конвейера к бизнес-целям. Было сказано много слов, давайте углубимся и более конкретно рассмотрим эту проблему.
Проблема для команды платформы данных сегодня
Команды платформы данных должны управлять фундаментально разными заинтересованными сторонами, от руководства до инженеров. Часто эти две команды имеют противоположные цели, и менеджеры платформы могут быть под давлением с обеих сторон.
- Как хранить исторические данные более эффективно
- Построение рекомендателя для данных с неявной обратной связью
- Принципы управления данными для науки о данных
Многие реальные разговоры, которые мы вели с менеджерами платформы и инженерами данных, обычно проходили следующим образом:
«Наш генеральный директор хочет, чтобы я снизил затраты на облако и убедился, что наши SLA соблюдаются, чтобы наши клиенты были довольны».
Хорошо, а в чем проблема?
«Проблема в том, что я фактически не могу изменить ничего напрямую, мне нужна помощь других людей, и это узкое место»
Таким образом, команды платформы оказываются связанными и сталкиваются с огромным трением при попытке реализовать улучшения. Давайте рассмотрим причины подробнее.
Что мешает команде платформы?
- Команды данных выходят за рамки технического уровня — Настройка кластеров или сложных конфигураций (Databricks, Snowflake) является трудоемкой задачей, на которую команды данных предпочли бы сосредоточиться на реальных конвейерах и SQL-коде. Многие инженеры не обладают необходимыми навыками, структурой поддержки или даже не знают, сколько стоят их задания. Выявление и решение проблем корневой причины также является сложной задачей, которая мешает созданию функционального конвейера.
- Слишком много уровней абстракции — Давайте сосредоточимся на одном стеке: Databricks использует собственную версию Apache Spark, который работает на виртуализированном вычислении облачного провайдера (AWS, Azure, GCP) с различными вариантами сети и хранения (DBFS, S3, Blob), и к тому же все может быть обновлено независимо и случайным образом в течение года. Количество вариантов ошеломляет, и платформенным специалистам невозможно гарантировать, что все обновлено и оптимально.
- Устаревший код — Одна неприятная реальность – это просто устаревший код. Часто в компании меняются команды, люди приходят и уходят, и со временем знания о любом конкретном задании пропадают. Это делает еще более сложным настройку или оптимизацию конкретного задания.
- Страх перед изменениями — Имеется врожденный страх перед изменениями. Если производственное задание выполняется, хотим ли мы рисковать его настройкой? Приходит на ум старая поговорка: «если это работает, не трогай». Часто этот страх реален, если задание не является идемпотентным или есть другие последствия, неудачное задание может вызвать серьезные проблемы. Это создает психологический барьер, мешающий даже попытке улучшить производительность задания.
- На большом масштабе слишком много заданий — Обычно менеджеры платформы надзирают за сотнями, а то и тысячами производственных заданий. Будущий рост компании гарантирует увеличение этого числа. Учитывая все вышеупомянутые факторы, даже если у вас есть местный эксперт, подход с настройкой заданий по одному просто нереалистичен. Хотя это может сработать для нескольких заданий с высоким приоритетом, остальные задачи компании остаются больше или менее без внимания.
Очевидно, что командам платформы данных трудно быстро сделать свои системы более эффективными в масштабе. Мы считаем, что решением является парадигмальный сдвиг в способе создания конвейеров. Конвейерам необходима система управления обратной связью, которая постоянно направляет конвейер к бизнес-целям без участия людей. Давайте разберемся.
Что означает система управления обратной связью для конвейера?
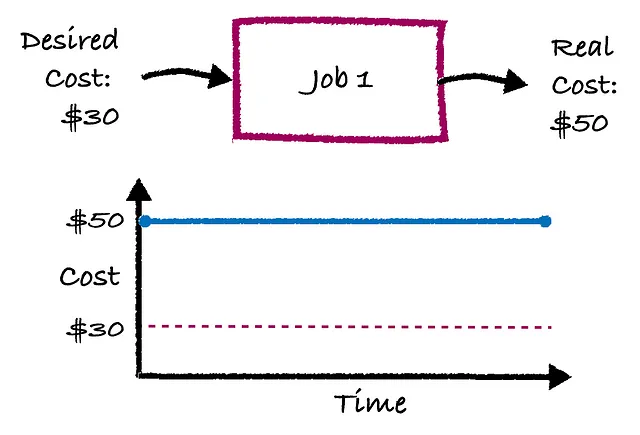
Сегодняшние конвейеры представляют собой то, что называется “открытой петлей” системы, в которой задания просто выполняются без обратной связи. Чтобы проиллюстрировать то, о чем я говорю, на рисунке ниже показано, что “Задание 1” выполняется каждый день, с затратами $50 за выполнение. Допустим, бизнес-цель состоит в том, чтобы это задание стоило $30. Ну, пока кто-то не сделает что-то на самом деле, эти затраты останутся на уровне $50 в обозримом будущем, как видно на графике затрат по времени.
