Хотите улучшить короткосрочное прогнозирование? Попробуйте Demand Sensing
Хотите улучшить прогнозирование? Попробуйте Demand Sensing
Когда традиционные подходы к прогнозированию достигают плато в точности, как мы можем добиться дальнейшего улучшения?
Введение
Прогнозирование спроса – это процесс оценки продаж организации на определенный горизонт в будущем. Краткосрочные прогнозы спроса обычно охватывают период от 1 до 3 месяцев, в то время как среднесрочные прогнозы могут охватывать период от 6 до 18 месяцев. Долгосрочные прогнозы часто достигают 3-5 лет. Прогнозирование помогает бизнесу принимать решения о том, что, когда и сколько продавать, какой запас держать и где инвестировать в возможности для будущего, чтобы удовлетворить динамичный спрос клиентов. Компании обычно полагаются на исторические тенденции, с учетом информации от клиентов, а также учитывают акции или распродажи, чтобы создать прогноз спроса.
Прогноз спроса важен по нескольким причинам. Он занимает верхнюю позицию в процессе планирования продаж и операций (S&OP), где прогнозы, сгенерированные на этом этапе, передаются на другие этапы, включая планирование поставок, планирование производства, планирование логистики и оптимизацию запасов. Крайне важно, чтобы прогноз спроса был максимально точным, чтобы избежать затрат, связанных с избыточным или недостаточным запасом. Чрезмерное прогнозирование может привести к замораживанию рабочего капитала в запасах. С другой стороны, постоянное недооценивание спроса может привести к нехватке товаров у клиентов или к необходимости срочно совершать заказы с использованием более дорогих сырьевых материалов и более дорого транспортировать их. Точный план помогает избежать подобных ситуаций, обеспечивая производство нужного количества товара в нужном месте в нужное время, а также обеспечивает высокий уровень обслуживания и снижение затрат на хранение.
Проблемы прогнозирования
“Прогнозирование очень сложно, особенно если речь идет о будущем.”
Эта цитата часто приписывается Нильсу Бору (есть некоторые дебаты о том, сказал ли он это), одному из ведущих физиков XX века. Хотя это шутливое замечание относится к прогнозированию, оно подчеркивает внутреннюю сложность прогнозирования. Помимо того, что мы не знаем будущего, существуют и другие проблемы, связанные с подходами к прогнозированию.
- Язык местоположений Оценка умения генеративного ИИ в геокодировании
- Байесовская оптимизация и гипербэнд (BOHB) настройка гиперпараметров с примером
- Закрытое программное обеспечение против программного обеспечения с открытым исходным кодом для аннотации изображений
· Изменения в деловой среде – например, замена продукта аналогами может снизить его спрос. В альтернативном случае, новые приложения продукта могут увеличить спрос по сравнению с историческими тенденциями.
· Изменение бизнес-модели – организация может изменить свою модель функционирования и стратегию бизнеса. Например, химическая компания может решить перейти от производства товаров широкого потребления к более специализированным продуктам, и тогда исторические модели спроса могут уже не работать.
· Доступность данных – исторические данные о продажах, данные о клиентах и иерархии продуктов, а также данные о заказах в режиме реального времени могут храниться в разных системах.
· Качество данных – это может включать проблемы, такие как неточные данные из-за ошибок ввода или данные, введенные на разных и непоследовательных уровнях детализации для разных элементов данных.
Подходы к прогнозированию
Прогнозирование может быть основано на количественных или качественных методах. Количественные методы в основном основаны на анализе временных рядов, где мы пытаемся выявить тенденции со временем (например, рост, сезонность) на основе исторических данных. В других количественных случаях мы можем создавать эконометрические модели, связывающие прогноз спроса с факторами, имеющими значение для бизнеса. При качественном подходе мы полагаемся на “мудрость толпы” и пытаемся оценить будущее на основе коллективного мнения экспертов или опросов. Существует несколько информативных ресурсов по методам прогнозирования, доступных онлайн; некоторые из них показаны ниже:
The Ultimate Guide to Demand Forecasting Methods: Boost Sales and Optimize Inventory – nexocode
Откройте секреты прогнозирования спроса в нашем руководстве! Узнайте методы, проблемы, преимущества и роль искусственного интеллекта…
nexocode.com
Прогнозирование спроса: все, что вам нужно знать
Прогнозирование спроса является важным для компаний на быстрорастущих или волатильных рынках, поскольку оно помогает им видеть будущее…
www.netsuite.com
Как выбрать правильную технику прогнозирования
Что каждому менеджеру следует знать о различных видах прогнозирования и времени, когда их следует использовать.
