FMOps/LLMOps Операционализация генеративного искусственного интеллекта и отличия от MLOps
Операционализация генеративного искусственного интеллекта и отличия от MLOps
В настоящее время большинство наших клиентов в восторге от больших языковых моделей (LLM) и задумываются о том, как генеративный ИИ может преобразовать их бизнес. Однако внедрение таких решений и моделей в повседневную бизнес-деятельность не является простой задачей. В этом посте мы обсудим, как операционализировать генеративные приложения ИИ, используя принципы MLOps, приводящие к операциям с фундаментальными моделями (FMOps). Кроме того, мы подробно рассмотрим наиболее распространенный случай использования генеративного ИИ в приложениях текст-текст и операций с LLM (LLMOps), являющихся частью FMOps. Ниже приведена иллюстрация тем, которые мы обсуждаем.
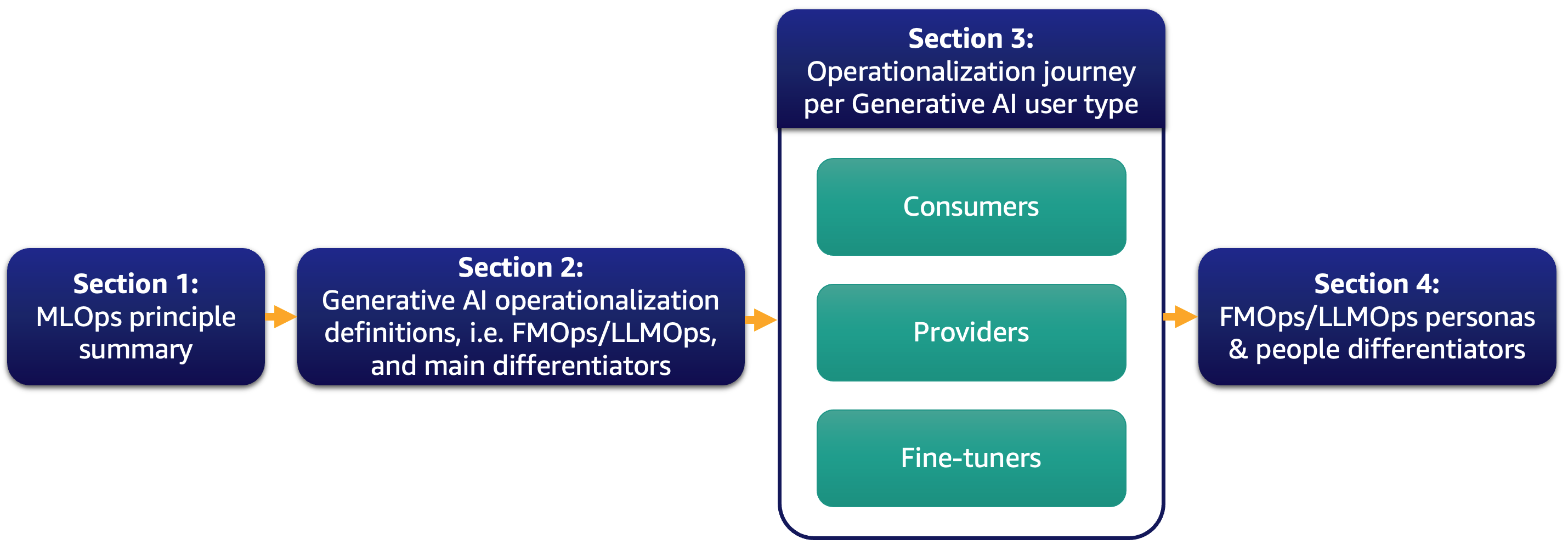
Конкретно, мы кратко представим принципы MLOps и сосредоточимся на основных отличиях по сравнению с FMOps и LLMOps в отношении процессов, людей, выбора и оценки моделей, конфиденциальности данных и развертывания моделей. Это относится к клиентам, которые используют их «из коробки», создают фундаментальные модели с нуля или настраивают их. Наш подход одинаково применим как к открытым, так и к закрытым моделям.
Операционализация ML: краткое изложение
Как определено в посте Основная дорожная карта MLOps для предприятий с использованием Amazon SageMaker, MLOps – это комбинация людей, процессов и технологий для эффективной внедрения решений машинного обучения (ML) в производство. Для достижения этой цели необходимо сотрудничество команд и персонажей, как показано на следующей иллюстрации.
- Повышение опыта использования генеративного искусственного интеллекта Введение поддержки потоковой передачи в Amazon SageMaker хостинг
- Интервью с основателем Грегори Пиатецки-Шапиро в честь 30-летия VoAGI
- С днем рождения, VoAGI, 30 лет!
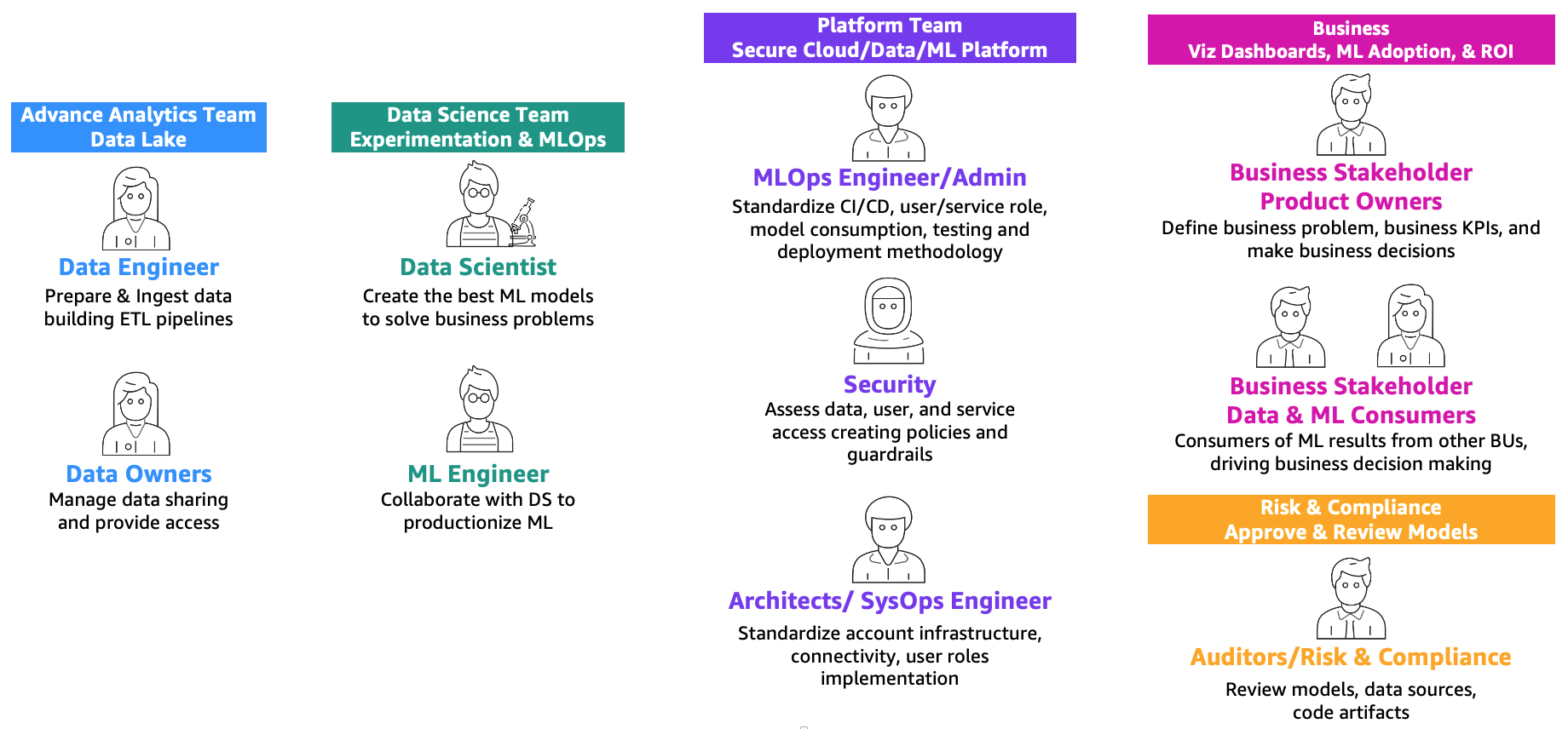
Эти команды следующие:
- Команда продвинутой аналитики (data lake и data mesh) – Инженеры по данным отвечают за подготовку и загрузку данных из разных источников, создание ETL-пайплайнов (извлечение, преобразование и загрузка) для каталогизации данных и подготовки необходимых исторических данных для задач ML. Эти владельцы данных фокусируются на предоставлении доступа к своим данным для нескольких бизнес-подразделений или команд.
- Команда науки о данных – Научные сотрудники должны сосредоточиться на создании лучшей модели на основе предопределенных ключевых показателей эффективности (KPI), работая в блокнотах. После завершения этапа исследования научные сотрудники должны сотрудничать с инженерами ML для создания автоматизаций для построения (ML-пайплайнов) и развертывания моделей в производство с использованием CI/CD-пайплайнов.
- Бизнес-команда – Владелец продукта отвечает за определение бизнес-кейса, требований и KPI, которые будут использоваться для оценки эффективности модели. Пользователи ML – это другие заинтересованные стороны, которые используют результаты вывода (предсказания) для принятия решений.
- Команда платформы – Архитекторы отвечают за общую облачную архитектуру бизнеса и связь всех различных сервисов. Специалисты по безопасности проверяют архитектуру на основе политик и потребностей безопасности бизнеса. Инженеры MLOps отвечают за обеспечение безопасной среды для научных сотрудников и инженеров ML для внедрения задач ML в производство. Конкретно, они отвечают за стандартизацию CI/CD-пайплайнов, ролей пользователей и служб, создание контейнеров, потребление модели, тестирование и методологию развертывания на основе требований бизнеса и безопасности.
- Команда рисков и соответствия – Для более строгих сред средствами аудиторов проверяются данные, код и артефакты модели, а также проверяется соответствие бизнеса регулятивным требованиям, таким как конфиденциальность данных.
Обратите внимание, что один и тот же человек может заниматься несколькими ролями в зависимости от масштабирования и зрелости MLOps бизнеса.
Этим персонажам требуются отдельные среды для выполнения различных процессов, как показано на следующей иллюстрации.
