Таксономия обработки естественного языка
Обработка естественного языка
Обзор различных областей и последних разработок в NLP

Этот пост основан на нашей статье RANLP 2023 «Исследование пейзажа исследований обработки естественного языка». Подробности можно прочитать там.
Введение
Как эффективный подход к пониманию, генерации и обработке текстов на естественном языке, исследования в области обработки естественного языка (NLP) показали быстрое распространение и широкое принятие в последние годы. Учитывая быстрые развития в NLP, сложно получить обзор этой области и поддерживать его. Цель этого блог-поста – предоставить структурированный обзор различных областей изучения NLP и проанализировать последние тенденции в этой области.
Области изучения – это академические дисциплины и понятия, которые обычно состоят из задач или техник.
В этой статье мы исследуем следующие вопросы:
- Исследование в Стэнфорде представляет PointOdyssey крупномасштабный синтетический набор данных для долгосрочного отслеживания точек
- 5 бесплатных проектов по науке о данных с решениями
- Исследователи из Университета Орегона и Adobe представили CulturaX многоязычный набор данных с 6,3 трлн. токенов на 167 языках, разработанный специально для создания больших языковых моделей (LLM).
- Какие различные области изучаются в NLP?
- Каковы характеристики и изменения в литературе по исследованиям в NLP со временем?
- Каковы текущие тенденции и направления будущей работы в NLP?
Хотя большинство областей изучения в NLP хорошо известны и определены, на данный момент не существует общепринятой таксономии или схемы категоризации, которая пытается собрать и структурировать эти области изучения в последовательном и понятном формате. Поэтому сложно получить обзор всей области исследований NLP. Хотя существуют списки тем NLP на конференциях и в учебниках, они часто сильно отличаются и часто являются либо слишком общими, либо слишком специализированными. Поэтому мы разработали таксономию, охватывающую широкий спектр различных областей изучения в NLP. Хотя эта таксономия может не включать все возможные концепции NLP, она охватывает широкий спектр наиболее популярных областей изучения, пропущенные области изучения можно считать подтемами включенных областей изучения. В процессе разработки таксономии мы обнаружили, что некоторые области изучения нижнего уровня должны быть присвоены нескольким областям изучения высшего уровня, а не только одной. Поэтому некоторые области изучения перечислены несколько раз в таксономии NLP, но присвоены различным областям изучения высшего уровня. Окончательная таксономия была разработана эмпирически в итеративном процессе вместе с экспертами в области.
Таксономия служит в качестве всесторонней классификационной схемы, в которой публикации NLP могут быть классифицированы по как минимум одной из включенных областей изучения, даже если они не непосредственно затрагивают одну из областей изучения, но только подтемы. Чтобы проанализировать последние разработки в NLP, мы обучили слабо супервизируемую модель для классификации статей ACL Anthology в соответствии с таксономией NLP.
Подробнее о процессе разработки модели классификации и таксономии NLP можно прочитать в нашей статье.
Различные области изучения в NLP 📖
В следующем разделе предоставляются краткие объяснения концепций областей изучения, включенных в таксономию NLP выше.
Мультимодальность
«Мультимодальность относится к способности системы или метода обрабатывать данные различных типов или модальностей» (Garg et al., 2022). Мы различаем системы, которые могут обрабатывать текст на естественном языке вместе с визуальными данными, речью и аудио, языками программирования или структурированными данными, такими как таблицы или графики.
Естественно-языковые интерфейсы
«Естественно-языковые интерфейсы могут обрабатывать данные на основе запросов на естественном языке» (Voigt et al., 2021), обычно реализованные в форме вопросно-ответных или диалоговых и разговорных систем.
Семантическая обработка текста
Эта высокоуровневая область изучения включает все типы концепций, которые пытаются извлекать смысл из естественного языка и позволяют машинам семантически интерпретировать текстовые данные. Одной из самых мощных областей изучения в этом отношении являются «языковые модели, которые пытаются изучить совместную функцию вероятности последовательностей слов» (Bengio et al., 2000). «Последние достижения в обучении языковых моделей позволили этим моделям успешно выполнять различные задачи в области NLP» (Soni et al., 2022). В обучении представлений «семантические текстовые представления обычно изучаются в виде вложений» (Fu et al., 2022), которые «могут использоваться для сравнения семантической схожести текстов в настройках семантического поиска» (Reimers and Gurevych, 2019). Кроме того, «представления знаний, например, в форме графов знаний, могут быть включены для улучшения различных задач NLP» (Schneider et al., 2022).