hbr.org
6 видов прогнозирования спроса и преимущества проекции
Прогнозирование спроса помогает бизнесам принимать более разумные решения относительно запасов и мощностей. Мы рассматриваем различные виды спроса…
www.thefulfillmentlab.com
Краткосрочное чувствование спроса
Краткосрочное чувствование спроса – это техника прогнозирования, которая использует ведущие индикаторы для прогнозирования продаж товаров на ближайший период. Она использует комбинацию исторических данных и информации в режиме реального времени для составления прогнозов на дневном или недельном уровне. Таким образом, она улавливает некоторые ключевые динамики на рынке, особенно в волатильные времена. Таким образом, она помогает планировщикам корректировать свои планы по производству и логистике, основываясь на более точном и точном прогнозе, тем самым повышая устойчивость цепи поставок и снижая запасы и транспортные расходы. Существует множество онлайн-ресурсов по чувствованию спроса – вот некоторые из них:
Что такое чувствование спроса – решения и услуги ИИ/МО | Премьер-партнер Google Cloud
Параметры Традиционное прогнозирование спроса Чувствование спроса Традиционные методы прогнозирования спроса основаны на исторических…
pluto7.com
Статья – Кирни
Редактировать описание
www.kearney.com
Ожидается, что чувствование спроса будет иметь высокую экономическую ценность (в виде сокращения затрат или избежания потери дохода) просто из-за огромного объема отгрузок. Из-за детализации прогнозов и частоты их обновления, чувствование спроса может быть интенсивным с точки зрения данных и вычислений. Но с увеличением вычислительной мощности, доступной для потребителей, ожидается, что трассируемость будет высокой. Результаты чувствования спроса в основном хорошо объяснимы, поскольку мы обычно используем модели, основанные на линейной регрессии, для этих приложений. В большинстве случаев результаты могут быть проанализированы для ясного объяснения предсказаний заинтересованным сторонам. Рекомендации по обновлению прогноза от чувствования спроса являются действенными, поскольку это внутреннее решение организации изменить производство на основе изменений прогноза. Приложения чувствования спроса также в основном устойчивы с точки зрения обновления входных данных, поскольку они основаны на данных о заказе в режиме реального времени, генерируемых ежедневно.
Упрощенный подход к чувствованию спроса
Чувствование спроса опирается на соответствующие ведущие индикаторы для оценки прогноза продаж. Скорость, с которой размещаются заказы клиентов, может быть одним из таких ведущих индикаторов ближайшего спроса. В некоторых отраслях, таких как нефтехимическая промышленность, клиенты обычно размещают заказы, чтобы их можно было зарегистрировать в каждом месяце за несколько недель до начала. В этой статье мы рассказываем о подходе к чувствованию спроса на основе заказов клиентов для химической компании.
В этом подходе предполагается, что если заказы размещаются с более быстрой скоростью в начале по сравнению с историческими тенденциями размещения заказов, конечный месячный спрос будет высоким и наоборот. Предлагается дополнить традиционный процесс прогнозирования анализом тенденций заказов клиентов в середине каждого месяца для оценки спроса на продукцию на следующий месяц. Эта ранняя информация будет очень полезна для цепи поставок и менеджеров продукта для принятия решений по корректировке производства и ценообразованию. Анализ также позволит выявить клиентов, которые, скорее всего, разместят заказы ниже своего прогноза, что позволит оставшуюся емкость использовать для клиентов, которым требуется дополнительный продукт сверх их прогнозируемых объемов. Это позволит активно «перераспределять» продукт между двумя группами клиентов, снижая блокировки и задержки заказов и обогащая опыт клиентов.
Для создания решения машинного обучения для сценария предварительного прогнозирования спроса мы следуем ряду шагов, включая сбор данных, исследовательский анализ данных, обработку данных (очистку и создание признаков), разработку и уточнение модели, получение действенных выводов и рекомендаций. Основная цель – предсказать текущий и следующий месяц спроса с заданной детализацией (например, семейство продуктов, категория клиента) на основе атрибутов заказа клиента. Подробности каждого шага перечислены ниже:
a. Сбор данных – исходя из типичной ситуации для этого сценария в компании, занимающейся товарами, мы предполагаем, что каждый продукт (или семейство продуктов) имеет десятки или сотни клиентов, которые размещают заказы заранее. Чтобы учесть годовые и сезонные тенденции в заказах клиентов, мы собираем данные как минимум за последние 36 месяцев. Мы собираем заказы на продажу, которые включают данные о запрошенных объемах, дате заказа на продажу, месяце бронирования спроса, информации о клиенте, включая категорию и географию клиента, атрибуты продукта, включая семейство продуктов и сегмент рынка. Мы начинаем с месяца бронирования спроса и ищем общий объем продукции, запрошенный в заказах на продажу, на ежедневной основе (рабочие дни, исключая выходные и праздничные дни) за двухмесячный период, начиная с первого рабочего дня предыдущего месяца (CM-1) и заканчивая концом месяца бронирования спроса (CM). При этом предполагается, что заказы не размещаются раньше этой даты (первый рабочий день предыдущего месяца). Также нам необходимо удалить отмененные или возвращенные заказы из анализа. В таблице 1 показаны образцовые данные в формате таблицы.