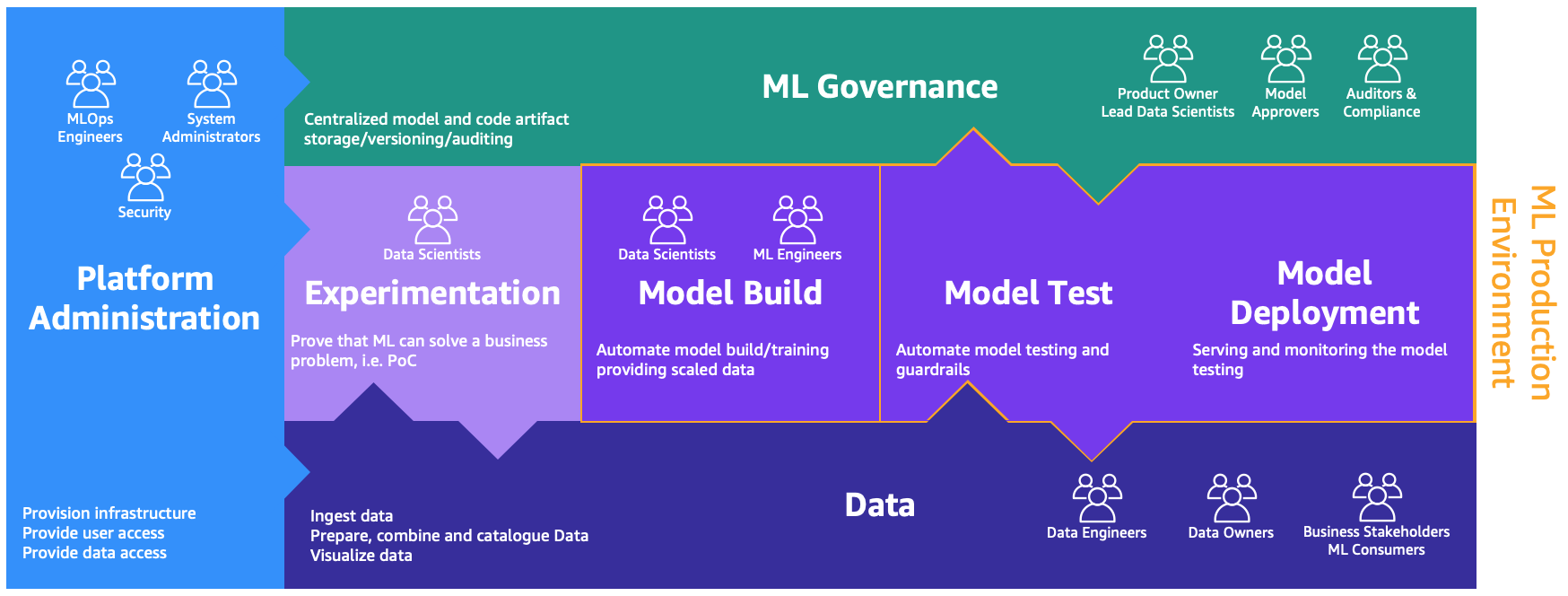
Среды следующие:
- Администрирование платформы – Среда администрирования платформы – это место, где команда платформы имеет доступ для создания учетных записей AWS и связывания правильных пользователей и данных.
- Данные – Уровень данных, часто известный как data lake или data mesh, является окружением, которое используют инженеры или владельцы данных и заинтересованные стороны бизнеса для подготовки, взаимодействия и визуализации данных.
- Экспериментирование – Ученые используют песочницу или среду для экспериментов, чтобы проверить новые библиотеки и методы машинного обучения, чтобы доказать, что их концепция может решить бизнес-проблемы.
- Сборка модели, тестирование модели, развертывание модели – Среда сборки, тестирования и развертывания модели является слоем MLOps, где научные сотрудники и инженеры ML сотрудничают для автоматизации и переноса исследований в производство.
- Управление ML – Последний кусочек паззла – это среда управления ML, где все артефакты модели и кода хранятся, рассматриваются и проверяются соответствующими персонажами.
Следующая диаграмма иллюстрирует референсную архитектуру, которая уже была обсуждена в дорожной карте MLOps для предприятий с использованием Amazon SageMaker.
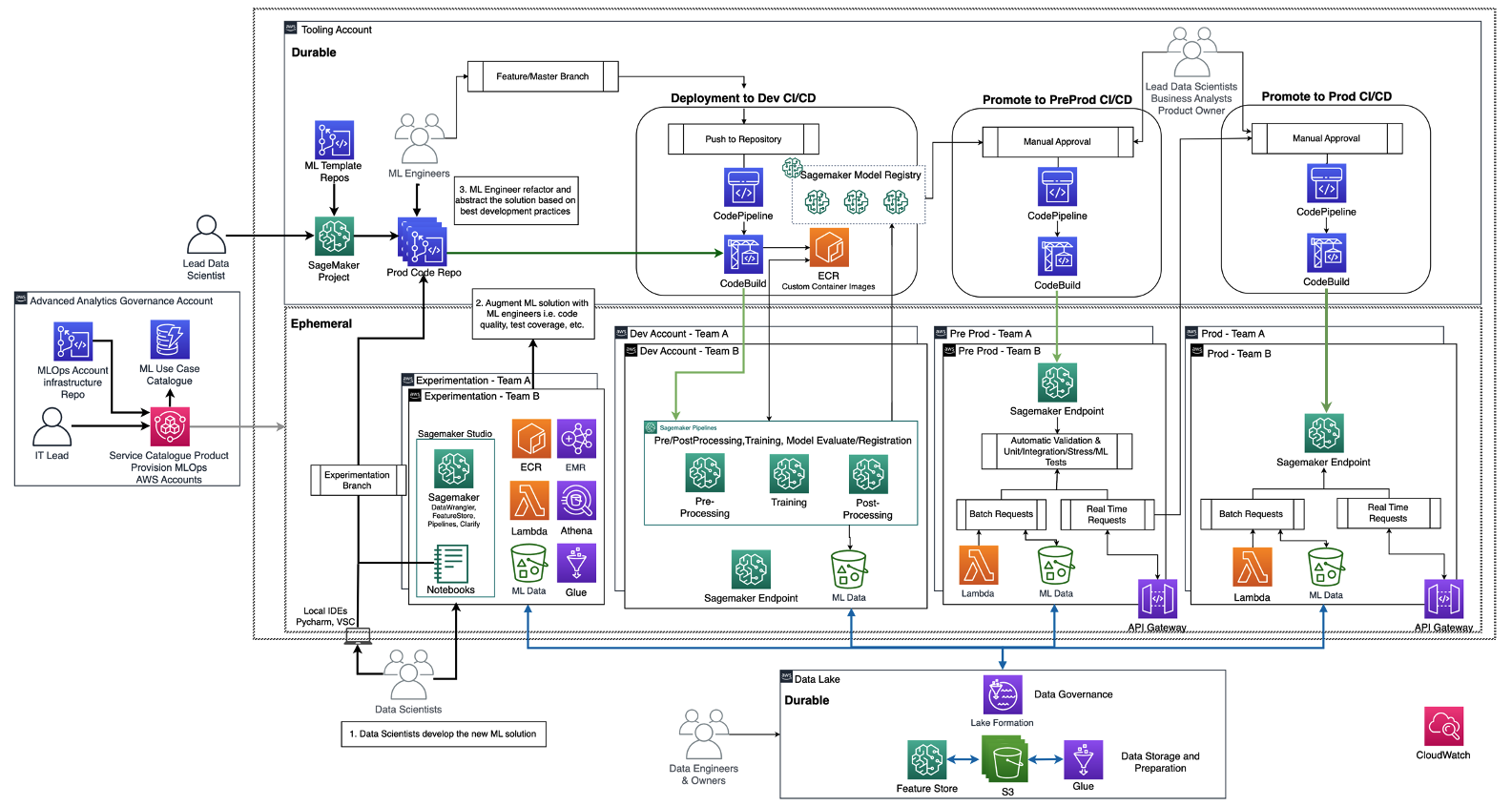
Каждое бизнес-подразделение имеет свой набор разработки (автоматическое обучение и создание моделей), предпродакшн (автоматическое тестирование) и продакшн (развертывание и обслуживание моделей) аккаунтов для внедрения случаев использования ML, которые получают данные из централизованного или децентрализованного data lake или data mesh соответственно. Все созданные модели и автоматизация кода хранятся в централизованном аккаунте инструментов с использованием возможности реестра моделей. Инфраструктурный код для всех этих аккаунтов версионируется в общем аккаунте общих служб (аккаунте управления расширенным анализом), который команде платформы может абстрагировать, шаблонизировать, поддерживать и повторно использовать для встраивания в MLOps платформу каждой новой команды.
Определения генеративного ИИ и отличия от MLOps
В классическом ML предыдущая комбинация людей, процессов и технологий может помочь продукцировать ваши случаи использования ML. Однако в генеративном ИИ характер случаев использования требует либо расширения этих возможностей, либо новых возможностей. Одной из таких новых концепций является фундаментальная модель (FM). Они называются такими, потому что они могут использоваться для создания широкого спектра других моделей ИИ, как показано на следующей фигуре.
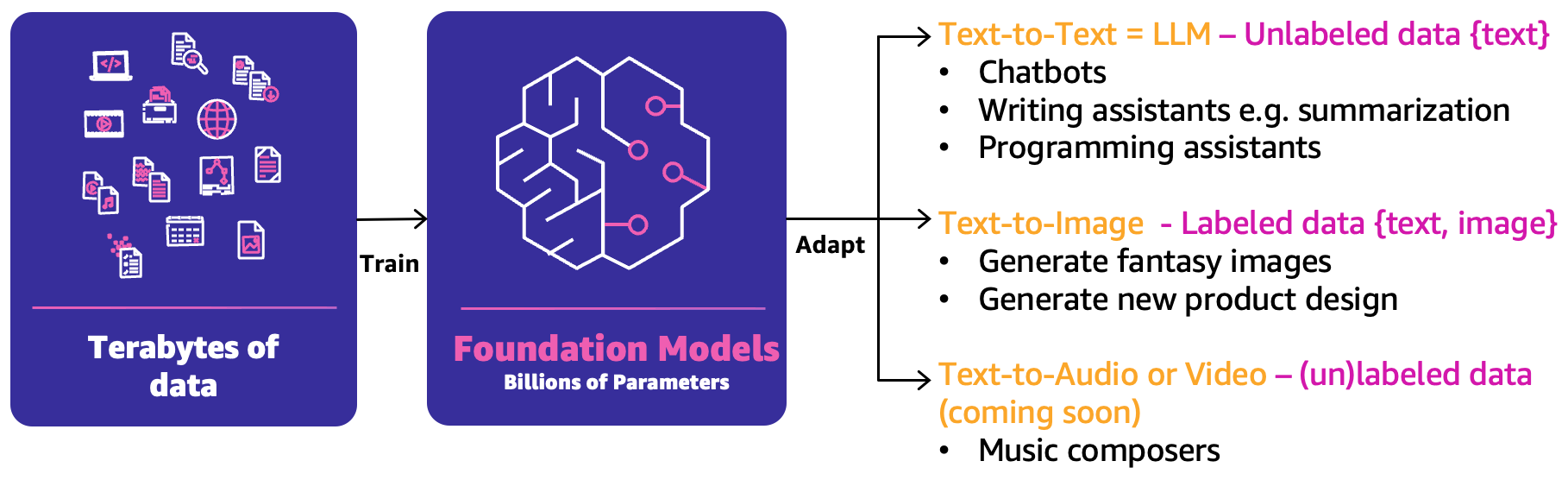
FM были обучены на основе терабайтов данных и имеют сотни миллиардов параметров, чтобы быть способными предсказывать следующий лучший ответ на основе трех основных категорий генеративных случаев использования ИИ:
- Текст-в-текст – FM (LLM) были обучены на основе неразмеченных данных (таких как свободный текст) и способны предсказывать следующее наилучшее слово или последовательность слов (абзацы или длинные эссе). Основные случаи использования связаны с чат-ботами, суммированием или созданием другого контента, такого как программный код.
