Интуиция для AUC и C-статистики Харрелла
Intuition for AUC and Harrell's C-statistic
Графический подход

Каждый, кто занимается машинным обучением или предиктивным моделированием, сталкивается с понятием тестирования производительности модели. Учебники обычно различаются только тем, что первым изучает читатель: регрессию с ее MSE (среднеквадратической ошибкой) или классификацию с множеством показателей производительности, таких как точность, чувствительность или точность, чтобы назвать некоторые. В то время как показатель может быть рассчитан как простая дробь правильных/неправильных предсказаний и поэтому очень интуитивен, ROC AUC может быть ошеломляющим на первый взгляд. Тем не менее, это также часто используемый параметр для оценки качества предиктора. Давайте разберем его механику, чтобы понять все детали.
Сначала разберитесь с AUC
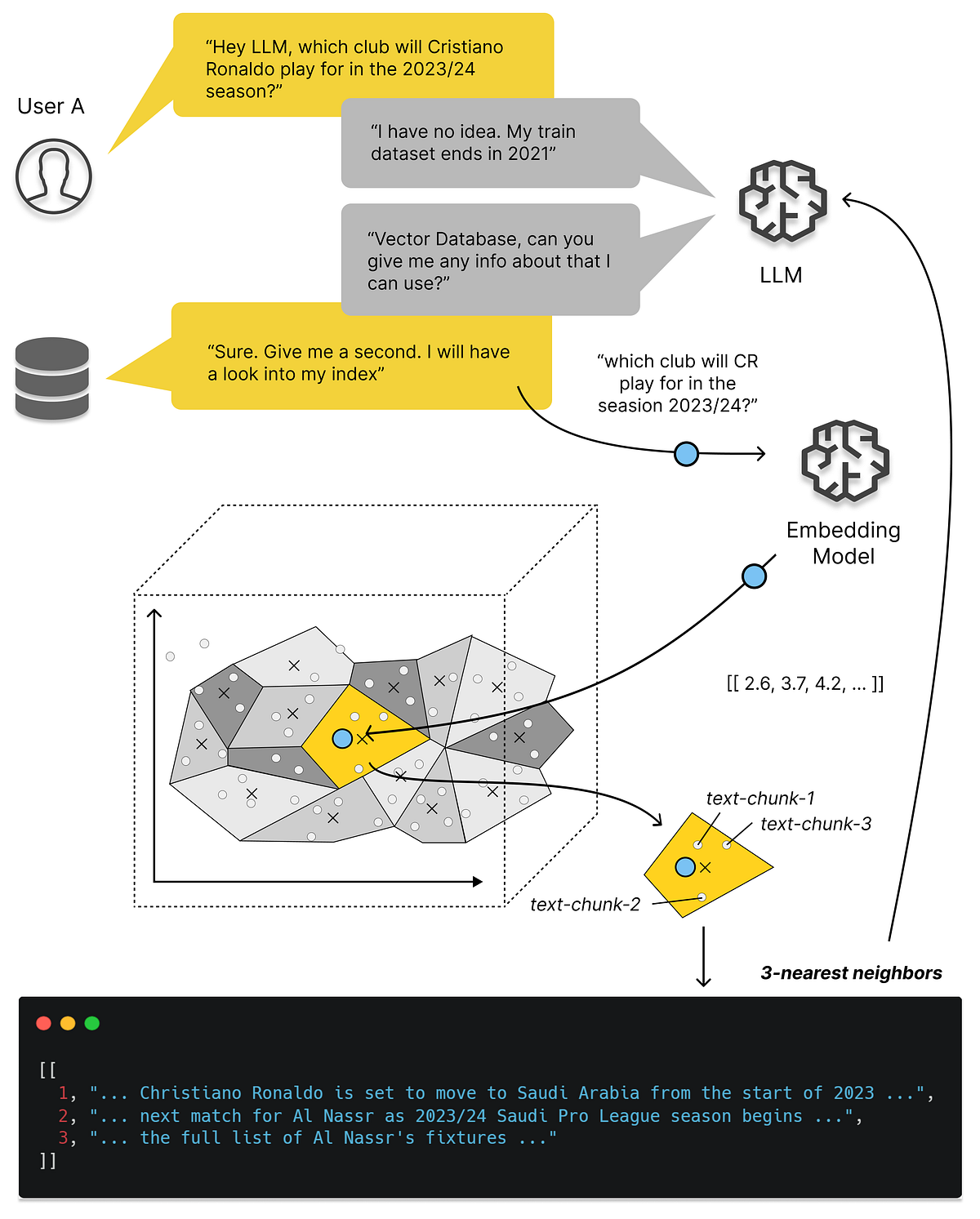
Допустим, мы построили бинарный классификатор, предсказывающий вероятность принадлежности образца к определенному классу. Наш тестовый набор данных с известными классами дал следующие результаты, которые можно суммировать в матрице неточностей и подробно описать в таблице, где образцы были отсортированы по предсказанной вероятности принадлежности к классу P (положительному):
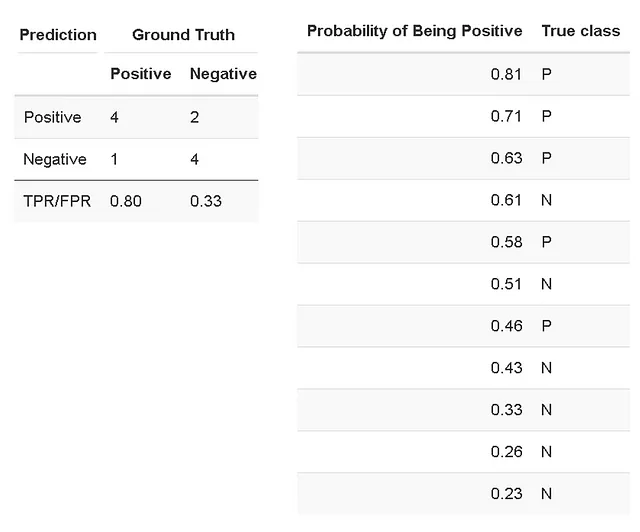
ROC AUC определяется как площадь под ROC (кривая приема-отказа) кривой. Кривая ROC – это график истинно положительной частоты (TPR) в зависимости от частоты ложно положительных (FPR) [Википедия]. TPR (также известный как чувствительность) – это отношение правильно идентифицированных положительных случаев ко всем положительным случаям. В нашем случае TPR рассчитывается как 4/5 (четыре из пяти случаев были классифицированы правильно как положительные). FPR рассчитывается как отношение между количеством