Что, если вместо этого у нас была система, которая фактически обратно подавала статистику вывода задания, чтобы улучшить развертывание на следующий день? Это будет выглядеть примерно так:
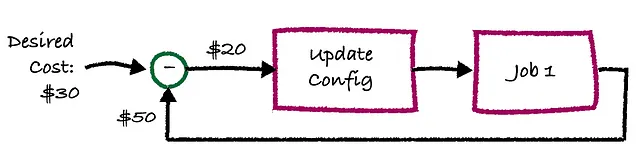
Здесь вы видите классическую обратную связь, где в данном случае желаемая “точка установки” – это затраты в размере $30. Поскольку это задание выполняется каждый день, мы можем взять обратную связь от реальных затрат и отправить ее на блок “обновление конфигурации”, который принимает разницу в затратах (в данном случае $20) и в результате применяет изменение в конфигурациях “Задания 1”. Например, блок “обновление конфигурации” может уменьшить количество узлов в кластере Databricks.
Как это выглядит в производстве?
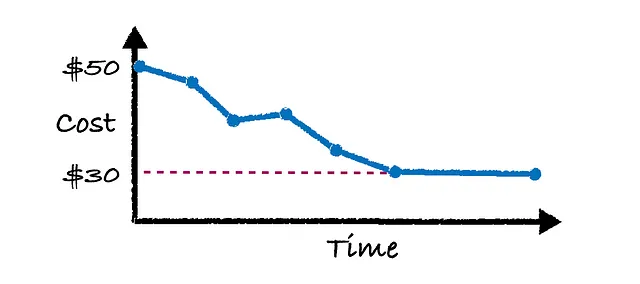
На самом деле, это не происходит сразу. Модель “обновления конфигурации” теперь отвечает за настройку инфраструктуры для попытки снизить затраты до $30. Как вы можете себе представить, со временем система будет улучшаться и в конечном итоге достигнет желаемых затрат в размере $30, как показано на изображении ниже.
Это может звучать прекрасно, но вы можете задаться вопросом “что такое этот волшебный блок “обновления конфигурации”? Вот где происходит определение. Этот блок представляет собой математическую модель, которая может принимать числовое изменение цели и выдавать конфигурацию инфраструктуры или, возможно, изменение кода.
Это не просто, и оно будет различаться в зависимости от цели (например, затраты по времени выполнения по использованию). Эта модель должна основательно предсказывать влияние изменения инфраструктуры на бизнес-цели – что не так просто.
Никто не может предсказать будущее
Одно тонкое обстоятельство заключается в том, что ни одна модель “обновления конфигурации” не является 100% точной. На 4-м синем точке можно даже видеть, что в какой-то момент затраты возрастают. Это происходит потому, что модель пытается предсказать изменение конфигураций, которое снизит затраты, но поскольку никто не может предсказать с абсолютной точностью, иногда она будет неправильной на локальном уровне, и в результате затраты могут увеличиться для одного выполнения, пока система находится в “тренировке”.
Но со временем мы видим, что общая стоимость действительно снижается. Вы можете рассматривать это как интеллектуальный процесс проб и ошибок, поскольку предсказать влияние изменений конфигурации с абсолютной точностью просто невозможно.
Великое “так что?” – Установите любую цель и идите
Предложенный выше подход является общей стратегией и не ограничен только экономией затрат. “Точка установки” выше – это просто цель, которую устанавливает сотрудник платформы данных. Она может быть любой измеримой целью, например, время выполнения – отличный пример.
Допустим, мы хотим, чтобы задание выполнялось менее чем за 1 час (или SLA). Мы можем позволить системе выше настраивать конфигурации, пока SLA не будет достигнуто. А что, если это сложнее, например, одновременно учет затрат и SLA? Все в порядке, система может оптимизировать достижение ваших целей по многим параметрам. Помимо затрат и времени выполнения, другие деловые цели использования:
- Использование ресурсов: Независимо от стоимости и времени выполнения, я правильно использую имеющиеся у меня ресурсы?
- Энергоэффективность: Я потребляю минимальное количество ресурсов для минимизации углеродного следа?
- Отказоустойчивость: Насколько моя задача устойчива к сбоям? Означает ли это, что я хочу переуказать ее на случай, если произойдет прерывание или в случае отсутствия доступных экземпляров SPOT?
- Масштабируемость: Может ли моя задача масштабироваться? Что, если объем входных данных увеличится в 10 раз, разобьется ли моя задача?
- Задержка: Удовлетворяют ли мои задачи заданным временным ограничениям и целям по времени отклика?
В теории, всем, кто связан с платформой обработки данных, нужно всего лишь установить цели, и затем автоматическая система может итеративно улучшать инфраструктуру до достижения этих целей. В этом нет необходимости в участии людей, вовлечении инженеров. Команда платформы просто устанавливает цели, полученные от заинтересованных сторон. Звучит как мечта.