*WD – рабочий день
b. Исследовательский анализ данных – мы начинаем с получения представления о размере данных (строк и столбцов) и количестве и типе признаков (числовые против категориальных). Мы также определяем количество нулевых значений в каждом столбце. Мы визуализируем числовые столбцы (с помощью гистограмм и боксплотов) для изучения формы данных (включая среднее, медиану, асимметрию, выбросы), и категориальные данные (с помощью столбчатых диаграмм) для подтверждения уникальных значений и выявления любых ошибочных значений, которые следует исправить.
c. Обработка данных – на этом этапе мы удаляем выбросы (например, отрицательные значения или крайне высокие значения числовых столбцов). Мы также выбираем признаки и выполняем создание признаков. В этом случае мы выбираем признаки, которые имеют более высокую агрегацию по сравнению с предсказываемой переменной. Например, если мы предсказываем спрос на семейство продуктов, мы выбираем сегмент рынка, географию, накопленный объем заказов и ежемесячный прогноз продаж базового уровня в качестве признаков-предикторов. Накопленные заказы на определенный рабочий день (Таблица 2) получаются из ежедневных объемов заказов в рамках создания признаков. На рисунке 1 показан пример того, как могут варьироваться накопленные заказы в зависимости от рабочего дня.

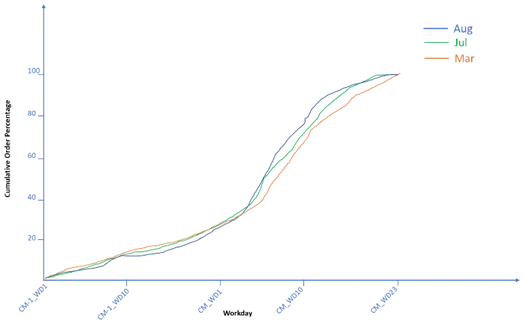
d. Разработка и уточнение модели – в этом сценарии рекомендуется использовать множественную линейную регрессию. Ожидается, что это будет “постепенное” решение, где у нас будет разные регрессионные функции для каждого рабочего дня. С 36 месяцами данных и сотнями клиентов для каждого семейства продуктов у нас будет тысячи точек данных в обучающем наборе для каждого семейства продуктов. Мы начинаем с определения функции потерь, которая поможет нам построить модель, обеспечивающую наиболее точные прогнозы спроса. Мы выбираем несколько мер точности, включая среднюю абсолютную ошибку (MAE), среднюю абсолютную процентную ошибку (MAPE) и R2, и тестируем производительность разных моделей по этим метрикам (мы хотим, чтобы R2 был высоким, а ошибки были низкими). Сырая ошибка просто является разницей между месячным прогнозом спроса и фактическими данными на уровне семейства продуктов. В терминах подготовки данных мы сначала разделяем данные на обучающий набор (80% данных) и тестовый набор (20% данных). Пропущенные или нулевые значения обрабатываются отдельно для каждого набора, чтобы избежать утечки данных. Если пропущенные значения составляют большую часть признака, мы можем полностью удалить этот признак, так как он имеет мало предсказательной силы. Если пропущенные значения присутствуют только в нескольких строках, мы можем удалить строки с пропущенными значениями. Мы также можем заполнять пропущенные значения центральными значениями, такими как медиана столбца, если это числовой признак, или мода, если это категориальный признак. Кроме того, мы также преобразуем категориальные переменные в числовой формат с помощью кодирования one-hot. Для масштабирования данных для ввода в модель линейной регрессии мы делим зависимую переменную (месячный прогноз спроса) на базовый прогноз продаж и накопленные заказы (независимая переменная) на базовый прогноз продаж. Коэффициенты модели регрессии определяют значимость признаков при объяснении вариации предсказываемой переменной.
e. Практические исследования и рекомендации — спрос, предсказанный AI-приложением, может быть выше или ниже базового прогноза продаж. Для объяснения результатов заинтересованным сторонам можно использовать один подход — сравнение исторических кривых заказов с заказами в реальном времени (см. рисунок 2).
