Дикий Дикий RAG… (Часть 1)
Wild Wild RAG... (Part 1)
Давайте начнем с понимания, что такое приложение RAG, термин, который привлек значительное внимание в последние месяцы.
RAG (Retrieval-Augmented Generation) – это фреймворк искусственного интеллекта, который улучшает качество ответов, созданных языковой моделью, путем интеграции внешних источников знаний. Он сокращает разрыв между языковыми моделями и реальными информационными источниками, что приводит к более контекстно осведомленной и надежной генерации текста. Для наглядности взгляните на изображение ниже, которое приводит убедительный пример.
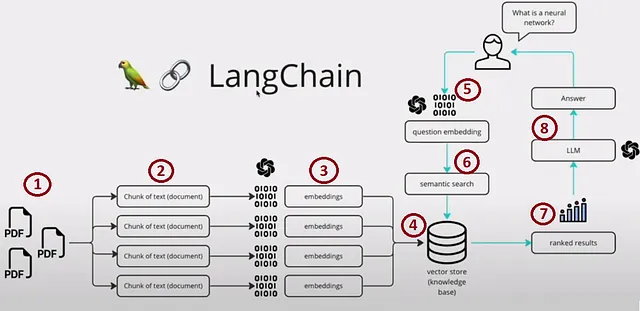
Мы можем разделить процесс на четыре основные секции:
- Шаги 1, 2, 3 и 4 – Индексирование
- Шаг 5 – Формулировка запроса
- Шаги 6 и 7 – Поиск и извлечение
- Шаг 8 – Генерация
Создание прототипа для приложения RAG простое, но оптимизация его для высокой производительности, надежности и масштабируемости при работе с обширной базой знаний представляет существенные вызовы.
В этом блоге мы рассмотрим отличительные особенности, которые отличают приложения RAG от обычных приложений на языковых моделях (LLM), сфокусировавшись на значимости выбора векторных представлений и хранилища векторов в этом контексте. В основном, это касается секций Индексирование и Поиск и извлечение.
- Руководство по сбору реальных данных для машинного обучения
- Сила контекста в истории, основанной на данных
- Environmental Data Science An Introduction’ ‘Наука о данных в сфере окружающей среды Введение
Поехали.

Для создания “контекста”, связанного с вашим запросом, сначала мы должны сгенерировать векторные представления из сегментированных фрагментов данных. Эти векторные представления хранятся в виде векторного индекса, служащего основой для последующих поисков приближенных ближайших соседей (ANN) на основе запросов пользователя. Хотя концепция кажется простой, подробное рассмотрение сложностей перехода этого процесса в рабочую среду позволяет выявить ряд интересных вызовов.
Стоимость индексирования, поиска и извлечения векторов
Теперь давайте рассмотрим одно из центральных соображений – стоимость индексирования. Важно понимать, что при создании приложения, готового для работы в рабочей среде, нельзя полагаться только на бесплатные варианты в памяти.
Давайте рассмотрим консервативную оценку для создания векторных представлений из внутренней базы знаний, состоящей из 3,5 миллиона страниц или миллиона PDF-файлов средней длиной 3,5 страницы. Для простоты давайте предположим, что каждая страница состоит только из текстового содержимого без изображений. Таким образом, каждая страница примерно составляет 1000 токенов. Если мы разобьем это на фрагменты по 1000 токенов каждый, то получим 3,5 миллиона фрагментов, которые впоследствии преобразуются в 3,5 миллиона векторных представлений.
Для расчета стоимости рассмотрим два варианта в этой области – Weaviate и Pinecone. Мы оставим все простым и оценим ежемесячные расходы по трем основным разделам:
- Одноразовая стоимость преобразования векторных представлений: Для обработки 3,5 миллиона векторных представлений примерная стоимость составляет 350 долларов по ставке 0,0001 доллара за преобразование.
- Оптимизированная для производительности база данных векторов Pinecone (Стандартная): Для одной реплики этот вариант будет стоить примерно 650 долларов. Это включает в себя как стоимость индексирования, так и извлечения. Важно отметить, что расходы линейно масштабируются с ростом ваших требований. Weaviate, другой вариант, вероятно, будет иметь аналогичную структуру ценообразования.
- Стоимость преобразования запроса векторных представлений: Предположим, что 1000 пользователей делают в среднем 25 запросов в день, и каждый запрос и подсказка составляют в сумме 100 токенов, стоимость для этого раздела составляет около 10 долларов.