отрицательных случаев, неправильно классифицированных как положительные (ложные положительные), и общим количеством фактических отрицательных случаев. В нашем случае FPR рассчитывается как 2/6 (два из шести отрицательных случаев были неправильно классифицированы как положительные, если мы установим порог “положительности” на вероятность 0.5).
Мы можем построить кривую ROC на основе значений TPR и FPR и рассчитать AUC (площадь под кривой):
- Искусственный интеллект (ИИ) с использованием техник глубокого обучения для улучшения ADAS
- Управление версиями данных для озер данных обработка изменений в крупномасштабном масштабе
- Адам Росс Нельсон о уверенной науке о данных
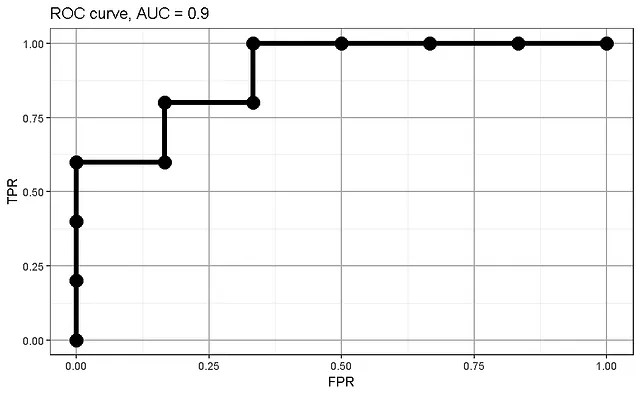
Откуда берутся индивидуальные значения TPR/FPR для кривой AUC? Для этого мы рассматриваем нашу таблицу вероятностей и рассчитываем TPR/FPR для каждого образца, устанавливая вероятность, при которой мы считаем образец положительным, такой, какой указан в таблице. Даже когда мы превышаем обычный уровень 0.5, при котором образцы обычно объявляются “отрицательными”, мы продолжаем считать их положительными. Давайте следовать этой процедуре в нашем примере:
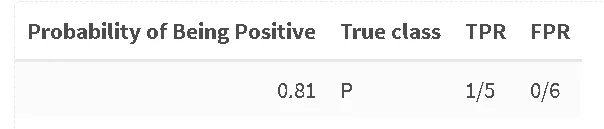
Один образец из пяти положительных был правильно классифицирован как положительный при пороге 0.81, ни один образец не был предсказан отрицательным. Мы продолжаем, пока не сталкиваемся с первым отрицательным примером:
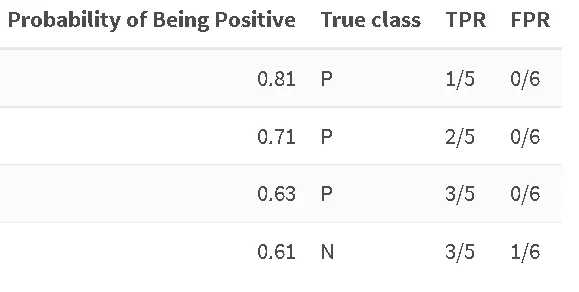
Здесь наш TPR останавливается на предыдущем значении (3 из 5 положительных образцов были предсказаны правильно), но FPR увеличивается, мы ошибочно отнесли один из шести отрицательных образцов к положительному классу. Мы продолжаем до самого конца:
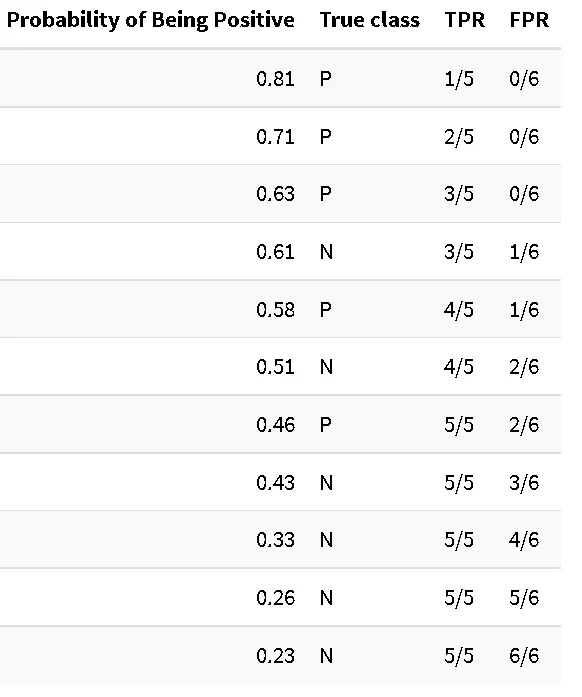
И вот: мы получаем полную таблицу, которая используется для создания ROC-кривой.