Анализ настроений
«Анализ настроений пытается определить и извлечь субъективную информацию из текстов» (Wankhade и др., 2022). Обычно исследования сосредоточены на извлечении мнений, эмоций или полярности из текстов. Более недавно появился анализ настроений на основе аспектов как способ предоставить более подробную информацию, чем общий анализ настроений, поскольку «его целью является предсказание полярностей настроения заданных аспектов или сущностей в тексте» (Xue и Li, 2018).
Синтаксическая обработка текста
Это высокоуровневое направление исследований направлено на «анализ грамматического синтаксиса и словаря текстов» (Bessmertny и др., 2016). Представительные задачи в этом контексте включают синтаксический анализ зависимостей между словами в предложениях, маркировку слов по их частям речи, сегментацию текстов на связные разделы или исправление ошибочных текстов с точки зрения грамматики и правописания.
Лингвистика и когнитивная обработка естественного языка
«Лингвистика и когнитивная обработка естественного языка занимаются естественным языком на основе предположения, что наши языковые способности твердо основаны на наших когнитивных способностях, что значение в основном является концептуализацией и что грамматика формируется использованием» (Dabrowska и Divjak, 2015). Существуют различные лингвистические теории, которые обычно утверждают, что «усвоение языка регулируется универсальными грамматическими правилами, которые общие для всех нормально развивающихся людей» (Wise и Sevcik, 2017). «Психолингвистика пытается моделировать, как человеческий мозг усваивает и производит язык, обрабатывает его, понимает его и обеспечивает обратную связь» (Balamurugan, 2018). «Когнитивное моделирование занимается моделированием и симуляцией когнитивных процессов человека в различных формах, особенно в вычислительной или математической форме» (Sun, 2020).
Ответственная и надежная обработка естественного языка
«Ответственная и надежная обработка естественного языка занимается реализацией методов, которые акцентируют внимание на справедливости, объяснимости, отчетности и этических аспектах» (Barredo Arrieta и др., 2020). Зеленая и устойчивая обработка естественного языка в основном нацелена на эффективные подходы к обработке текста, в то время как обработка естественного языка с ограниченными ресурсами стремится выполнять задачи обработки естественного языка, когда данных недостаточно. Кроме того, устойчивость в обработке естественного языка пытается разработать модели, которые нечувствительны к предубеждениям, устойчивы к возмущениям данных и надежны для предсказаний вне распределения.
Рассуждение
Рассуждение позволяет машинам делать логические выводы и извлекать новые знания на основе имеющейся информации, используя такие техники, как дедукция и индукция. «Анализ аргументов автоматически определяет и извлекает структуру логического вывода и рассуждения, выраженного в виде аргументов, представленных в тексте на естественном языке» (Lawrence и Reed, 2019). Текстовый вывод, обычно моделируемый как задача заключения, автоматически определяет, можно ли извлечь естественноязычную гипотезу из заданного предпосылки» (MacCartney и Manning, 2007). «Рассуждение на основе здравого смысла соединяет предпосылки и гипотезы с помощью мировых знаний, которые не являются явно предоставленными в тексте» (Ponti и др., 2020), в то время как «числовое рассуждение выполняет арифметические операции» (Al-Negheimish и др., 2021). «Машинное понимание текста направлено на то, чтобы обучить машины определять правильные ответы на вопросы на основе заданного текста» (Zhang и др., 2021).
Мультиязычность
Мультиязычность решает все типы задач обработки естественного языка, которые включают более одного естественного языка, и обычно изучается в контексте машинного перевода. Кроме того, «смешивание кода свободно перемещает несколько языков в пределах одного предложения или между предложениями» (Diwan и др., 2021), в то время как техники межъязыкового переноса используют данные и модели, доступные для одного языка, для решения задач обработки естественного языка на другом языке.
Поиск информации
«Информационный поиск связан с поиском текстов, которые удовлетворяют информационной потребности в больших коллекциях» (Мэннинг и др., 2008). Обычно это включает извлечение документов или фрагментов.