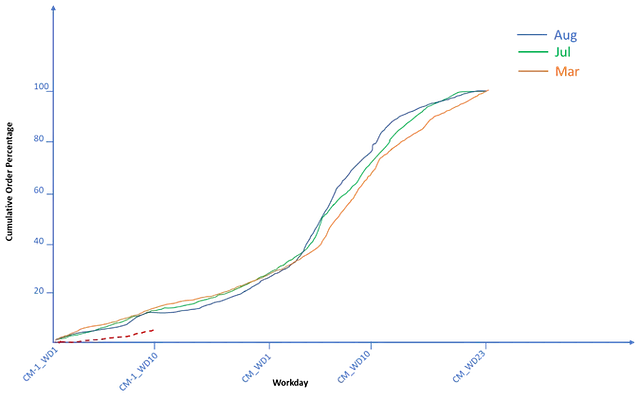
*Здесь приведены только 3 месяца исторических кривых накопленного процента заказов для иллюстративных целей; для реального обсуждения мы включили бы не менее 12 месяцев данных.
На данном рисунке исторические кривые накопленного процента заказов изображены сплошными линиями, тогда как заказы в реальном времени (в процентах от базового прогноза продаж на следующий месяц) изображены пунктирной линией. Мы видим, что в выбранных исторических месяцах около 12% от общего спроса заказывается к 10-му рабочему дню предыдущего месяца, но мы наблюдаем около 5% прогноза, что указывает на более низкий спрос, чем ожидалось по базовому прогнозу. В данном примере, с согласия заинтересованных сторон обновить прогнозы спроса, мы можем принять решения о снижении производства для данной группы товаров, а также определить клиентов, заказывающих меньше, чем они прогнозируют. В общем случае, прогнозы можно выполнять ежедневно, чтобы предоставлять сигналы о производстве и запасах производству, а также командам по продажам — о слабости или силе спроса. Сами модели искусственного интеллекта/машинного обучения могут переобучаться каждый квартал или при изменении бизнес-структуры.
Оценка экономической ценности
Один из способов оценки монетизации неточности прогнозирования заключается в учете потерянных доходов от отсутствия товара на складе и увеличенных затрат на хранение излишне непроданного товара. В то время как колебания в прогнозе могут уравновешиваться на протяжении более длительных периодов времени, постоянный перекос в прогнозе может привести к несбалансированному портфелю товаров. Потерянные доходы от краткосрочного отсутствия товара могут повлиять на бизнес в долгосрочной перспективе, если клиенты решат навсегда уйти из организации в пользу конкурентов. Мы иллюстрируем потерянные доходы через упрощенный пример в таблице 3 ниже, где основное предположение состоит в том, что организация не имеет достаточного запаса для покрытия неточностей прогноза. В этой таблице представлен базовый прогноз (без применения AI-приложения) и фактический спрос от клиентов ежемесячно для 10 групп товаров: PF1 до PF10. Также указана цена на группу товаров. Масштаб этих чисел представляет собой типичный продукт химической промышленности.

Мы видим, что для некоторых продуктов прогнозирование завышено (Прогноз > Фактические данные), а для других — занижено (Прогноз < Фактические данные). Для недооцененных продуктов мы предполагаем отсутствие запасов для покрытия этого недостатка и рассчитываем потерянные доходы, умножая цену на недостаток. Общая сумма потерянных доходов оценивается в ~58 млн долларов. С помощью AI-приложения, способного предсказывать будущий ежемесячный спрос с использованием заказов в реальном времени и обновлять прогнозы, а также производить необходимое количество товаров, мы можем сократить эти потерянные доходы. Даже с улучшением прогнозной ошибки на 20% (что не является необычным для таких приложений), потери дохода организации сокращаются на 11,6 млн долларов в месяц.
В заключение
Краткосрочное сенсорное прогнозирование с использованием заказов клиентов в реальном времени может быть шагом вперед по сравнению с традиционными методами прогнозирования, поскольку оно использует информацию в реальном времени для повышения точности прогнозов. Однако стоит отметить, что это может быть не применимо во всех случаях использования или бизнес-ситуациях. Оно работает лучше, когда есть некоторая регулярность в образце заказов и заказы размещаются заранее. Техника работает наилучшим образом, когда сочетается с рыночной информацией для понимания бизнес-идеи за наблюдениями. Этот подход не применим для прогнозирования более чем на 6-8 недель вперед, так как клиенты обычно не размещают заказы заранее на такой срок.
Метод, описанный в этом посте, также может быть использован для других целей. Например, мы можем использовать этот подход для оценки отклонения между ожидаемым спросом и фактическими заказами для каждой комбинации клиент/продукт. Это может помочь выявить клиентов для дальнейшего изучения, которые заказали слишком мало или слишком много продукции в процентном отношении к прогнозу продаж по сравнению с их историческим заказным образцом.
Наконец, мы бы хотели создать механизмы для принятия мер, как только обновленный прогноз будет доступен. Это может включать увеличение / уменьшение производства или последующее общение с клиентами, которые превысили прогнозное выделение или еще не спросили ни одного объема.
Спасибо за чтение. Надеюсь, вы нашли это полезным. Не стесняйтесь присылать мне свои комментарии по адресу rkumar5680@gmail.com. Давайте свяжемся в LinkedIn