- Текст-в-изображение – Были использованы размеченные данные, такие как пары <текст, изображение>, для обучения FM, которые способны предсказывать лучшую комбинацию пикселей. Примеры случаев использования: создание дизайна одежды или воображаемых персонализированных изображений.
- Текст-в-аудио или видео – Для обучения FM могут использоваться как размеченные, так и неразмеченные данные. Один из основных примеров генеративного ИИ – композиция музыки.
Для внедрения в производственные условия этих случаев использования генеративного ИИ нам необходимо заимствовать и расширить область MLOps, включив в нее следующее:
- Операции с FM (FMOps) – это может производственно использовать решения генеративного ИИ, включая любой тип случая использования
- Операции с LLM (LLMOps) – это подмножество FMOps, сфокусированное на производственном использовании решений на основе LLM, таких как текст-в-текст
Следующая фигура иллюстрирует перекрытие этих случаев использования.
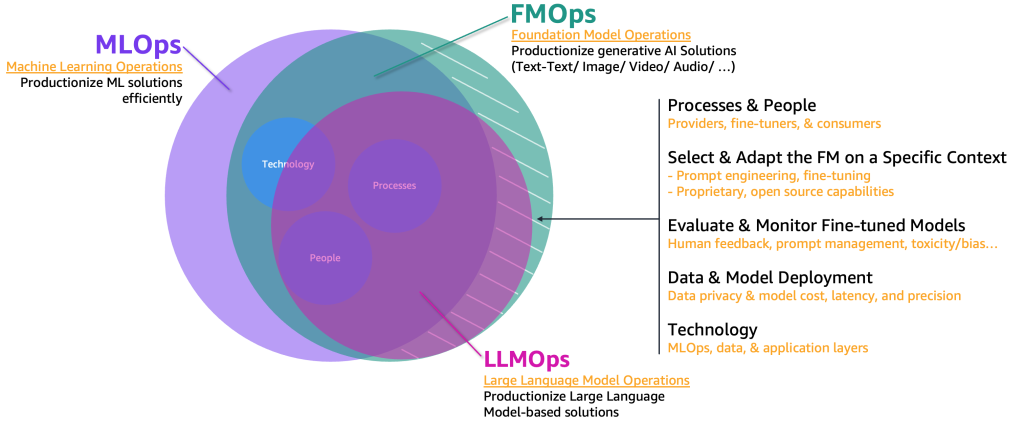
По сравнению с классическим ML и MLOps, FMOps и LLMOps отличаются по четырем основным категориям, которые мы рассмотрим в следующих разделах: люди и процессы, выбор и адаптация FM, оценка и мониторинг FM, конфиденциальность данных и развертывание модели, а также потребности в технологии. Мы рассмотрим мониторинг в отдельной публикации.
Путь операционализации для каждого типа пользователей генеративного ИИ
Для упрощения описания процессов нам необходимо категоризировать основные типы пользователей генеративного ИИ, как показано на следующей фигуре.
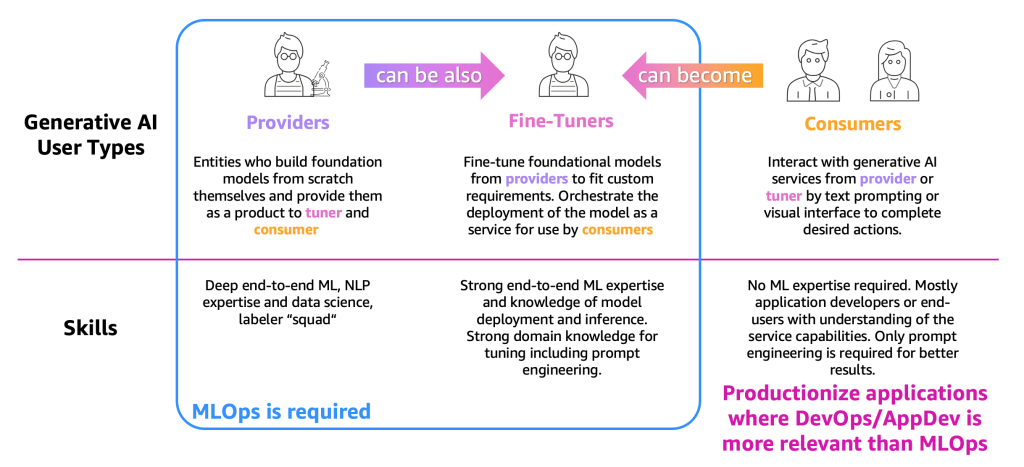
Типы пользователей следующие:
- Поставщики – Пользователи, которые создают FM с нуля и предоставляют их другим пользователям в качестве продукта (тюнер и потребитель). У них есть глубокие знания в области ML и обработки естественного языка (NLP), а также навыки в области науки о данных, а также команды по разметке и редактированию данных.
- Тюнеры – Пользователи, которые переобучают (тонконастраивают) FM от поставщиков, чтобы адаптировать их под конкретные требования. Они оркестрируют развертывание модели в виде сервиса для использования потребителями. Этим пользователям необходимы глубокие знания в области ML и науки о данных, а также знание развертывания моделей и вывода. Требуется также глубокие знания в области домена, включая инжиниринг запросов.
- Потребители – Пользователи, которые взаимодействуют с генеративными AI-сервисами от поставщиков или тюнеров с помощью текстовых подсказок или визуального интерфейса для выполнения желаемых действий. Нет необходимости в знаниях в области ML, но это обычно разработчики приложений или конечные пользователи, которые понимают возможности сервиса. Для достижения лучших результатов требуется только инжиниринг запросов.
Согласно определению и требуемым знаниям в области ML, MLOps в основном требуется для поставщиков и тюнеров, тогда как потребители могут использовать принципы производства приложений, такие как DevOps и AppDev, для создания генеративных AI-приложений. Кроме того, мы заметили движение между типами пользователей, где поставщики могут стать тюнерами для поддержки случаев использования в определенной отрасли (например, финансовой), или потребители могут стать тюнерами для достижения более точных результатов. Но давайте рассмотрим основные процессы для каждого типа пользователя.
Путешествие потребителей
На следующей иллюстрации показано путешествие потребителей.
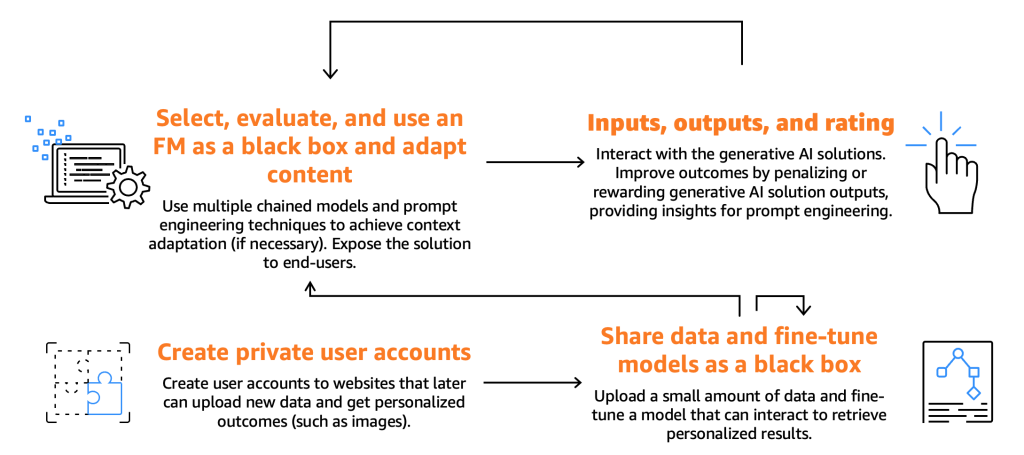
Как уже упоминалось ранее, потребителям требуется выбрать, протестировать и использовать FM, взаимодействуя с ними, предоставляя конкретные входные данные, известные как подсказки. Подсказки в контексте программирования компьютеров и искусственного интеллекта относятся к входным данным, предоставляемым модели или системе для генерации ответа. Это может быть текст, команда или вопрос, которые система использует для обработки и генерации вывода. Полученный результат от FM может использоваться конечными пользователями, которые также должны иметь возможность оценивать эти результаты, чтобы улучшить будущие ответы модели.
Помимо этих основных процессов, мы заметили, что потребители выражают желание тонконастраивать модели, используя функциональность, предлагаемую тюнерами. Например, на веб-сайте, который генерирует изображения, конечные пользователи могут создавать личные аккаунты, загружать личные фотографии и впоследствии генерировать контент, связанный с этими изображениями (например, генерация изображения, на котором конечный пользователь сидит на мотоцикле с мечом или находится в экзотическом месте). В этом случае генеративное AI-приложение, созданное потребителем, должно взаимодействовать с бэкэндом тюнера с помощью API, чтобы предоставить эту функциональность конечным пользователям.
Однако, прежде чем мы углубимся в это, давайте сначала сосредоточимся на путешествии выбора модели, тестирования, использования, взаимодействия входных и выходных данных и оценки, как показано на следующей иллюстрации.
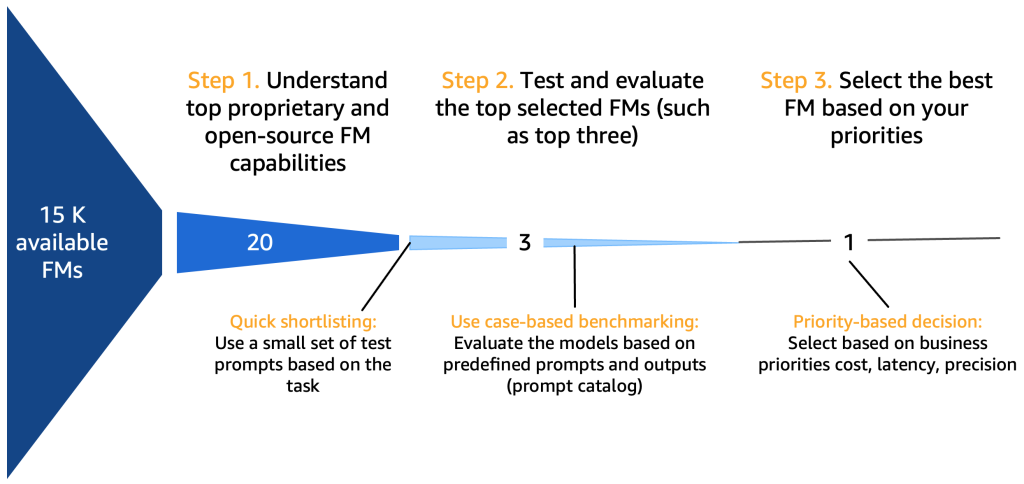
*15K доступных FM для справки
Шаг 1. Понять возможности лучших FM
При выборе фундаментальных моделей необходимо учитывать множество аспектов, в зависимости от конкретной задачи, доступных данных, регулирования и т. д. Хорошим списком, хотя и не исчерпывающим, может быть следующее:
- Собственная или открытая FM – Собственные модели часто имеют финансовую стоимость, но обычно они обеспечивают лучшую производительность (в терминах качества сгенерированного текста или изображения), часто разрабатываемые и поддерживаемые специализированными командами поставщиков моделей, которые обеспечивают оптимальную производительность и надежность. С другой стороны, мы также видим использование открытых моделей, которые, помимо бесплатности, предлагают дополнительные преимущества доступности и гибкости (например, каждая открытая модель может быть тонконастраиваемой). Примером собственной модели является модель Claude от Anthropic, а примером открытой модели с высокой производительностью является Falcon-40B на июль 2023 года.