Почему индекс C Харрелла – это просто AUC
Но что насчет индекса C Харрелла (также известного как индекс согласованности или C-индекс)? Рассмотрим конкретную задачу – предсказание смерти при наличии определенного заболевания, скажем, рака. В конечном итоге все пациенты умрут, независимо от рака – простой бинарный классификатор не будет особо полезен. Модели выживаемости учитывают длительность до исхода (смерти). Чем раньше происходит событие, тем выше риск человека столкнуться с исходом. Если вы хотите оценить качество модели выживаемости, вы будете смотреть на C-индекс (также известный как конкордантность, или C Харрелла).
Для понимания расчета C-индекса нам необходимо ввести два новых понятия: допустимые и согласованные пары. Допустимые пары – это пары выборок (скажем, пациентов) с разными исходами во время наблюдения, то есть, во время проведения эксперимента, один пациент из такой пары испытал исход, в то время как другой был цензурирован (то есть еще не достиг исхода). Затем эти допустимые пары анализируются на предмет того, испытал ли событие лицо с более высоким баллом риска, в то время как цензурированное лицо не испытало его. Эти случаи называются согласованными парами.
Упрощая немного, C-индекс рассчитывается как отношение числа согласованных пар к числу допустимых пар (я опускаю случай совпадения рисков для простоты). Давайте пройдемся по нашему примеру, предположив, что мы использовали модель выживаемости, которая рассчитывала риск, а не вероятность. Следующая таблица содержит только допустимые пары. Столбец “Согласованность” установлен на 1, если пациент с более высоким баллом риска испытал событие (был одной из наших “положительных” групп). Идентификатор – просто номер строки из предыдущей таблицы. Особое внимание уделяется сравнению индивидуума 4 с 5 или 7.
