Упорядочивание структуры сдвигов набора данных Пример
Упорядочивание структуры сдвигов набора данных Пример' can be condensed to 'Упорядочивание структуры сдвигов данных'.
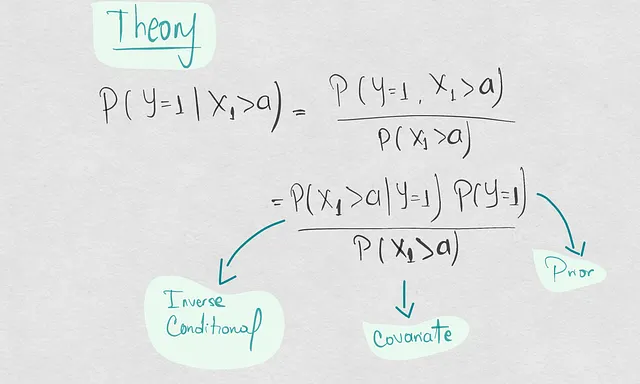
Как изменяется условная вероятность в зависимости от трех элементов вероятности
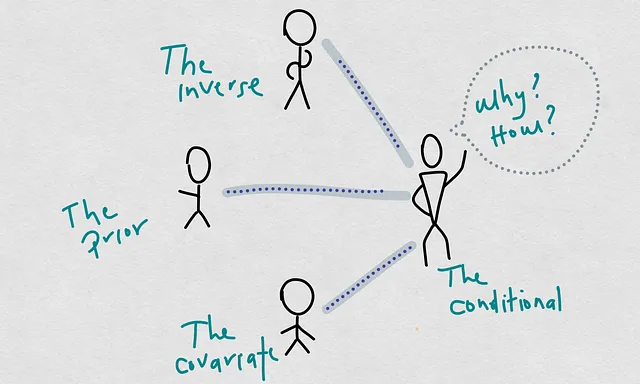
Недавно я говорил о причинах снижения производительности модели, то есть о снижении качества их прогнозов по сравнению с моментом обучения и развертывания наших моделей. В этом другом посте я предложил новый способ мышления о причинах снижения модели. В этой концепции так называемая условная вероятность становится глобальной причиной.
Условная вероятность, по определению, состоит из трех вероятностей, которые я называю специфическими причинами. Самое важное, что я понял в результате этой реструктуризации концепций, заключается в том, что сдвиг ковариации и условный сдвиг не являются двумя разными или параллельными концепциями. Условный сдвиг может происходить в результате сдвига ковариации.
С помощью этой реструктуризации я считаю, что становится легче думать о причинах и более логично интерпретировать наблюдаемые сдвиги в наших приложениях.
Это схема причин и производительности модели для моделей машинного обучения:
- Изучение передовой генеративной искусственной интеллекта | Условные VAE
- Ускорение прибытия энергии фьюжн с помощью искусственного интеллекта и доступности
- Генеративное искусственное интеллект инновации с этическим и творческим подходом для беспроблемного передачи данных
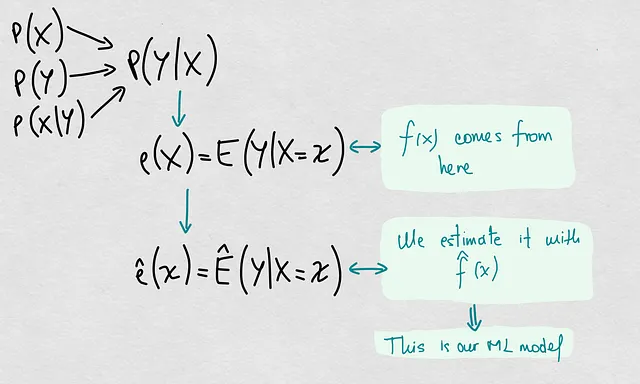
В этой схеме мы видим четкий путь, который соединяет причины с производительностью прогнозов наших оцененных моделей. Одно из основных предположений, которое мы должны сделать в статистическом обучении, состоит в том, что наши модели являются “хорошими” оценщиками реальных моделей (реальных границ принятия решений, реальных регрессионных функций и т. д.). “Хорошими” может означать разные вещи, такие как несмещенные оценщики, точные оценщики, полные оценщики, достаточные оценщики и т. д. Но для упрощения и предстоящего обсуждения давайте скажем, что они хороши в том смысле, что у них маленькая ошибка прогнозирования. Другими словами, мы предполагаем, что они являются представителями реальных моделей.