- Коммерческая лицензия – Лицензионные соображения являются ключевыми при выборе FM. Важно отметить, что некоторые модели являются открытыми, но не могут использоваться в коммерческих целях из-за ограничений или условий лицензирования. Различия могут быть незначительными: например, нед
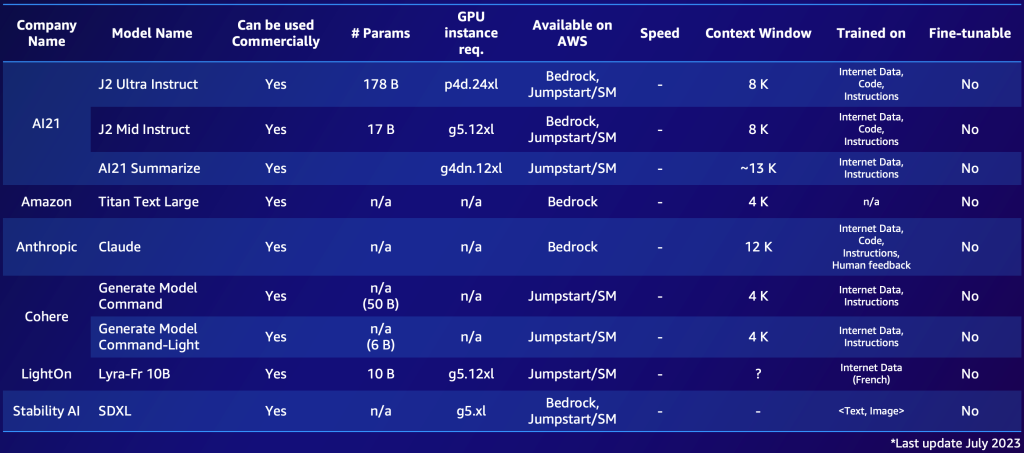
В следующем примере приведены два краткосрочных списка, один для собственных моделей и один для моделей с открытым исходным кодом. Вы можете создать подобные таблицы на основе ваших конкретных потребностей, чтобы быстро ознакомиться с доступными вариантами. Обратите внимание, что производительность и параметры этих моделей быстро меняются и могут устареть к моменту чтения, в то время как другие возможности могут быть важны для конкретных клиентов, таких как поддерживаемые языки.
Ниже приведен пример известных собственных FM, доступных в AWS (июль 2023 года).
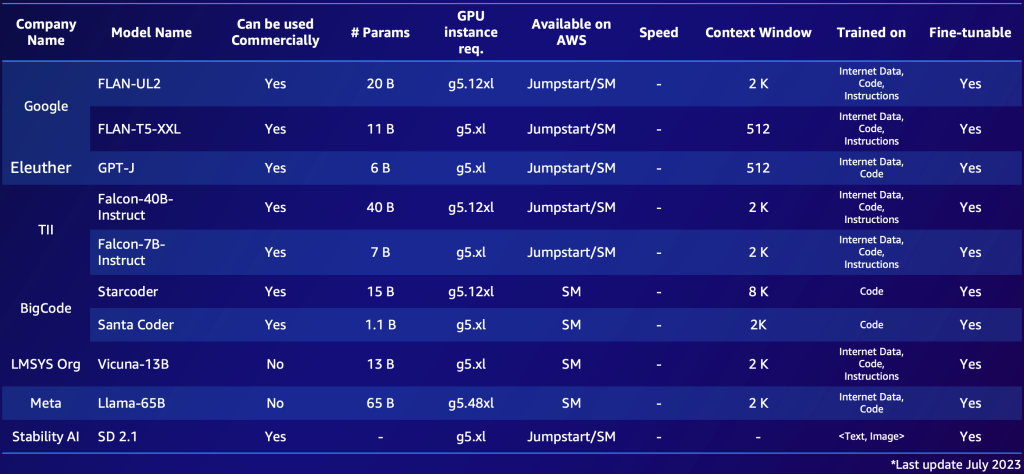
Ниже приведен пример известного FM с открытым исходным кодом, доступного в AWS (июль 2023 года).
После того, как вы составите обзор 10-20 потенциальных кандидатских моделей, становится необходимым дальнейшее уточнение этого краткосрочного списка. В этом разделе мы предлагаем быстрый механизм, который даст две или три жизнеспособные финальные модели в качестве кандидатов на следующий раунд.
Ниже представлена диаграмма, иллюстрирующая процесс начального отбора.
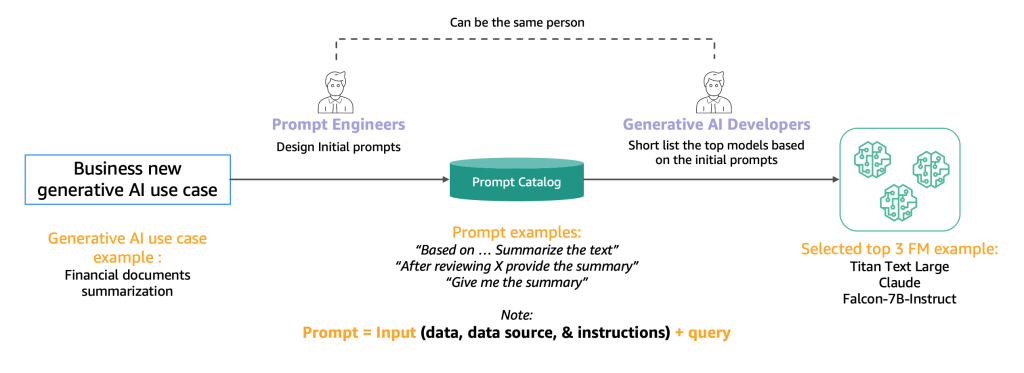
Как правило, инженеры, эксперты в создании высококачественных подсказок, которые позволяют ИИ-моделям понимать и обрабатывать входные данные пользователей, экспериментируют с различными методами выполнения той же задачи (например, суммирования) на модели. Мы предлагаем, чтобы эти подсказки не создавались на ходу, а систематически извлекались из каталога подсказок. Этот каталог подсказок является центральным местом для хранения подсказок, чтобы избежать дублирования, обеспечить контроль версий и обмен подсказками в команде для обеспечения согласованности между разными тестерами подсказок на разных стадиях разработки, которые мы представляем в следующем разделе. Этот каталог подсказок аналогичен репозиторию Git хранилища функций. Затем разработчику генеративного ИИ, который потенциально может быть тем же самым человеком, что и инженер подсказок, необходимо оценить результаты, чтобы определить, подходит ли он для разрабатываемого им приложения генеративного ИИ.
Шаг 2. Тестирование и оценка лучшей FM
После того, как краткосрочный список сокращен примерно до трех FM, мы рекомендуем выполнить этап оценки для дальнейшего тестирования возможностей FM и их пригодности для конкретного случая использования. В зависимости от наличия и характера данных для оценки мы предлагаем различные методы, как показано на следующей схеме.
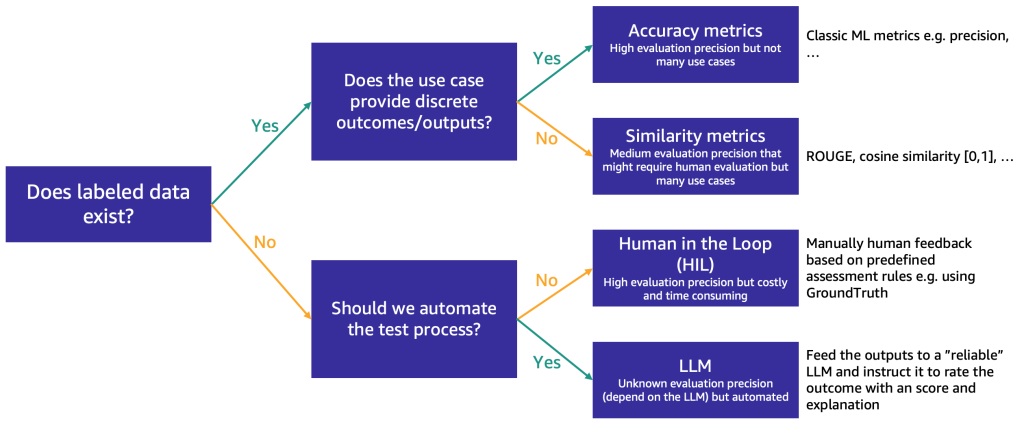
Метод, который следует использовать в первую очередь, зависит от наличия размеченных тестовых данных.
Если у вас есть размеченные данные, вы можете использовать их для выполнения оценки модели, как мы делаем с традиционными моделями машинного обучения (вводите некоторые образцы и сравниваете вывод с метками). В зависимости от того, имеются ли у тестовых данных дискретные метки (например, анализ тональности) или структурированный текст (например, суммирование), мы предлагаем различные методы оценки:
- Метрики точности – В случае дискретного вывода (например, анализ тональности) мы можем использовать стандартные метрики точности, такие как точность, полнота и F-мера
- Метрики сходства – Если вывод является структурированным (например, резюме), мы предлагаем использовать метрики сходства, такие как ROUGE и косинусное сходство
Некоторые случаи использования не предполагают наличия одного истинного ответа (например, “Создайте короткую детскую историю для моей пятилетней дочери”). В таких случаях оценка моделей становится более сложной, потому что у вас нет размеченных тестовых данных. Мы предлагаем два подхода, в зависимости от важности человеческого обзора модели по сравнению с автоматической оценкой:
- Человек в петле (HIL) – В этом случае команда тестеров подсказок будет рассматривать ответы от модели. В зависимости от важности приложения тестеры могут рассматривать 100% результатов модели или только выборку.
- Оценка с использованием LLM – В этом сценарии тестеры подсказок заменяются LLM, желательно более мощным (хотя, возможно, медленным и более дорогим) чем тестируемые. LLM будет рассматривать все ответы, сгенерированные моделью, и оценивать их. Этот метод может дать более низкое качество, но это более дешевый и быстрый вариант оценки, который может дать хорошую начальную оценку производительности моделей.
Например, мы можем использовать следующую примерную подсказку для LLM, которая включает в себя входной запрос, ответ LLM и инструкции: «Мы хотели бы попросить ваш отзыв о работе AI-ассистента в ответ на вопрос пользователя, отображенный выше. Пожалуйста, оцените полезность, актуальность, точность и уровень детализации ответа ассистента. Ассистент должен получить общую оценку на шкале от 1 до 10, где более высокая оценка указывает на более высокую общую производительность.
