F1 Score Визуальное руководство – и почему оно не спасет вас от несбалансированных данных
F1 Score Визуальное руководство - не спасение от несбалансированных данных
Краткое изложение в конце
Наша задача – создать модель для классификации здоровых и больных людей. Нам предоставлены данные о них, мы создали несколько моделей классификации, и настало время выбрать лучшую.

Точность и Полнота
Общепринятый способ оценки производительности модели – измерить ее точность и полноту.
Точность – какая часть всех предсказанных положительных результатов является действительно положительными.
- Как бизнесу улучшить точность многоязычных классификаторов продуктов? В этой статье по искусственному интеллекту предлагается LAMM подход активного обучения, направленный на укрепление точности классификации в языках с ограниченными данными обучения.
- Microsoft представляет Python в Excel Связывая аналитические возможности с знакомым интерфейсом для расширения возможностей работы с данными
- Два интересных метода манипуляции данными в Pandas, которые вам нужно знать
Полнота – какая часть всех действительно положительных результатов в наших данных мы предсказали правильно.

Точность и полнота – отличные метрики, но это всего лишь два числа. Если вы хотите сравнить две разные модели, чтобы решить, какая лучше, было бы проще иметь одно число.
Арифметическое среднее
Один из способов объединить точность и полноту – это их среднее значение (арифметическое среднее).

Этот метод эффективно объединяет две метрики в одно значение. Однако есть одно замечание.
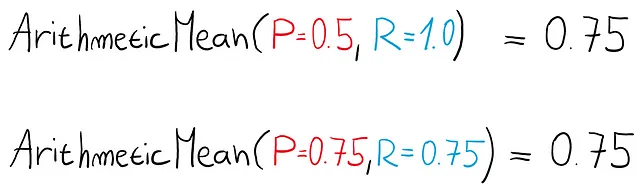
Здесь у нас одно и то же среднее значение. Но модели одинаково хороши?
Первая модель могла бы просто называть все в нашем наборе данных положительными без какой-либо логики, в то время как вторая модель кажется более полезной.
При поиске хорошей модели мы хотим избегать моделей с низкой точностью или полнотой. Они, вероятно, не являются полезными моделями, и нам бы хотелось уменьшить “оценку”, если одно из чисел значительно меньше другого.