Исходя из этого предположения, мы можем искать причины снижения модели оцененной модели в вероятностях P(X), P(Y), P(X|Y), и следовательно, P(Y|X).
Итак, сегодня мы будем приводить примеры и анализировать различные сценарии, чтобы увидеть, как P(Y|X) изменяется в зависимости от 3 вероятностей P(X|Y), P(X) и P(Y). Мы сделаем это, используя некоторую выборку точек в двумерном пространстве и вычисляя вероятности на основе этих образцов так, как это делал бы Лаплас. Цель состоит в том, чтобы осмыслить иерархию причин снижения модели, где P(Y|X) является глобальной причиной, а остальные три – специфическими причинами. Таким образом, мы можем понять, как потенциальный сдвиг ковариации может иногда быть аргументом условного сдвига, а не отдельным сдвигом.
Пример
Случай, который мы рассмотрим сегодня, очень простой. У нас есть пространство двух ковариат X1 и X2, а выходная переменная Y является бинарной. Вот как выглядит наше пространство модели:
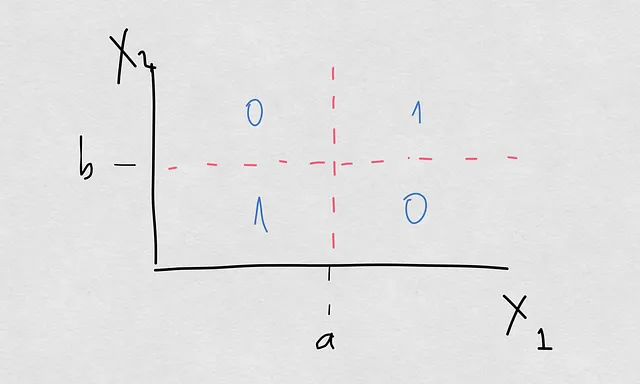
Вы видите, что пространство организовано в 4 квадранта, и граница принятия решений в этом пространстве – это крест. Это означает, что модель классифицирует образцы в класс 1, если они находятся в 1-м и 3-м квадрантах, и в класс 0 в противном случае. В рамках этого упражнения мы рассмотрим различные случаи, сравнивая P(Y=1|X1>a). Это будет наша условная вероятность для демонстрации. Если вы задаетесь вопросом, почему мы не берем также X2, это только для упрощения упражнения. Это не влияет на выводы, которые мы хотим понять.
Если у вас все еще остается горькое чувство, взятие P(Y=1|X1>a) эквивалентно P(Y=1|X1>a, -inf <X2 < inf), поэтому теоретически мы все еще учитываем X2.
Ссылочная модель
Итак, для начала мы рассчитываем нашу вероятность демонстрации и получаем 1/2. Практически здесь наша группа образцов достаточно однородна во всем пространстве, и априорные вероятности также однородны:
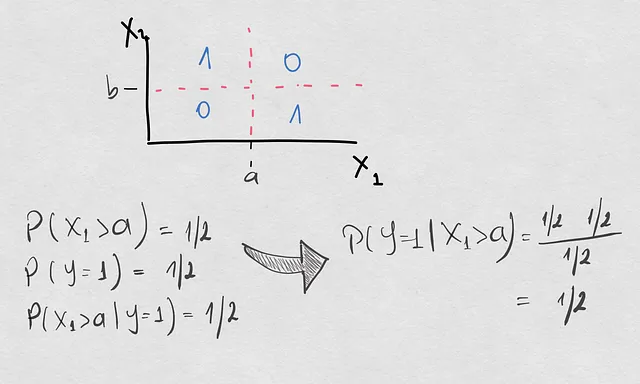
Появление сдвигов
- Появляется дополнительный образец в нижнем правом квадранте. Итак, первый вопрос, который мы задаем: речь идет о сдвиге ковариации?