Эта подсказка будет отправлена другому LLM (EvalLLM) для оценки. Ниже приведен пример, где ответ модели Falcon-40B был оценен EvalLLM (в данном случае Клодом). Мы используем вопрос «Что было бы, если бы Суэцкий канал не был построен?». Ответ следующий:
Вопрос: Что было бы, если бы Суэцкий канал не был построен?
falcon-40b-instruct
Если бы Суэцкий канал не был построен, суда должны были бы плавать вокруг Африки, чтобы перемещаться между Средиземным и Красным морями. Это добавило бы значительное время и расстояние к путешествию, делая его менее эффективным и дорогостоящим. Кроме того, без Суэцкого канала многие страны Ближнего Востока и Северной Африки были бы намного менее связаны с остальным миром, что затрудняло бы экономическое и культурное развитие.
Обзор (Оценка: 9/10)
Ответ ассистента является очень актуальным, точным и подробным. Он предоставляет отличный ответ на гипотетический вопрос пользователя о несуществовании Суэцкого канала. Ассистент правильно указывает на последствия для морского путешествия и экономического и культурного влияния на Ближний Восток и Северную Африку. Однако он мог бы дополнительно рассмотреть геополитические последствия или влияние на глобальные торговые паттерны для более полного ответа.
Следующая иллюстрация иллюстрирует пример процесса оценки от начала до конца.
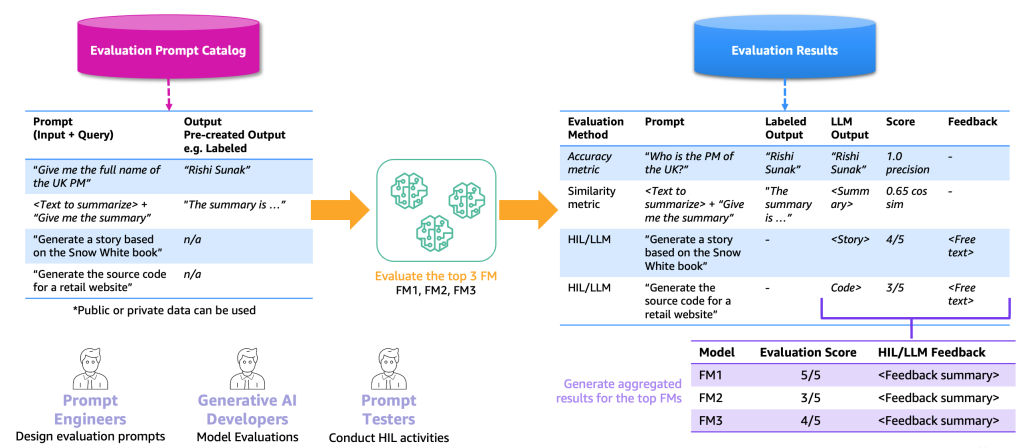
Исходя из этого примера, для выполнения оценки нам необходимо предоставить примерные подсказки, которые мы храним в каталоге подсказок, а также оценочный набор данных с метками или без меток, основанный на наших конкретных приложениях. Например, с помощью размеченного оценочного набора данных мы можем предоставить подсказки (ввод и запрос), такие как «Дайте мне полное имя премьер-министра Великобритании в 2023 году», а также выходные данные и ответы, такие как «Риши Сунак». С помощью неразмеченного набора данных мы предоставляем только вопрос или инструкцию, такую как «Сгенерируйте исходный код для интернет-магазина». Мы называем комбинацию каталога подсказок и оценочного набора данных каталогом оценочных подсказок. Причина, по которой мы разделяем каталог подсказок и каталог оценочных подсказок, заключается в том, что последний предназначен для конкретного случая использования, а не для общих подсказок и инструкций (например, вопросы и ответы), которые содержит каталог подсказок.
С использованием этого каталога оценочных подсказок следующим шагом является подача оценочных подсказок верхним FMs. Результатом является набор результатов оценки, который содержит подсказки, выходы каждого FM и размеченный выход вместе с оценкой (если таковая имеется). В случае неразмеченного каталога оценочных подсказок есть дополнительный шаг для HIL или LLM, чтобы просмотреть результаты и предоставить оценку и обратную связь (как описано ранее). Конечным результатом будут собранные результаты, объединяющие оценки всех выходов (рассчитывается средняя точность или оценка человека) и позволяющие пользователям оценить качество моделей.
После сбора результатов оценки мы предлагаем выбрать модель на основе нескольких измерений. Обычно они сводятся к таким факторам, как точность, скорость и стоимость. На следующей иллюстрации показан пример.
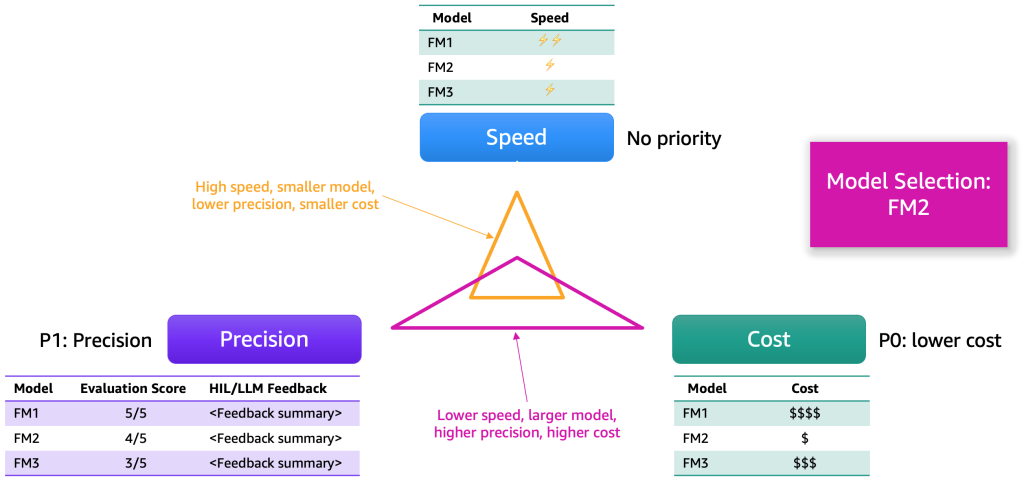
Каждая модель будет обладать своими преимуществами и определенными компромиссами по этим измерениям. В зависимости от сценария использования мы должны присваивать различные приоритеты этим измерениям. В предыдущем примере мы решили отдать приоритет стоимости как наиболее важному фактору, за которым следуют точность и скорость. Несмотря на то, что он работает медленнее и не так эффективен, как FM1, он по-прежнему достаточно эффективен и значительно дешевле в обслуживании. В результате мы можем выбрать FM2 в качестве лучшего выбора.
Шаг 3. Разработка бэкэнда и фронтэнда генеративного приложения искусственного интеллекта
На данном этапе разработчики генеративного искусственного интеллекта выбрали подходящую FM для конкретного приложения с помощью инженеров и тестировщиков-подсказчиков. Следующим шагом является начало разработки генеративного приложения искусственного интеллекта. Мы разделили разработку генеративного приложения искусственного интеллекта на два уровня: бэкэнд и фронтэнд, как показано на следующей схеме.
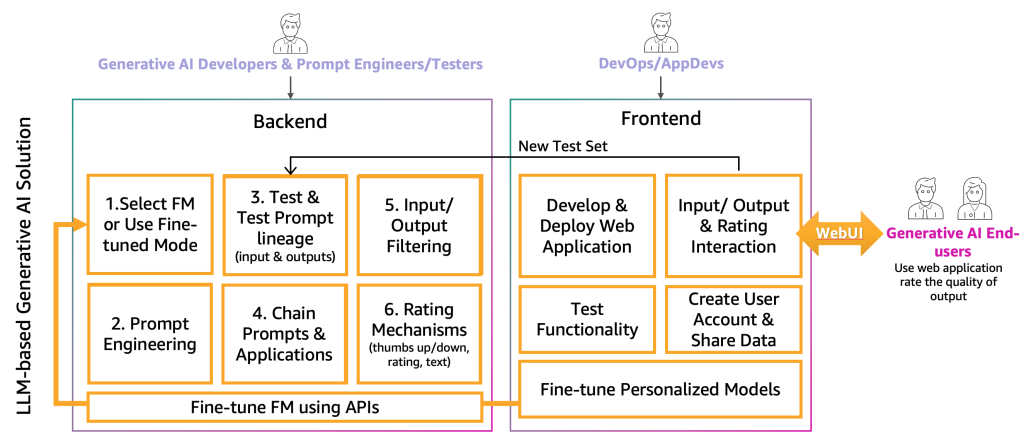
На бэкэнде разработчики генеративного искусственного интеллекта интегрируют выбранную FM в решения и совместно с инженерами-подсказчиками создают автоматизацию для преобразования ввода конечного пользователя в соответствующие подсказки FM. Тестировщики-подсказчики создают необходимые записи в каталоге подсказок для автоматического или ручного тестирования (HIL или LLM). Затем разработчики генеративного искусственного интеллекта создают механизм цепочки подсказок и приложения для предоставления конечного результата. Цепочка подсказок в этом контексте – это техника создания более динамичных и контекстно осознающих приложений LLM. Она работает путем разбиения сложной задачи на серию более мелких, более управляемых подзадач. Например, если мы задаем вопрос LLM “Где родился премьер-министр Великобритании и насколько далеко это место от Лондона”, задачу можно разбить на отдельные подсказки, где подсказка может быть построена на основе ответа предыдущей оценки подсказки, например “Кто является премьер-министром Великобритании”, “Где он родился” и “На сколько это место далеко от Лондона?” Для обеспечения определенного качества ввода и вывода разработчикам генеративного искусственного интеллекта также необходимо создать механизм для контроля и фильтрации входов конечного пользователя и выходов приложения. Например, если приложение LLM должно избегать токсичных запросов и ответов, они могут применить детектор токсичности для входа и выхода и отфильтровать их. Наконец, им необходимо предоставить механизм оценки, который поддержит дополнение каталога оценочных подсказок хорошими и плохими примерами. Более детальное представление этих механизмов будет представлено в будущих записях.
Для предоставления функциональности конечному пользователю генеративного искусственного интеллекта необходимо разработать веб-сайт фронтэнда, который взаимодействует с бэкэндом. Поэтому персонал DevOps и AppDevs (разработчики приложений в облаке) должны следовать лучшим практикам разработки для реализации функциональности ввода/вывода и оценки.
В дополнение к этой основной функциональности фронтэнд и бэкэнд должны включать функцию создания персональных учетных записей пользователей, загрузки данных, инициирования тонкой настройки в качестве черного ящика и использования персонализированной модели вместо базовой FM. Продуктивизация генеративного приложения искусственного интеллекта аналогична обычному приложению. На следующей схеме изображен пример архитектуры.
