Microsoft Research представляет не один, не два, а целых четыре новых компилятора искусственного интеллекта
Microsoft Research представляет 4 новых компилятора искусственного интеллекта
Параллелизм, вычисление, память, аппаратное ускорение и управляющий поток – некоторые из возможностей, рассматриваемых новыми компиляторами.

Недавно я начал образовательную рассылку, посвященную искусственному интеллекту, которая уже имеет более 160 000 подписчиков. TheSequence – это рассылка, ориентированная на машинное обучение, которая занимает 5 минут на прочтение. Цель состоит в том, чтобы держать вас в курсе проектов машинного обучения, научных статей и концепций. Пожалуйста, попробуйте подписаться ниже:
TheSequence | Jesus Rodriguez | Substack
Лучший источник для оставания в курсе разработок в сфере машинного обучения, искусственного интеллекта и данных…
thesequence.substack.com
В эпоху генеративного искусственного интеллекта компиляторы переживают ренессанс. В контексте искусственного интеллекта компилятор отвечает за преобразование архитектуры нейронной сети в исполняемый код для конкретной аппаратной платформы. В этих двух областях – модельных и аппаратных архитектурах – происходит взрыв инноваций, которые регулярно делают устаревшими компиляторы для искусственного интеллекта.
В области компиляции искусственного интеллекта существует множество вызовов, от аппаратного ускорения до вычислительной и памяти. Исследователи из Microsoft Research стоят во главе исследований компиляторов для искусственного интеллекта и недавно представили четыре передовых компилятора для искусственного интеллекта, каждый из которых предназначен для решения определенных проблем в области глубоких нейронных сетей (DNN). В список входят следующие компиляторы:
- Это исследование искусственного интеллекта AI предлагает SAM-Med2D самые всеобъемлющие исследования по применению SAM к медицинским 2D изображениям
- Это исследование ИИ раскрывает ComCLIP метод без обучения для композиционного выравнивания изображений и текста
- Исследователи UCSC и TU Munich предлагают RECAST новую модель на основе глубокого обучения для прогнозирования последующих толчков.
· Rammer: для параллелизма
· Roller: для вычислений
· Welder: для памяти
· Grinder: для управляющего потока и аппаратного ускорения
Давайте более подробно рассмотрим каждый из них.
Rammer: революционное использование параллельного аппаратного обеспечения
Глубокие нейронные сети (DNN) стали неотъемлемой частью различных задач искусственного интеллекта, от классификации изображений до обработки естественного языка. Для использования их мощности используются различные вычислительные устройства, включая ЦП, ГП и специализированные ускорители DNN. Одним из критических факторов, влияющих на эффективность вычислений DNN, является планирование, процесс, который определяет порядок выполнения вычислительных задач на аппаратном обеспечении. Традиционные компиляторы искусственного интеллекта часто представляют вычисления DNN в виде графа потока данных с узлами, символизирующими операторы DNN, запускаемые на ускорителях независимо друг от друга. Однако такой подход вводит значительные накладные расходы на планирование и неэффективно использует аппаратные ресурсы.
Входит Rammer, компилятор DNN, который воспринимает пространство планирования как двумерную плоскость. Здесь вычислительные задачи подобны кирпичам различной формы и размера. Миссия Rammer заключается в том, чтобы плотно расположить эти кирпичи на двумерной плоскости, подобно строительству непрерывной стены. Оптимизация использования аппаратного обеспечения и скорости выполнения предполагает отсутствие зазоров. Rammer действует как компактор в этой пространственной области, эффективно размещая кирпичи программы DNN на различных вычислительных блоках ускорителя, тем самым уменьшая накладные расходы на планирование во время выполнения. Кроме того, Rammer вводит новые аппаратно-независимые абстракции для вычислительных задач и аппаратных ускорителей, расширяя пространство планирования и позволяя более эффективные планы.