Извлечение информации и текстовое майнинг
Эта область исследования сосредоточена на извлечении структурированных знаний из неструктурированного текста и «позволяет анализировать и выявлять закономерности или корреляции в данных» (Хассани и др., 2020). «Классификация текста автоматически категоризирует тексты по заранее определенным классам» (Шопф и др., 2021), тогда как «моделирование темы стремится обнаружить скрытые темы в коллекциях документов» (Гротендорст, 2022), часто используя техники кластеризации текста, которые организуют семантически похожие тексты в одни и те же кластеры. «Суммаризация создает краткие изложения текстов, включающие основные точки ввода в меньшем объеме и минимизируют повторения» (Эль-Кассас и др., 2021). Кроме того, извлечение информации и текстовое майнинг также включает «распознавание именованных сущностей, которое занимается идентификацией и категоризацией именованных сущностей» (Лейтнер и др., 2020), «разрешение синонимии, которое стремится идентифицировать все ссылки на одну и ту же сущность в дискурсе» (Йин и др., 2021), «извлечение терминов, которое стремится извлечь соответствующие термины, такие как ключевые слова или ключевые фразы» (Ригаутс Террин и др., 2020), извлечение отношений, которое стремится извлечь отношения между сущностями, и «открытое извлечение информации, которое облегчает открытое обнаружение реляционных кортежей» (Ятс и др., 2007).
Генерация текста
Целью подходов к генерации текста является создание текстов, которые одновременно являются понятными для людей и неотличимыми от текстов, созданных людьми. Соответственно, вход обычно состоит из текста, как в случае с «перефразировкой, которая изменяет форму входного текста, сохраняя при этом семантику» (Ниу и др., 2021), «генерацией вопросов, которая стремится сформулировать связный и актуальный вопрос на основе фрагмента и целевого ответа» (Сонг и др., 2018) или «генерацией ответов в диалоге, которая стремится генерировать естественно выглядящий текст, соответствующий подсказке» (Чжан и др., 2020). Во многих случаях, однако, текст генерируется в результате входных данных из других модальностей, например, в случае с «генерацией текста на основе данных, таких как таблицы или графики» (Кале и Растоги, 2020), подписыванием изображений или видео или «распознаванием речи, которое транскрибирует речевую волну в текст» (Баевский и др., 2022).
Характеристики и развитие в обработке естественного языка 📈
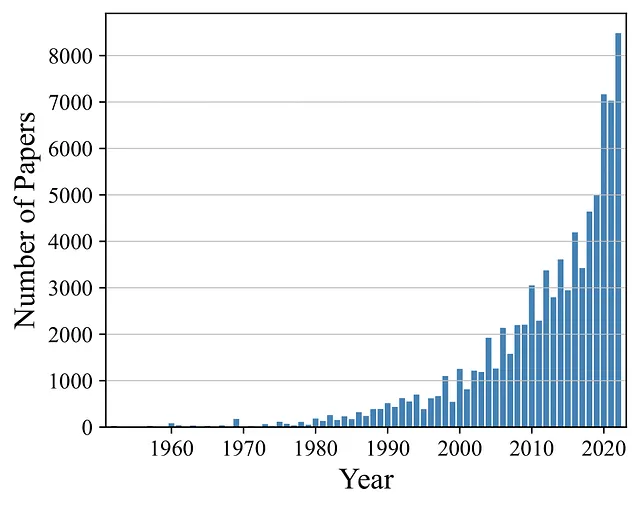
Рассматривая литературу по обработке естественного языка, мы начинаем наш анализ с количества исследований в качестве показателя интереса к исследованиям. Распределение публикаций за период наблюдения в течение 50 лет показано на рисунке выше. В то время как первые публикации появились в 1952 году, количество ежегодных публикаций медленно росло до 2000 года. Соответственно, с 2000 по 2017 год количество публикаций примерно учетверилось, а за последние пять лет оно удвоилось. Таким образом, мы наблюдаем почти экспоненциальный рост количества исследований в области обработки естественного языка, что указывает на увеличение внимания со стороны научного сообщества.

Рассматривая приведенную выше диаграмму, раскрываются наиболее популярные области исследований в литературе по обработке естественного языка (NLP) и их последние изменения со временем. В то время как большинство исследований в NLP связаны с машинным переводом или языковыми моделями, развитие обеих областей исследований различно. Машинный перевод – это тщательно исследованная область, которая существует давно и имеет скромную темп роста за последние 20 лет. Языковые модели также исследовались в течение длительного времени. Однако количество публикаций по этой теме значительно выросло только с 2018 года. Подобные различия можно наблюдать, рассматривая другие популярные области исследований. Обучение представлениям и классификация текста, хотя и широко исследовались, частично стагнируют в своем росте. В отличие от них, системы диалога и разговорные агенты, а также NLP с низкими ресурсами продолжают демонстрировать высокий темп роста в количестве исследований. Исходя из развития среднего количества исследований в остальных областях исследований, мы наблюдаем незначительный положительный рост в целом. Однако большинство областей исследований значительно менее изучены, чем наиболее популярные области исследований.