Пока мы были довольно абстрактными. Давайте перейдем к некоторым конкретным примерам, которые, надеюсь, будут убедительными для людей:
Пример функции №1: Группировка задач по бизнес-целям
Предположим, вы являетесь менеджером платформы обработки данных и отвечаете за работу сотен производственных задач. В настоящее время все они имеют свою собственную стоимость и время выполнения. Простая диаграмма ниже показывает карикатурный пример, где практически все задачи случайным образом распределены на графике стоимости и времени выполнения.
Что, если вы хотите снизить затраты в масштабе? Что, если вы хотите одновременно изменить время выполнения (или SLA) нескольких задач? В данный момент вам придется умолять инженеров помочь вам изменить все задачи (удачи).
Теперь представьте, что у вас реализована такая система управления с обратной связью для всех ваших задач. Вам нужно только установить высокоуровневые бизнес-цели ваших задач (в данном случае требования к времени выполнения SLA), и система обратной связи будет делать все возможное, чтобы найти инфраструктуру, достигающую ваших целей. Конечное состояние будет выглядеть так:
Здесь каждый цвет задачи представляет собой разные бизнес-цели, определенные SLA. Система управления с обратной связью за кулисами изменяла размер кластера/склада, различные конфигурации или даже настраивала целые конвейеры, чтобы достичь целей времени выполнения SLA при минимальных затратах. Обычно более длительное время выполнения задачи предоставляет возможности для снижения затрат.
Пример функции №2: Автоматическое восстановление задач
Как могут подтвердить большинство людей, связанных с платформой обработки данных, в их конвейерах данных всегда что-то меняется. Два очень популярных сценария – увеличение размера данных со временем и изменения кода. Оба могут вызывать неустойчивое поведение в отношении стоимости и времени выполнения.
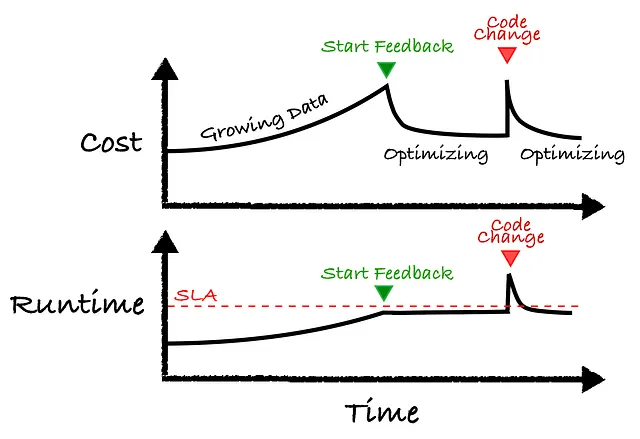
Ниже показана основная концепция. Давайте пройдемся по примеру слева направо:
- Начало: Предположим, у вас есть задача, и с течением времени размер данных увеличивается. Обычно ваш кластер остается неизменным, и в результате и стоимость, и время выполнения увеличиваются.
- Обратная связь с начала: С течением времени время выполнения приближается к требованию SLA, и система управления с обратной связью включается на зеленую стрелку. На этом этапе система управления изменяет кластер так, чтобы оставаться ниже пунктирной красной линии, минимизируя затраты.
- Изменение кода: В какой-то момент разработчик вносит новое обновление в код, что вызывает резкий рост стоимости и времени выполнения. Система управления с обратной связью включается и настраивает кластер для лучшей работы с новым изменением кода.
Надеюсь, эти два примера объясняют потенциальную выгоду от использования системы управления с обратной связью. Конечно, на практике существует множество деталей, которые были опущены, и принципы проектирования, которым компании должны следовать.
Одна из больших проблем заключается в возможности возвращения конфигураций к предыдущему состоянию в случае возникновения проблем. Здесь идеально подходит идемпотентная конвейерная линия, если требуется множество итераций.
Заключение
Конвейеры данных – это сложные системы, и, как и любая другая сложная система, они требуют обратной связи и контроля для обеспечения стабильной работы. Это не только помогает решать технические или бизнес-проблемы, но также значительно помогает освободить команды по работе с данными и инженерии, чтобы они могли фактически строить конвейеры.
Как мы уже упоминали ранее, многое зависит от производительности блока “обновления конфигурации”. Это критически важная часть информации, необходимая для успеха обратной связи. Построение этого блока не является тривиальной задачей и является основным техническим барьером сегодня. Это может быть алгоритм или модель машинного обучения, использующая исторические данные. Это основной технический компонент, над которым мы работали в течение последних нескольких лет.
В следующей статье мы покажем реальную реализацию этой системы, примененной к задачам Databricks, так что вы можете поверить в то, о чем мы говорим!
Хотите узнать больше о контроле с обратной связью для ваших конвейеров Databricks? Свяжитесь с Джефом Чоу и остальной командой Sync.