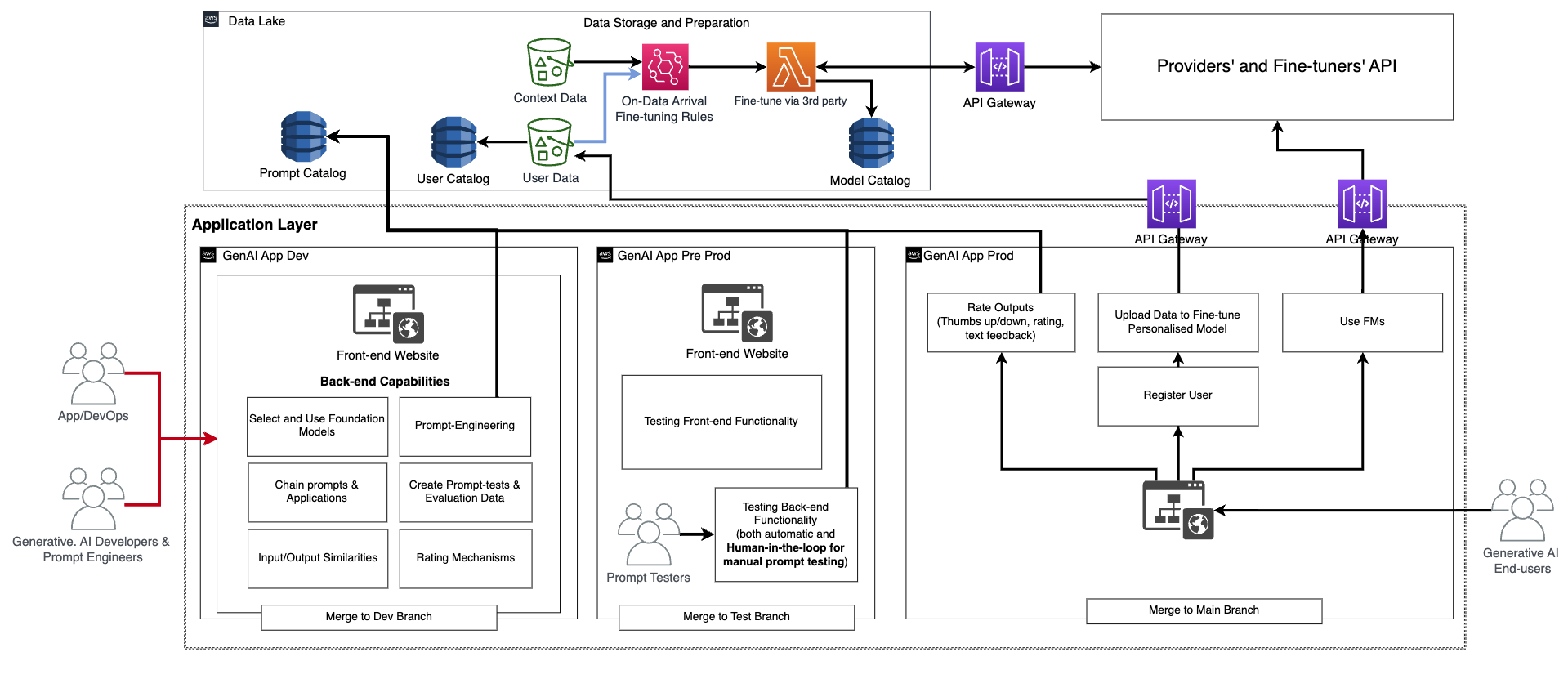
В этой архитектуре разработчики генеративного искусственного интеллекта, инженеры-подсказчики и DevOps или AppDevs создают и тестируют приложение вручную, развертывая его через CI/CD в среде разработки (генеративное приложение искусственного интеллекта на предыдущей схеме) с использованием специальных репозиториев кода и объединения с веткой разработки. На этом этапе разработчики генеративного искусственного интеллекта будут использовать соответствующую FM, вызывая API, предоставленное поставщиками FM для тонкой настройки. Затем, чтобы тестировать приложение в полной мере, им необходимо продвигать код в тестовую ветку, что приведет к развертыванию через CI/CD в предпроизводственную среду (генеративное приложение искусственного интеллекта Pre-prod). В этой среде тестировщикам-подсказчикам нужно попробовать большое количество комбинаций подсказок и просмотреть результаты. Комбинацию подсказок, выводов и просмотра необходимо переместить в каталог оценочных подсказок для автоматизации процесса тестирования в будущем. После этого обширного тестирования последним шагом будет продвижение генеративного приложения искусственного интеллекта в производство через CI/CD путем объединения с основной веткой (генеративное приложение искусственного интеллекта Prod). Обратите внимание, что все данные, включая каталог подсказок, данные и результаты оценки, данные и метаданные конечного пользователя и данные о метаданных, полученных в результате тонкой настройки модели, должны быть сохранены в хранилище данных или слое данных-сетке. Линии CI/CD и репозитории должны быть сохранены в отдельном учетном аккаунте инструментов (подобно описанному для MLOps).
Путь поставщиков
Поставщикам FM необходимо обучать FM, такие как модели глубокого обучения. Для них необходимо наличие жизненного цикла MLOps и инфраструктуры end-to-end. Требуются дополнения в подготовке исторических данных, оценке модели и мониторинге. На следующей схеме изображен их путь.
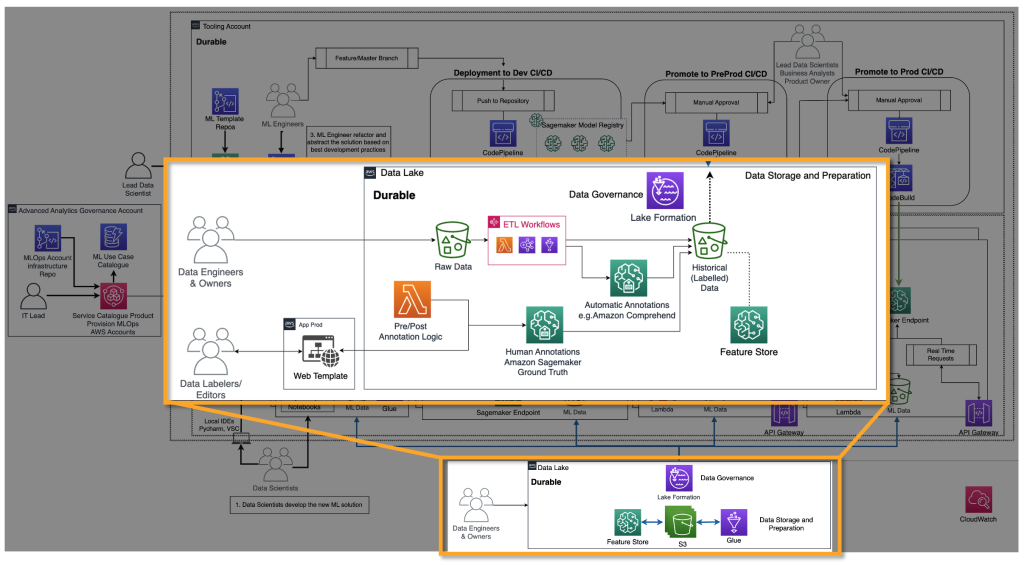
В классическом машинном обучении исторические данные чаще всего создаются путем передачи истинных результатов через ETL-каналы. Например, в случае прогнозирования оттока, автоматизация обновляет таблицу базы данных на основе нового статуса клиента для автоматического оттока/не оттока. В случае FMs им требуется миллиарды помеченных или непомеченных точек данных. В случае использования текста в качестве изображения команда разметчиков данных должна помечать пары <текст, изображение> вручную. Это дорогостоящее занятие, требующее большого количества ресурсов. Amazon SageMaker Ground Truth Plus может предоставить команду разметчиков для выполнения этой работы. В некоторых случаях этот процесс можно частично автоматизировать, например, с помощью моделей, подобных CLIP. В случае LLM, такого как текст-к тексту, данные не помечены. Однако их необходимо подготовить и следовать формату существующих исторических непомеченных данных. Для этого требуются редакторы данных, которые выполняют необходимую подготовку данных и обеспечивают их согласованность.
После подготовки исторических данных следующим шагом является обучение и производственная эксплуатация модели. Обратите внимание, что те же методы оценки, о которых мы говорили для потребителей, могут быть использованы.
Путь настройщиков
Настройщики стремятся адаптировать существующий FM к своему конкретному контексту. Например, модель FM может подводить итог общего текста, но не может точно подводить итог финансового отчета или не может генерировать исходный код для нестандартного языка программирования. В таких случаях настройщикам необходимо помечать данные, настраивать модель, выполняя обучающую задачу, развертывать модель, тестировать ее на основе процессов потребителей и контролировать модель. Следующая диаграмма иллюстрирует этот процесс.
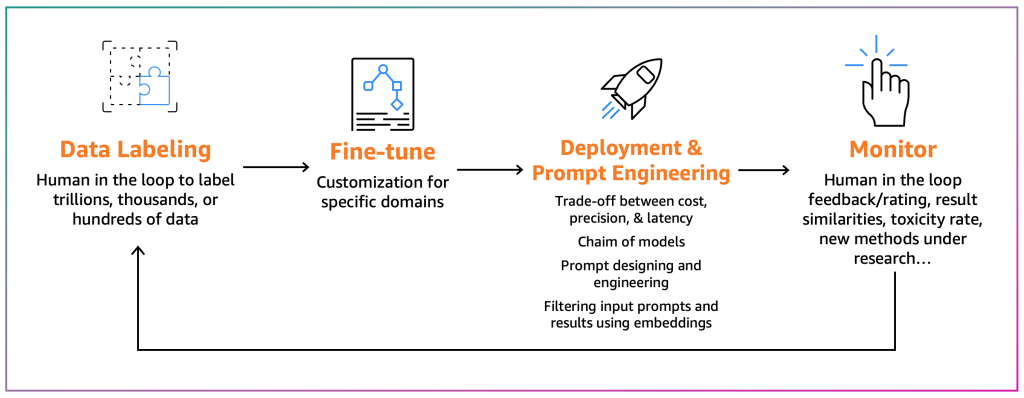
В настоящее время существуют два механизма настройки:
- Настройка – с помощью FM и помеченных данных обучающая задача пересчитывает веса и смещения слоев модели глубокого обучения. Этот процесс может быть вычислительно интенсивным и требует представительного объема данных, но может давать точные результаты.
- Эффективная настройка параметров (PEFT) – вместо пересчета всех весов и смещений исследователи показали, что добавляя дополнительные небольшие слои к моделям глубокого обучения, можно достичь удовлетворительных результатов (например, LoRA). PEFT требует меньшей вычислительной мощности, чем глубокая настройка, и обучающей задачи с меньшим объемом входных данных. Недостатком является возможное снижение точности.
Следующая диаграмма иллюстрирует эти механизмы.