Последние тенденции в NLP 🚀
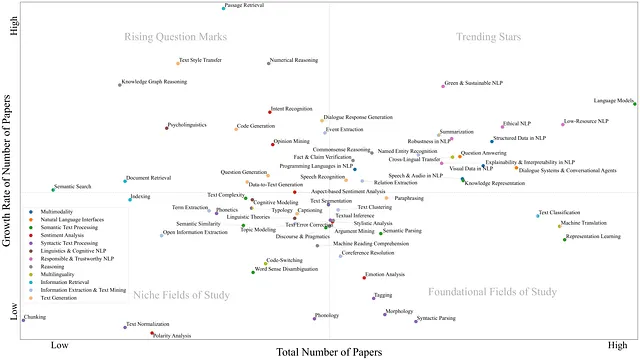
На приведенной выше диаграмме показана матрица роста областей исследований в NLP. Мы используем ее для изучения текущих тенденций и возможных будущих направлений исследований, анализируя темпы роста и общее количество статей, связанных с различными областями исследований в NLP с 2018 по 2022 год. Верхний правый угол матрицы состоит из областей исследований, которые имеют высокий темп роста и одновременно большое общее количество статей. Исходя из растущей популярности областей исследований в этом разделе, мы классифицируем их как популярные направления. Нижний правый угол содержит области исследований, которые очень популярны, но имеют низкий темп роста. Обычно это области исследований, которые являются важными для NLP, но уже относительно зрелыми. Поэтому мы классифицируем их как основные области исследований. В верхнем левом углу матрицы находятся области исследований, которые имеют высокий темп роста, но только очень малое количество статей в целом. Поскольку прогресс этих областей исследований обещает быть интересным, но небольшое количество статей затрудняет прогнозирование их дальнейшего развития, мы классифицируем их как возникающие вопросительные знаки. Области исследований в нижнем левом углу матрицы классифицируются как нишевые области исследований из-за их низкого общего количества статей и низкого темпа роста.
На диаграмме видно, что языковые модели в настоящее время привлекают наибольшее внимание. Основываясь на последних достижениях в этой области, этот тренд, вероятно, будет продолжаться и ускоряться в ближайшем будущем. Классификация текста, машинный перевод и обучение представлениям входят в число самых популярных областей исследований, но показывают только незначительный рост. В долгосрочной перспективе они могут быть заменены более быстрорастущими областями в качестве самых популярных областей исследований.
В общем, области исследований, связанные с синтаксической обработкой текста, практически не растут и не пользуются популярностью в целом. В отличие от этого, области исследований, связанные с ответственным и надежным NLP, такие как экологически устойчивое NLP, NLP с низкими ресурсами и этическое NLP, обычно демонстрируют высокий темп роста и популярность в целом. Эта тенденция также наблюдается в случае структурированных данных в NLP, визуальных данных в NLP и речи и аудио в NLP, все они связаны с мультимодальностью. Кроме того, естественные языковые интерфейсы, включающие системы диалога и разговорные агенты и вопросно-ответные системы, становятся все более важными в исследовательском сообществе. Мы приходим к выводу, что, помимо языковых моделей, ответственное и надежное NLP, мультимодальность и естественные языковые интерфейсы, вероятно, будут характеризовать исследовательский ландшафт в области NLP в ближайшем будущем.
Другие значимые разработки можно наблюдать в области рассуждений, в частности в отношении рассуждений на основе графов знаний и числовых рассуждений, а также в различных областях исследований, связанных с генерацией текста. Хотя эти области исследований в настоящее время все еще относительно небольшие, они, по-видимому, привлекают все больше интереса со стороны научного сообщества и проявляют явную положительную тенденцию к росту.
Вывод 💡
Для обобщения последних разработок и предоставления обзора ландшафта NLP мы определили таксономию областей исследований и проанализировали последние исследовательские разработки.
Наши результаты показывают, что было исследовано большое количество областей изучения, включая актуальные направления, такие как мультимодальность, ответственная и надежная обработка естественного языка и естественные языковые интерфейсы. Мы надеемся, что этот статья предоставляет полезный обзор текущего ландшафта NLP и может служить отправной точкой для более глубокого исследования этой области.
Источники
Исследование ландшафта исследований по обработке естественного языка
Как эффективный подход к пониманию, генерированию и обработке текстов на естественном языке, исследования в области естественного языка…
arxiv.org