Ну, да, потому что выборка в X1>a больше, чем раньше. Так что это только сдвиг ковариации, а не условного сдвига? Посмотрим. Вот расчет всех тех же вероятностей, что и раньше, с обновленным набором точек (вероятности, которые изменились, выделены оранжевым цветом):
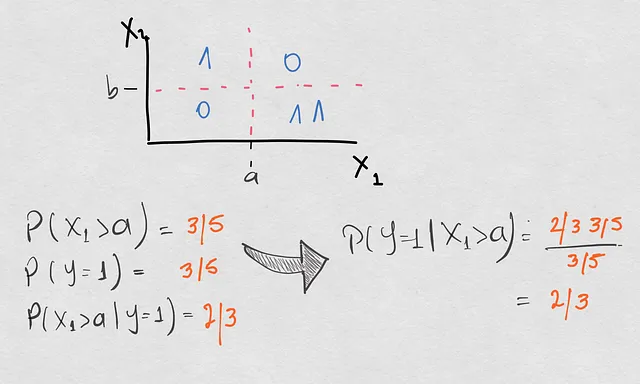
Что мы увидели здесь? Фактически, мы получили не только сдвиг ковариации, но и в целом все вероятности изменились. Априорная вероятность также изменилась, потому что сдвиг ковариации привел к появлению новой точки класса 1, что сделало встречаемость этого класса больше, чем класса 2. Затем также изменилась обратная вероятность P(X1>a|Y=1), именно из-за сдвига априорной вероятности. Все это в целом привело к условному сдвигу, поэтому теперь у нас есть P(Y=1|X1>a)=2/3 вместо 1/2.
Вот мысль. Очень важная, на самом деле.
С этим сдвигом в распределении выборки мы получили сдвиги во всех вероятностях, которые играют роль во всей схеме наших моделей. Тем не менее, граница принятия решений, основанная на начальной выборке, осталась действительной для этого сдвига.
Что это означает?
Несмотря на то, что мы получили условный сдвиг, граница принятия решений не обязательно ухудшилась. Поскольку граница принятия решений определяется ожидаемым значением, если мы рассчитываем это значение на основе текущего сдвига, граница может остаться прежней, но с другой условной вероятностью.
2. Образцы в первом квадранте больше не существуют.
Так что для X1>a вещи остались неизменными. Посмотрим, что происходит с условной вероятностью, которую мы демонстрируем, и ее элементами.

Интуитивно, поскольку в X1>a вещи остаются неизменными, условная вероятность осталась прежней. Однако, когда мы смотрим на P(X1>a), мы получаем 2/3 вместо 1/2 по сравнению с обучающей выборкой. Итак, у нас есть сдвиг ковариации без условного сдвига.
С математической точки зрения, как может меняться вероятность ковариации без изменения условной вероятности? Это происходит потому, что P(Y=1) и P(X1>a|Y=1) изменились соответственно вероятности ковариации. Таким образом, компенсация компенсирует неизменную условную вероятность.
С этими изменениями, как и раньше, граница принятия решений осталась действительной.
3. Бросая несколько образцов в разные квадранты, сохраняя действительную границу принятия решений.
У нас здесь 2 дополнительные комбинации. В одном случае приоритет остался прежним, в то время как две другие вероятности изменились, не меняя условную вероятность. Во втором случае только обратная вероятность была связана с условным сдвигом. Проверьте сдвиги здесь ниже. Последний из них довольно важный, так что не пропустите его!