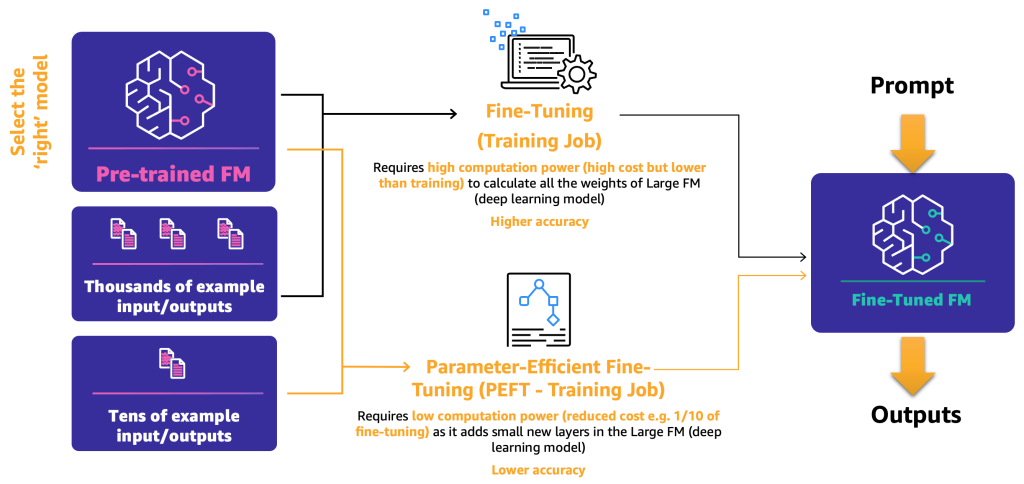
Теперь, когда мы определили два основных метода настройки, следующим шагом является определение того, как мы можем развернуть и использовать открытый и собственный FM.
С открытыми FMs настройщики могут загрузить артефакт модели и исходный код с веб-сайта, например, используя Hugging Face Model Hub. Это дает вам гибкость глубокой настройки модели, сохранения ее в локальный реестр моделей и развертывания на конечную точку Amazon SageMaker. Для этого требуется подключение к Интернету. Чтобы поддерживать более безопасные среды (например, для клиентов в финансовом секторе), вы можете загрузить модель на сервер, выполнить все необходимые проверки безопасности и загрузить их в локальный бакет на учетную запись AWS. Затем настройщики используют FM из локального бакета без подключения к Интернету. Это обеспечивает конфиденциальность данных, и данные не передаются через Интернет. Следующая диаграмма иллюстрирует этот метод.
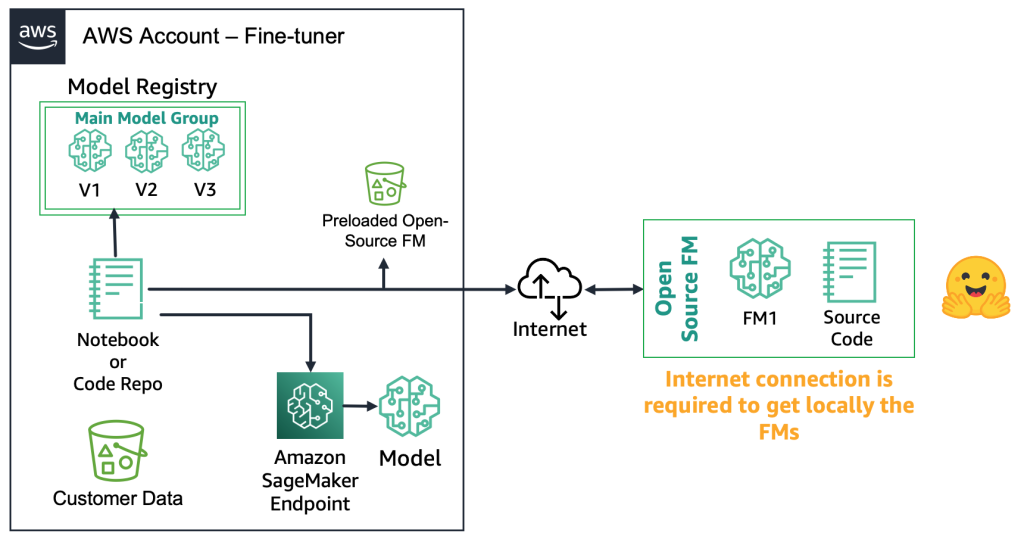
С собственными FM-моделями процесс развертывания отличается, поскольку специалисты по настройке не имеют доступа к артефакту модели или исходному коду. Модели хранятся в учетных записях и реестрах моделей FM-поставщика AWS. Чтобы развернуть такую модель на конечную точку SageMaker, специалисты по настройке могут запросить только пакет модели, который будет развернут непосредственно на конечную точку. Для этого процесса требуется использование данных клиента в учетных записях собственного FM-поставщика, что вызывает вопросы о использовании конфиденциальных данных клиента в удаленной учетной записи для проведения настройки и размещения моделей в реестре моделей, который используется несколькими клиентами. Это приводит к проблеме многопользовательского хостинга, которая становится более сложной, если собственным FM-поставщикам необходимо обслуживать эти модели. Если специалисты по настройке используют Amazon Bedrock, эти проблемы решаются — данные не передаются через Интернет, и у поставщиков FM нет доступа к данным специалистов по настройке. Те же проблемы возникают и для моделей с открытым исходным кодом, если специалисты по настройке хотят предоставлять модели от нескольких клиентов, например, как в приведенном ранее примере с веб-сайтом, на который тысячи клиентов будут загружать персонализированные изображения. Однако эти сценарии можно считать контролируемыми, поскольку в них участвует только специалист по настройке. Ниже приведена схема, иллюстрирующая этот метод.
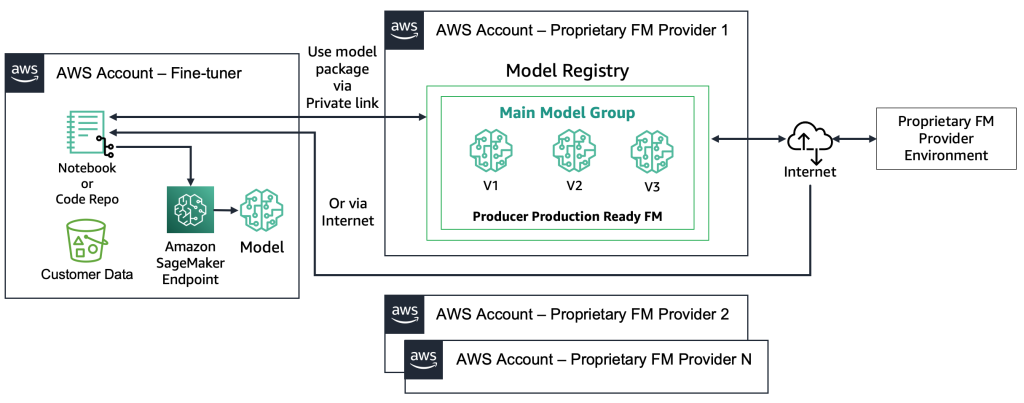
С технологической точки зрения архитектура, которую должен поддерживать специалист по настройке, похожа на архитектуру MLOps (см. следующую схему). Настройка должна проводиться в среде разработки путем создания ML-пайплайнов, например, с использованием Amazon SageMaker Pipelines; выполнение предварительной обработки, настройка (задание обучения) и постобработка; и отправка настроенных моделей в локальный реестр моделей в случае использования FM с открытым исходным кодом (в противном случае новая модель будет сохранена в окружении собственного FM-поставщика). Затем на этапе предварительного производства нам нужно протестировать модель, как описано для сценария потребителей. Наконец, модель будет обслуживаться и контролироваться в производстве. Обратите внимание, что текущая (настроенная) FM требует конечных точек с графическими процессорами. Если нам нужно развернуть каждую настроенную модель на отдельную конечную точку, это может увеличить затраты в случае сотен моделей. Поэтому нам нужно использовать многомодельные конечные точки и решить проблему многопользовательского хостинга.
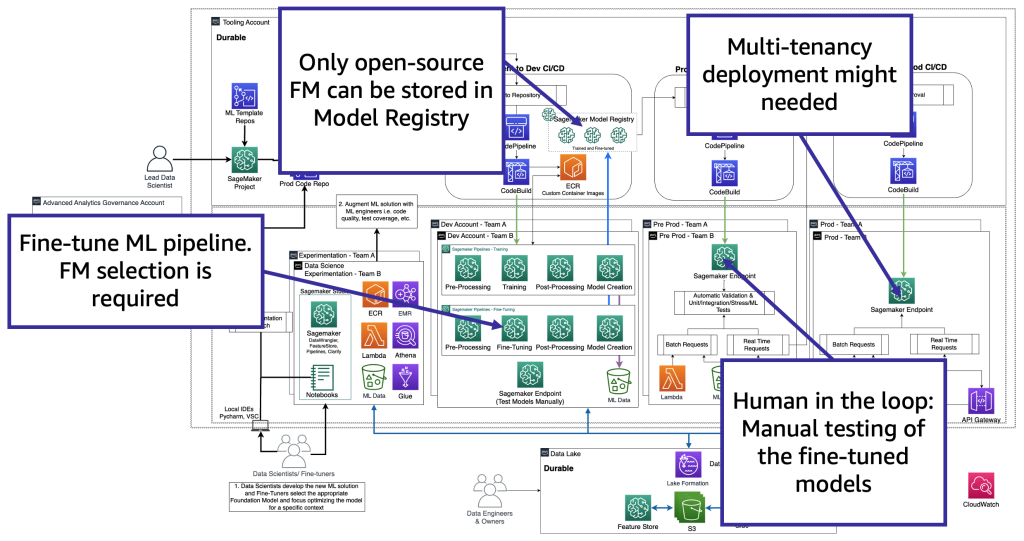
Специалисты по настройке адаптируют модель FM на основе определенного контекста, чтобы использовать ее для своих бизнес-целей. Это означает, что большую часть времени специалисты по настройке также являются потребителями, которым необходимо поддерживать все уровни, как мы описали в предыдущих разделах, включая разработку приложений генеративного искусственного интеллекта, озеро данных и сетку данных, а также MLOps.
Следующая схема иллюстрирует полный жизненный цикл настройки FM, который специалисты по настройке должны предоставить конечному пользователю генеративного искусственного интеллекта.
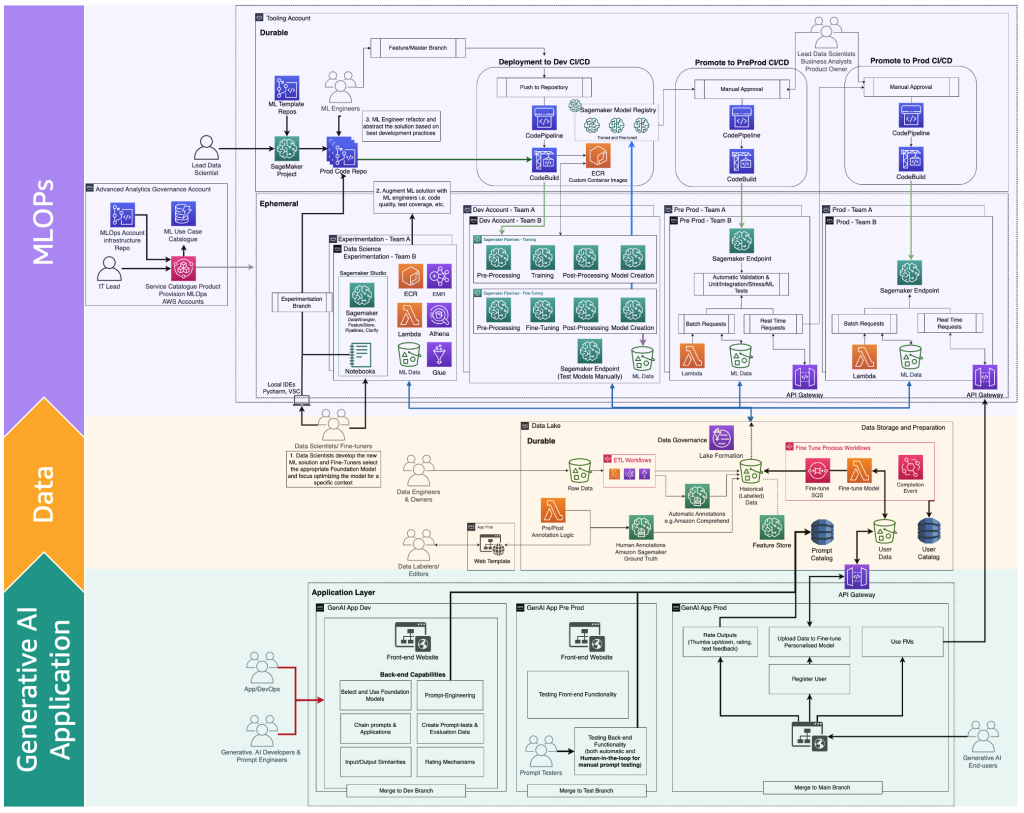
На следующей схеме показаны ключевые шаги.