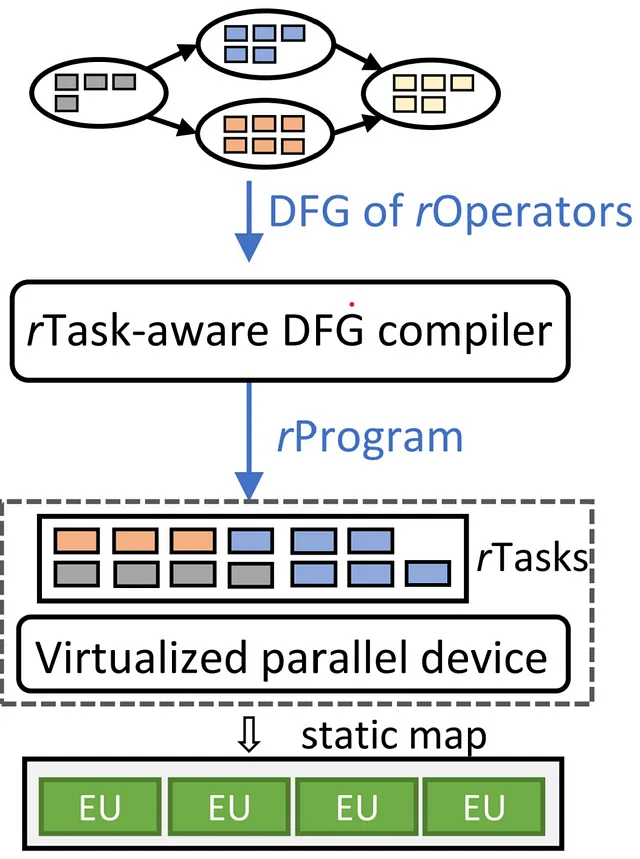
Roller: улучшение вычислительной эффективности
Ускорители с параллельными вычислительными блоками и сложными иерархиями памяти требуют системного подхода к передаче данных. Данные должны проходить через уровни памяти, разделенные на более мелкие кирпичи на каждом шаге, прежде чем достигнуть процессора верхнего уровня для вычислений. Проблема заключается в разбиении и заполнении памяти большими кирпичами для оптимизации использования и эффективности памяти. Текущий подход использует машинное обучение для стратегий разбиения кирпичей, требующих множества этапов поиска, оцениваемых на ускорителе. Этот долгий процесс может занимать дни или недели для компиляции полной модели искусственного интеллекта.
Roller ускоряет компиляцию, сохраняя оптимальную вычислительную эффективность. В основе Roller лежит уникальная концепция, подобная работе дорожного катка. Эта инновационная система плавно размещает многомерные тензорные данные на двумерной структуре памяти, подобно укладке пола. Она делает это с точностью, определяя оптимальные размеры блоков в зависимости от конкретных характеристик памяти. В то же время Roller интеллектуально инкапсулирует форму тензора, чтобы гармонизировать с аппаратными особенностями базового ускорителя. Это стратегическое выравнивание значительно упрощает процесс компиляции, ограничивая диапазон вариантов формы и, в конечном счете, приводя к высокоэффективным результатам.
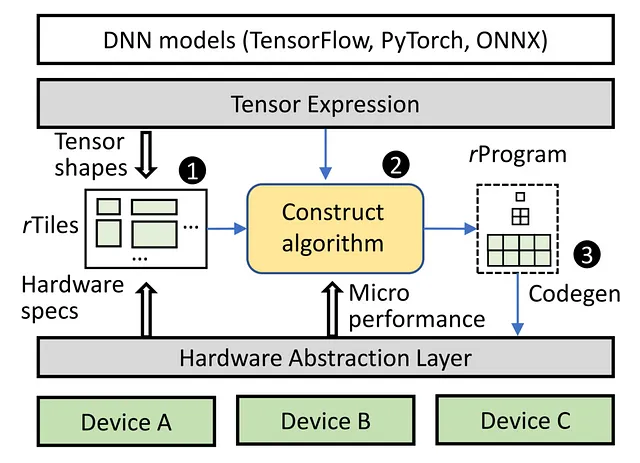
Welder: Оптимизация доступа к памяти
Поскольку модели DNN все больше требуют высококачественных данных и быстрых вычислительных ядер в современных аппаратных ускорителях, возникают узкие места в пропускной способности памяти. Для преодоления этой проблемы Welder, компилятор глубокого обучения, всесторонне оптимизирует эффективность доступа к памяти в модели DNN от начала до конца. Процесс включает несколько этапов, на которых входные данные разделяются на блоки, проходящие через разные операторы и уровни памяти. Welder превращает этот процесс в эффективную конвейерную линию, сваривая вместе различные операторы и блоки данных, уменьшая трафик доступа к памяти на нижних уровнях памяти.
