Семантический уровень основа AI-приводимых данных
Семантический уровень основа данных, управляемых искусственным интеллектом
Спонсируемый контент
Это руководство “Пять неотъемлемых элементов семантического слоя” поможет вам понять всю широту современного семантического слоя.
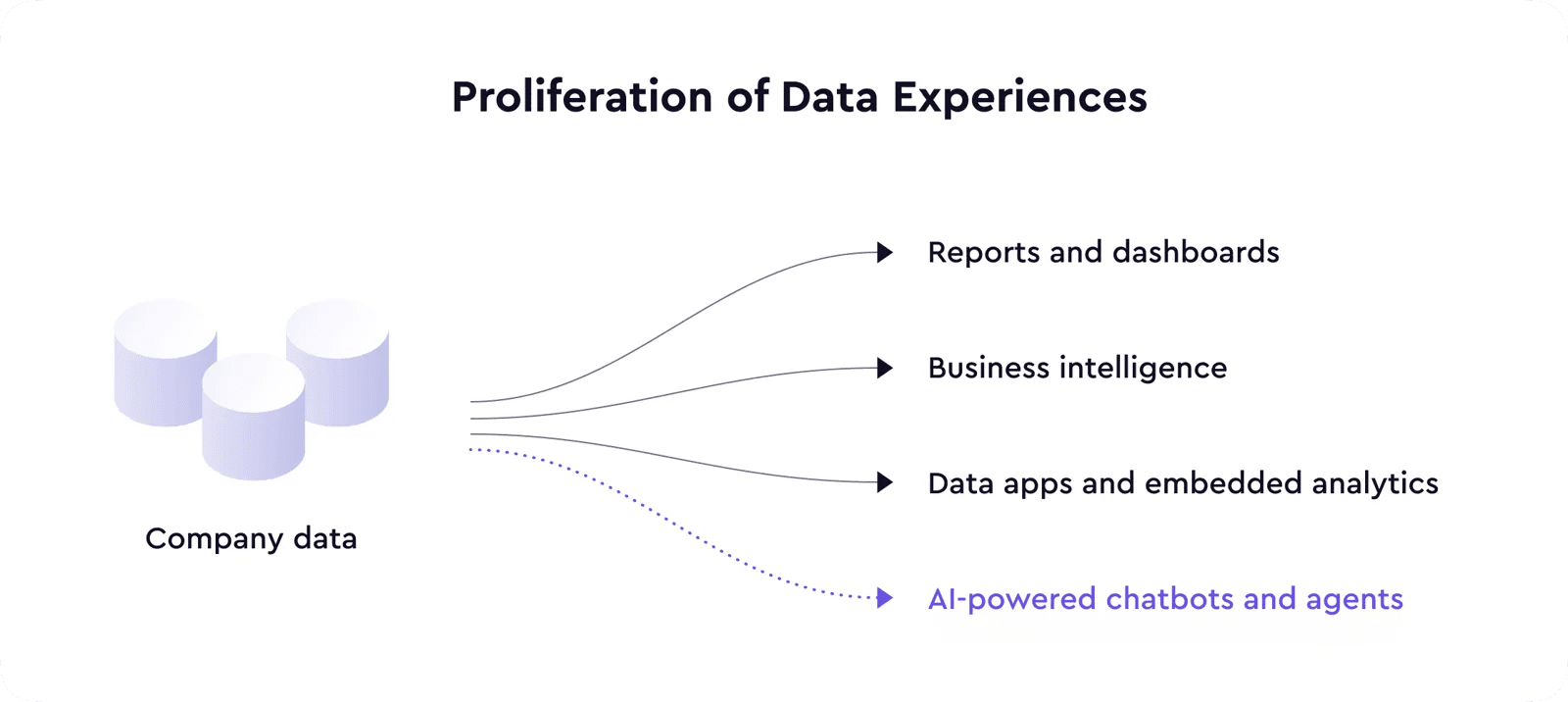
Опыт работы с данными на основе ИИ
Эволюция технологий фронтэнда позволила внедрить аналитические решения прямо во множество программных продуктов, что еще более ускорило распространение продуктов и опыта работы с данными.
- Когда решается сложная тема, первый шаг самый сложный.
- Топологическая обобщенность с проводящими трансформаторами диффузии
- Trending AI GitHub Repos Неделя с 16 по 23 октября 2023 года
И теперь, с появлением больших языковых моделей, мы переживаем еще одну переломную технологическую стадию, которая позволит создать множество новых функций и даже совершить революцию в классе продуктов для различных сценариев использования, включая данные.
Благодаря искусственному интеллекту, LLM уводит слой потребления данных на новый уровень, предлагая опыт работы с данными на основе ИИ, начиная от чат-ботов, отвечающих на вопросы о вашей бизнес-информации, до агентов ИИ, выполняющих действия на основе сигналов и аномалий в данных.