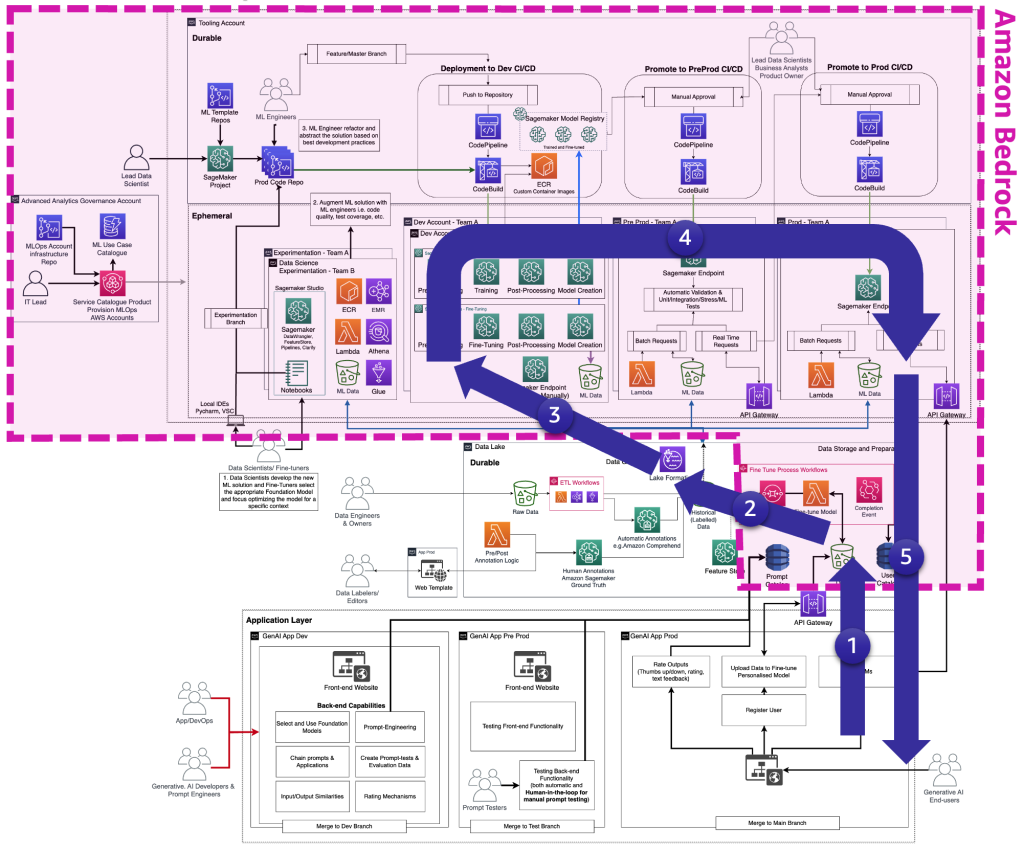
Ключевые шаги следующие:
- Конечный пользователь создает личную учетную запись и загружает личные данные.
- Данные хранятся в озере данных и предварительно обрабатываются в соответствии с форматом, ожидаемым FM.
- Это запускает ML-пайплайн настройки, который добавляет модель в реестр моделей,
- Оттуда модель либо развертывается в производство с минимальным тестированием, либо модель проходит обширное тестирование с использованием HIL и ручных шлюзов одобрения.
- Настроенная модель становится доступной для конечных пользователей.
Поскольку эта инфраструктура сложна для не корпоративных клиентов, AWS выпустила Amazon Bedrock, чтобы снять с них труд создания таких архитектур и приблизить настроенные FM к производству.
Функции FMOps и LLMOps и отличительные особенности персон и процессов
На основе предшествующих пользовательских путей (пользователь, производитель и настройщик), требуются новые персоны с определенными навыками, как показано на следующей схеме.
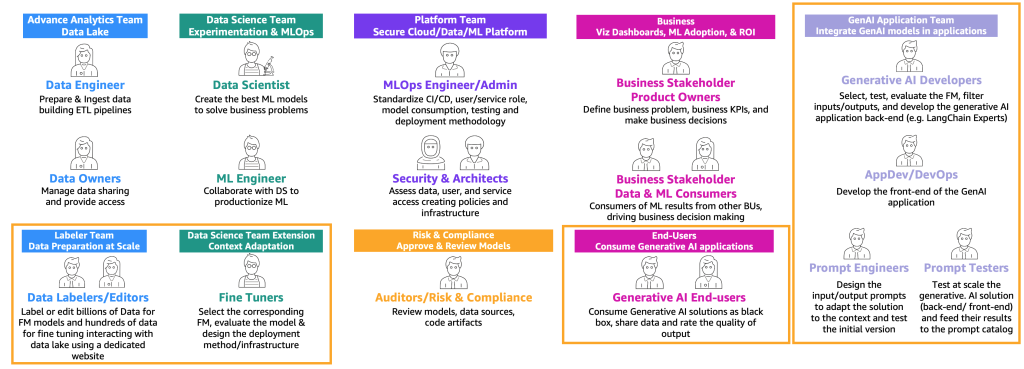
Новые персоны представлены ниже:
- Маркеры и редакторы данных – Эти пользователи размечают данные, такие как пары <текст, изображение> или подготавливают неразмеченные данные, такие как свободный текст, и расширяют команду продвинутой аналитики и среды хранения данных.
- Настройщики – Эти пользователи обладают глубокими знаниями в области FM и умеют их настраивать, расширяя команду по науке о данных, которая будет сосредоточена на классическом машинном обучении.
- Разработчики генеративного ИИ – Они обладают глубокими знаниями в области выбора FM, цепочек подсказок и приложений, и фильтрации входных и выходных данных. Они входят в состав новой команды – команды приложений генеративного ИИ.
- Инженеры подсказок – Эти пользователи разрабатывают входные и выходные подсказки для адаптации решения к контексту и тестируют и создают первую версию каталога подсказок. Их команда – команда приложений генеративного ИИ.
- Тестировщики подсказок – Они проводят масштабное тестирование генеративного ИИ-решения (бэкэнд и фронтэнд) и передают свои результаты для расширения каталога подсказок и оценочного набора данных. Их команда – команда приложений генеративного ИИ.
- Разработчики приложений и DevOps – Они разрабатывают фронтэнд (например, веб-сайт) генеративного ИИ-приложения. Их команда – команда приложений генеративного ИИ.
- Пользователи генеративного ИИ – Эти пользователи используют генеративные ИИ-приложения как черные ящики, делятся данными и оценивают качество вывода.
Расширенную версию карты процессов MLOps с учетом генеративного ИИ можно проиллюстрировать следующей схемой.
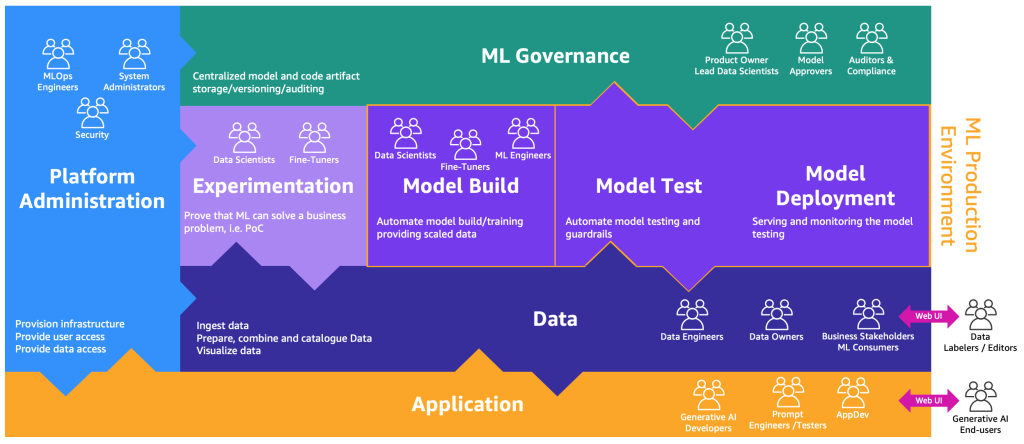
Новый слой приложения – это среда, в которой разработчики генеративного ИИ, инженеры подсказок, тестировщики и разработчики приложений создают бэкэнд и фронтэнд генеративных ИИ-приложений. Пользователи генеративного ИИ взаимодействуют с фронтэндом генеративных ИИ-приложений через интернет (например, веб-интерфейс). С другой стороны, маркеры и редакторы данных должны предварительно обрабатывать данные без доступа к бэкэнду озера данных или сетке данных. Поэтому взаимодействие с данными безопасно осуществляется через веб-интерфейс (веб-сайт) с редактором. Функциональность такого взаимодействия предоставляется SageMaker Ground Truth «из коробки».
Заключение
MLOps может помочь нам эффективно внедрять модели машинного обучения в продакшн. Однако для операционализации генеративных ИИ-приложений требуются дополнительные навыки, процессы и технологии, что приводит к FMOps и LLMOps. В этой статье мы определили основные концепции FMOps и LLMOps и описали ключевые отличия от возможностей MLOps в терминах людей, процессов, технологий, выбора и оценки моделей FM. Кроме того, мы проиллюстрировали мыслительный процесс разработчика генеративного ИИ и жизненный цикл разработки генеративного ИИ-приложения.
В будущем мы сосредоточимся на предоставлении решений в соответствии с областью, о которой мы говорили, и предоставим более подробные сведения о том, как интегрировать мониторинг FM (например, токсичности, предвзятости и галлюцинаций) и архитектурные шаблоны сторонних или частных источников данных, такие как Retrieval Augmented Generation (RAG), в FMOps/LLMOps.
Чтобы узнать больше, обратитесь к дорожной карте основ MLOps для предприятий с Amazon SageMaker и попробуйте полноценное решение в реализации практик MLOps с предварительно обученными моделями Amazon SageMaker JumpStart.
Если у вас есть какие-либо комментарии или вопросы, пожалуйста, оставьте их в разделе комментариев.