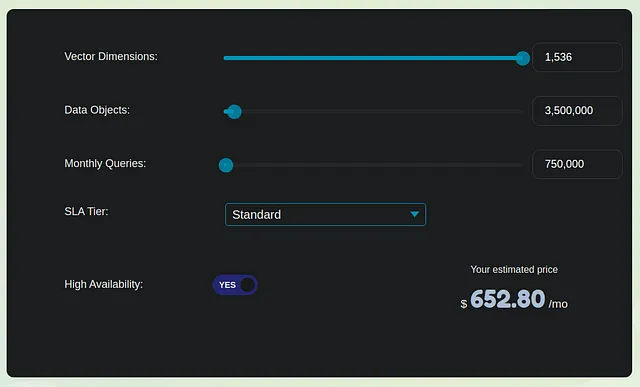
Общая ежемесячная стоимость индексации на умеренном уровне составляет примерно 1000 долларов. Обратите внимание, что эта цифра не включает расходы, связанные с генерацией ответов OpenAI LLM и хостингом приложений, которые могут быть примерно в 5-7 раз выше упомянутой стоимости или даже больше. Таким образом, стоимость хранения векторов составляет значительную часть, примерно 15-20% от общих расходов.
Для снижения затрат вы можете рассмотреть возможность размещения лучших моделей вложений, что также позволит сократить расходы на хранение векторов, выбрав размер вложения меньше 1536.
Но вам все равно придется платить за хранение векторов.

В случаях, когда функциональность, такая как поиск похожих метрик и индекс, остается неизменной, какие другие факторы следует учитывать при выборе хранилища векторов из более чем 100 вариантов?
Балансировка задержки, масштаба и воспоминания
Исходя из масштаба и стоимости, рассмотрим архитектуру клиент-сервер для наших хранилищ векторов. Вы можете выбрать размещение в облаке или на собственном оборудовании в зависимости от таких факторов, как объем данных, конфиденциальность и деньги.
Когда речь идет о хранилищах векторов, следует учитывать два основных типа задержки: задержка индексирования и задержка извлечения. Во многих случаях задержка извлечения имеет приоритет перед задержкой индексирования. Это предпочтение обусловлено тем, что операции индексирования обычно являются спорадическими или одноразовыми задачами, в то время как извлечение фрагментов, похожих на запросы пользователей, происходит намного чаще, часто в режиме реального времени и в масштабе через пользовательский интерфейс. Воспоминание, с другой стороны, определяет долю найденных ближайших соседей, усредненную по всем запросам. Большинство поставщиков в этой области используют гибридную методологию поиска векторов, которая сочетает ключевые слова и техники поиска векторов разными способами. Следует отметить, что разные поставщики баз данных делают различные выборы и компромиссы, когда дело доходит до оптимизации либо для воспоминания, либо для задержки.
Рассмотрим бенчмарки по воспоминанию против запросов/сек на стандартном наборе данных для косинусной метрики:
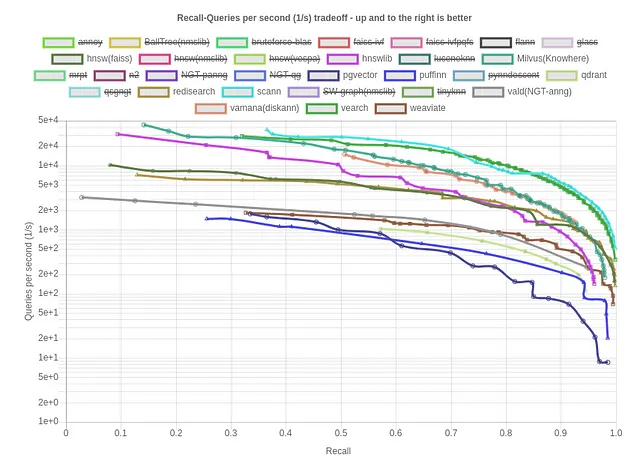
Scann, Vamana (DiskANN) и HNSW выделяются как некоторые из лучших вариантов для индексации. Теперь рассмотрим воспоминание против размера индекса (kB)/запросы в секунду для тех же, что является ценным показателем для оценки эффективности и потребления ресурсов векторной базы данных. Меньшее значение указывает на большую память эффективность, оптимизацию производительности и масштабируемость векторной базы данных.

В этом контексте Qdrant, Weviate и Redisearch выделяются как некоторые из лучших вариантов для эффективности памяти.
Однако вы можете обратиться к следующему изображению, чтобы узнать о используемом векторном индексе каждой базы данных.