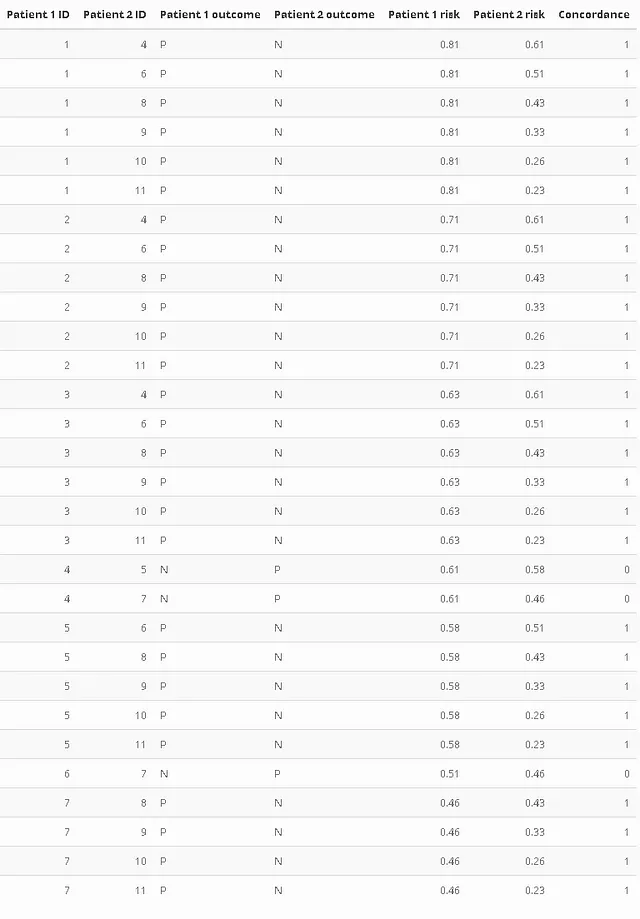
Таким образом, у нас остается 27 согласованных пар из 30 допустимых. Соотношение (упрощенный C Харрелла) равно C = 0.9, что подозрительно напоминает ранее рассчитанный AUC.
Мы можем создать матрицу согласованности, которая визуализирует, как вычисляется статистика C, как предложено Carrington et al. График показывает значения риска реальных положительных случаев по сравнению с значениями риска реальных отрицательных случаев и отображает долю правильно ранжированных пар (зеленые) относительно всех пар (зеленые + красные), если мы интерпретируем каждый квадрат сетки как представление выборки:
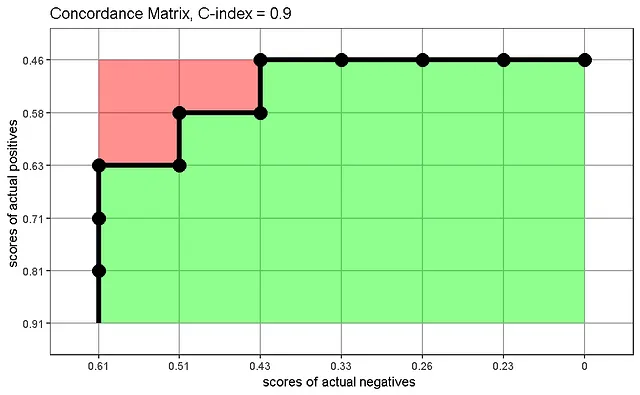
Матрица согласованности показывает правильно ранжированные пары в согласованность внизу справа, неправильно ранжированные пары вверху слева и границу между ними, которая точно соответствует ранее виденной ROC-кривой.
Разбирая процесс построения кривой ROC и матрицы согласованности, мы узнаем сходство: в обоих случаях мы ранжировали наши выборки в соответствии с их вероятностью/баллом риска и проверяли, соответствовало ли ранжирование истине. Чем выше мы устанавливаем порог вероятности для классификации, тем больше ложно-положительных результатов мы получаем. Чем ниже риск реальных положительных случаев, тем больше вероятно, что реальный отрицательный случай будет ошибочно классифицирован как положительный. Построение соответствующего графика наших ранжированных данных привело к кривой с той же формой и площадью, которую мы называем AUC или C Харрелла, в зависимости от контекста.
Надеюсь, этот пример помог развить интуицию как для AUC, так и для C Харрелла.
Благодарность
Идея сравнить эти два параметра возникла в результате плодотворного обсуждения на встрече Advanced Machine Learning Study Group, благодарности Торстену!
Ссылка: Carrington, A.M., Fieguth, P.W., Qazi, H. и др. Новый согласованный частичный показатель AUC и частичная статистика C для несбалансированных данных при оценке алгоритмов машинного обучения. BMC Med Inform Decis Mak 20, 4 (2020). https://doi.org/10.1186/s12911-019-1014-6