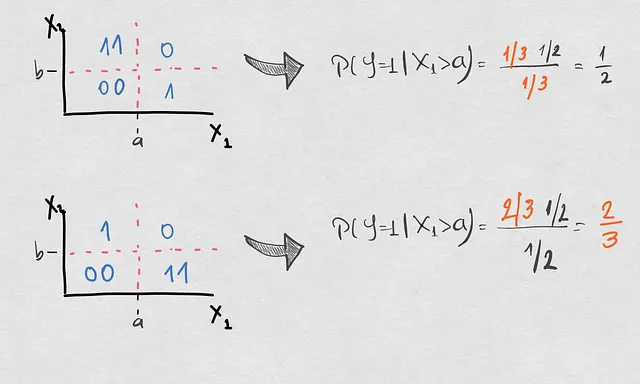
Теперь у нас есть довольно надежная перспектива того, как условная вероятность может изменяться в зависимости от других трех вероятностей. Но, что самое важное, мы также знаем, что не все условные сдвиги делают недействительной существующую границу принятия решений. Что с этим?
Дрейф концепции
В предыдущем посте я также предложил более конкретный способ определения дрейфа концепции (или сдвига концепции). Предложение такое:
Мы называем изменение концепции, когда граница принятия решений или функция регрессии становятся недействительными при сдвиге играющих вероятностей.
Таким образом, ключевой момент здесь заключается в том, что если граница принятия решений становится недействительной, то, безусловно, происходит условный сдвиг. Обратное, как мы обсуждали в предыдущем посте и как мы видели в приведенных выше примерах, не всегда верно.
Это может быть не так удивительно с практической точки зрения, потому что это означает, что для того, чтобы действительно знать, есть ли дрейф концепции, нам может понадобиться повторно оценить границу или функцию. Но по крайней мере, с точки зрения нашего теоретического понимания, это так же увлекательно.
Вот пример, в котором у нас есть дрейф концепции, естественно с условным сдвигом, но на самом деле без сдвига ковариаты или приоритета.
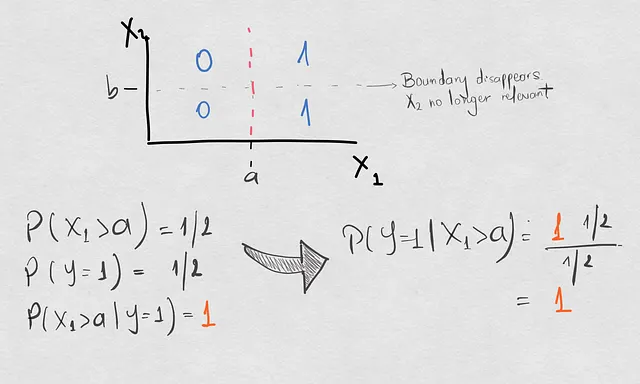
Как круто разделение компонентов? Единственный элемент, который изменился здесь, это обратная вероятность, но, в отличие от предыдущего сдвига, который мы изучали выше, это изменение обратной вероятности было связано с изменением границы принятия решений. Теперь действительной границей принятия решений является только разделение в соответствии с X1>a, отбрасывая границу, определяемую X2.
Что мы узнали?
Мы медленно продвигались по разложению причин деградации модели. Мы изучали различные сдвиги элементов вероятности и как они связаны с деградацией предсказательной способности наших моделей машинного обучения. Самые важные идеи:
- Условный сдвиг является глобальной причиной деградации предсказательной способности в моделях машинного обучения
- Конкретные причины – это сдвиг ковариаты, сдвиг приоритета и сдвиг обратной вероятности
- Мы можем иметь много разных случаев сдвигов вероятности, при этом граница принятия решений остается действительной
- Изменение границы принятия решений вызывает условный сдвиг, но обратное не всегда верно!
- Дрейф концепции может быть более конкретно связан с границей принятия решений, а не с общим распределением условных вероятностей
Что следует из этого? Переорганизация наших практических решений с учетом этой иерархии определений – это самое большое приглашение, которое я делаю. Мы можем найти так много желанных ответов на наши текущие вопросы относительно способа мониторинга наших моделей.
Если вы в настоящее время работаете над мониторингом производительности модели с использованием этих определений, не стесняйтесь делиться своими мыслями по этой схеме.
Счастливого мышления всем!