Очевидно, что значительное количество поставщиков баз данных выбрали разработку собственных реализаций на основе графа HNSW. Эти пользовательские реализации часто включают оптимизации, направленные на снижение потребления памяти, например, совмещение квантизации продукта (PQ) с HNSW. Однако стоит отметить, что только некоторые из них приняли DiskANN, который, кажется, обеспечивает сопоставимую производительность с HNSW и при этом обладает уникальным преимуществом масштабирования индексов, хранящихся полностью на диске.
В нашей оценке мы не полагаемся на бенчмарки, предоставленные поставщиками, поскольку они могут внести предвзятость в процесс оценки.
Жесткость и отсутствие постоянного обучения
В будущем сценарии, когда вам может потребоваться обновить вашу Большую языковую модель (LLM) или модель векторных представлений путем донастройки, подписаться на улучшенную модель, расширить размерность векторных представлений или приспособиться к изменениям в ваших данных, необходимость повторного индексирования и связанные с этим затраты могут быть нечто вроде кошмара. Эта жесткость может значительно затруднить гибкость и эффективность вашей системы развития.
Помимо этих проблем давайте рассмотрим некоторые врожденные сложности в процессе Векторного поиска и извлечения.
Обработка ошибок индекса и Проклятие размерности
Когда возникает ситуация, когда запрос на текст не может извлечь соответствующий контекст и вместо этого предоставляет несвязанную или бессмысленную информацию, основные причины этой неудачи обычно можно объяснить одним из трех факторов:
a) Отсутствие соответствующего текста: В некоторых случаях соответствующий текстовый фрагмент просто не существует в базе данных. Этот результат является приемлемым, поскольку он указывает на то, что запрос может быть не связан с содержимым набора данных.
b) Низкое качество векторных представлений: Еще одна возможная причина – низкое качество самих векторных представлений. В таких случаях векторные представления не могут эффективно сопоставить два соответствующих текста при использовании косинусного сходства.
c) Распределение векторных представлений: В альтернативном случае сами векторные представления могут быть хорошего качества, но из-за распределения этих векторных представлений в индексе алгоритм ANN с трудом извлекает правильное векторное представление.
В то время как в целом можно принять отказаться от причины (a) как несвязанности запроса с набором данных, отличить причины (b) и (c) может быть сложным и затратным процессом отладки. Это поведение становится все более явным в случае алгоритмов ANN, работающих с большим количеством высокомерных векторов – феномена, который часто называют “Проклятие размерности”.
Переоценка методов векторного поиска и извлечения
Если основная цель экосистемы векторного поиска – получить “соответствующий текст” в ответ на запрос, почему поддерживать два отдельных процесса? Вместо этого, почему бы не создать единую обучаемую систему, которая при представлении текста вопроса предоставляет “наиболее соответствующий” текст в качестве прямого вывода?
Фундаментальное предположение, лежащее в основе всей экосистемы, заключается в использовании мер сходства между векторными представлениями для извлечения соответствующего текста. Однако важно понимать, что существуют потенциально более эффективные альтернативы этому подходу. Большие языковые модели (LLM) не настраиваются непосредственно для сопоставления по сходству, и вполне вероятно, что другие методы извлечения могут давать более эффективные результаты.
Источник: Twitter
Революция глубокого обучения дала ценный урок: система извлечения, оптимизированная совместно, обычно превосходит разорванный процесс, в котором векторные представления и операции приближенного поиска ближайших соседей (ANN) независимы друг от друга. В оптимизированной системе извлечения процесс векторных представлений и компонент ANN тесно связаны и знакомы с особенностями друг друга, что приводит к более последовательному и эффективному извлечению информации. Это подчеркивает важность голистического и интегрированного подхода при проектировании систем для извлечения информации и сопоставления контекста.
Заключение
В области приложений Production-Ready Retrieval-Augmented Generation (RAG) и векторного поиска мы обнаружили вызовы и возможности в объединении языковых моделей с реальными знаниями. От учета затрат на индексацию до тонкого баланса между задержкой, масштабируемостью и полнотой, очевидно, что оптимизация этих систем для производства требует продуманного планирования. Нежесткость моделей подчеркивает важность адаптивности в условиях изменения. Переоценивая векторный поиск и извлечение для производственных сред, мы видим, что объединенная, совместно оптимизированная система предлагает надежду. В этом постоянно меняющемся мире мы стоим на пороге создания более осведомленных контекстом ИИ-систем, которые переопределяют границы генерации текста и извлечения информации.
Путешествие продолжается…
Спасибо за чтение. Свяжитесь со мной в LinkedIn.