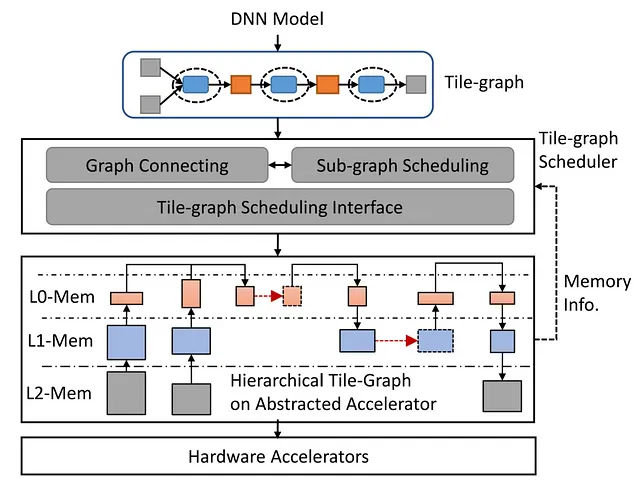
Grinder: Освоение выполнения управляющего потока
В вычислениях ИИ сложная управляющая логика иногда сопровождает перемещение блоков данных. Текущие компиляторы ИИ в основном сосредотачиваются на эффективности выполнения потока данных, не обращая должного внимания на эффективную поддержку управляющего потока. Grinder заполняет эту пробел, путем бесшовного интегрирования управляющего потока в поток данных, обеспечивая эффективное выполнение на ускорителях. Он объединяет представление моделей ИИ через новую абстракцию uTask и использует эвристические стратегии для оптимизации выполнения управляющего потока на различных уровнях аппаратной параллелизации. Grinder эффективно перемещает управляющий поток в ядра устройства, таким образом оптимизируя производительность на границах управляющего потока.
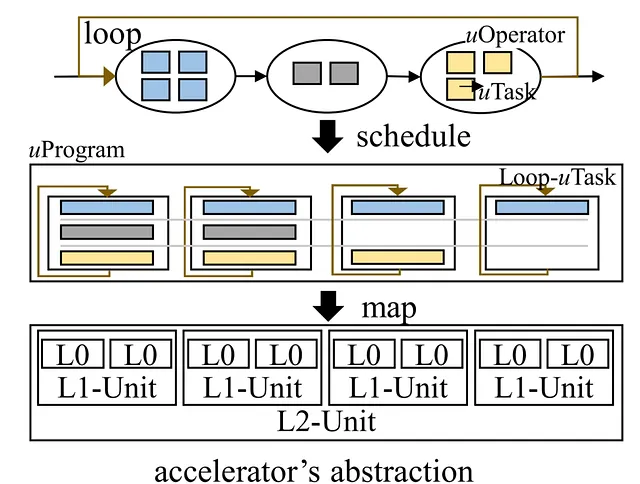
В заключение, квартет компиляторов ИИ от Microsoft Research – Rammer, Roller, Welder и Grinder – открывает путь к оптимизации рабочей нагрузки DNN, эффективности доступа к памяти и выполнению управляющего потока на аппаратных ускорителях, что является значительным прорывом в технологии компиляторов ИИ.