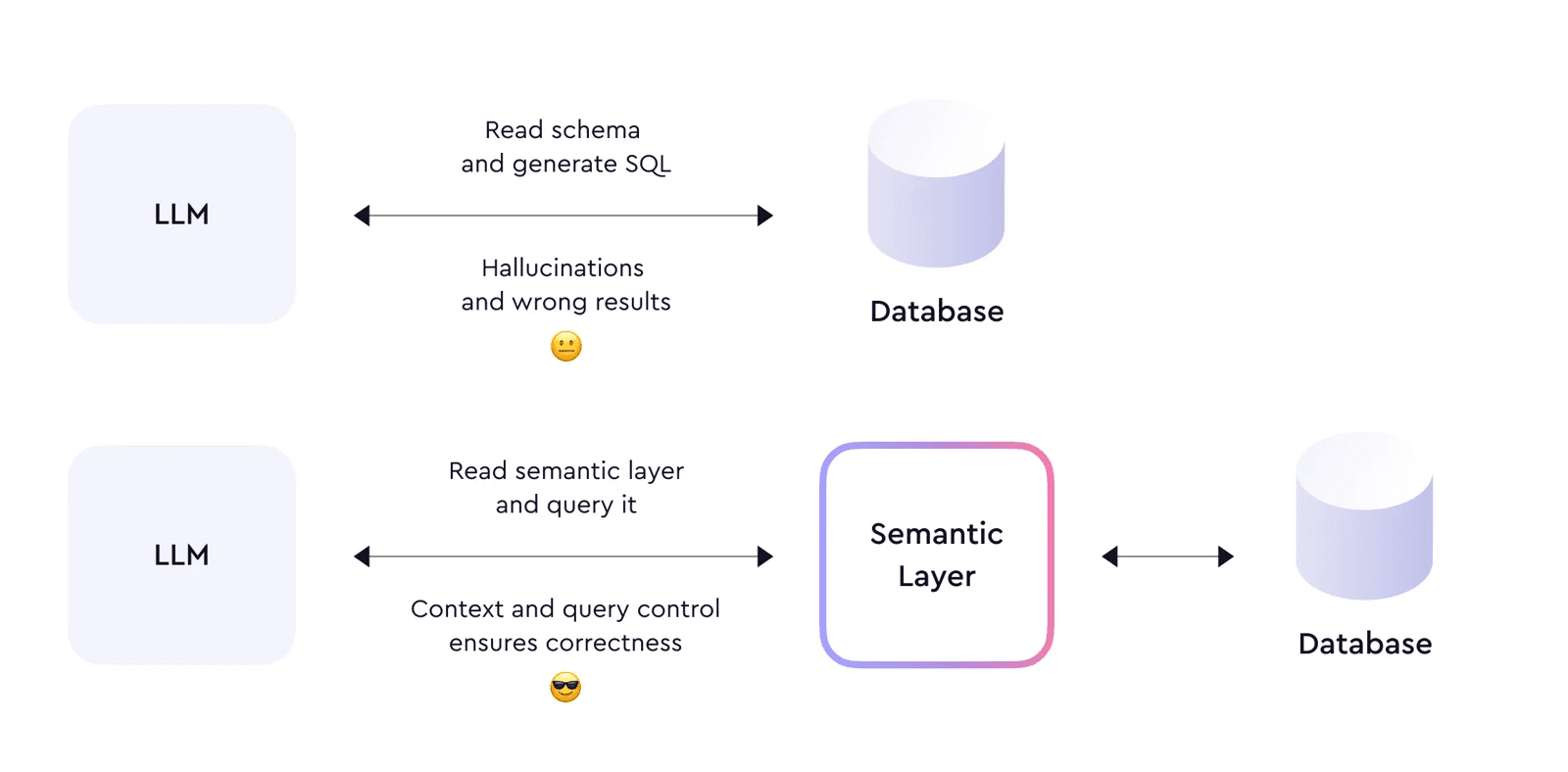
Семантический слой придает контекст LLM
LLM действительно вызывает потрясение, но, как и любая другая технология, она имеет свои ограничения. LLM “фантазирует”: проблема “мусор внутри, мусор на выходе” никогда не была настолько актуальной. Представьте себе такую ситуацию: когда для людей трудно понять несогласованные и неорганизованные данные, LLM только усугубляет эту путаницу, выдавая неверные ответы.
Нельзя подать в LLM схему базы данных и ожидать, что он сгенерирует правильный SQL-код. Чтобы функционировать корректно и выполнять надежные действия, ему необходимо иметь достаточный контекст и семантику обрабатываемых данных: метрики, измерения, сущности и связи. Другими словами, LLM нуждается в семантическом слое.
Семантический слой организует данные в осмысленные бизнес-определения, а затем позволяет делать запросы по этим определениям, а не напрямую к базе данных.
Важным аспектом в процессе запросов является то, что он обязывает LLM осуществлять запросы через семантический слой, обеспечивая правильность запросов и возвращаемых данных. Таким образом, семантический слой устраняет проблему “фантазий” LLM.
Кроме того, комбинирование LLM и семантических слоев может создать новое поколение опыта работы с данными на основе ИИ. В компании Cube мы уже видели, как многие организации создают настраиваемые внутрикорпоративные приложения на базе LLM, а стартапы, как, например, Delphi, разрабатывают готовые решения на основе семантического слоя Cube (демо-версия здесь).
Мы видим, что Cube становится неотъемлемой частью современного технологического стека ИИ, так как он действует поверх хранилищ данных, обеспечивает контекст для агентов ИИ и служит интерфейсом для выполнения запросов к данным.
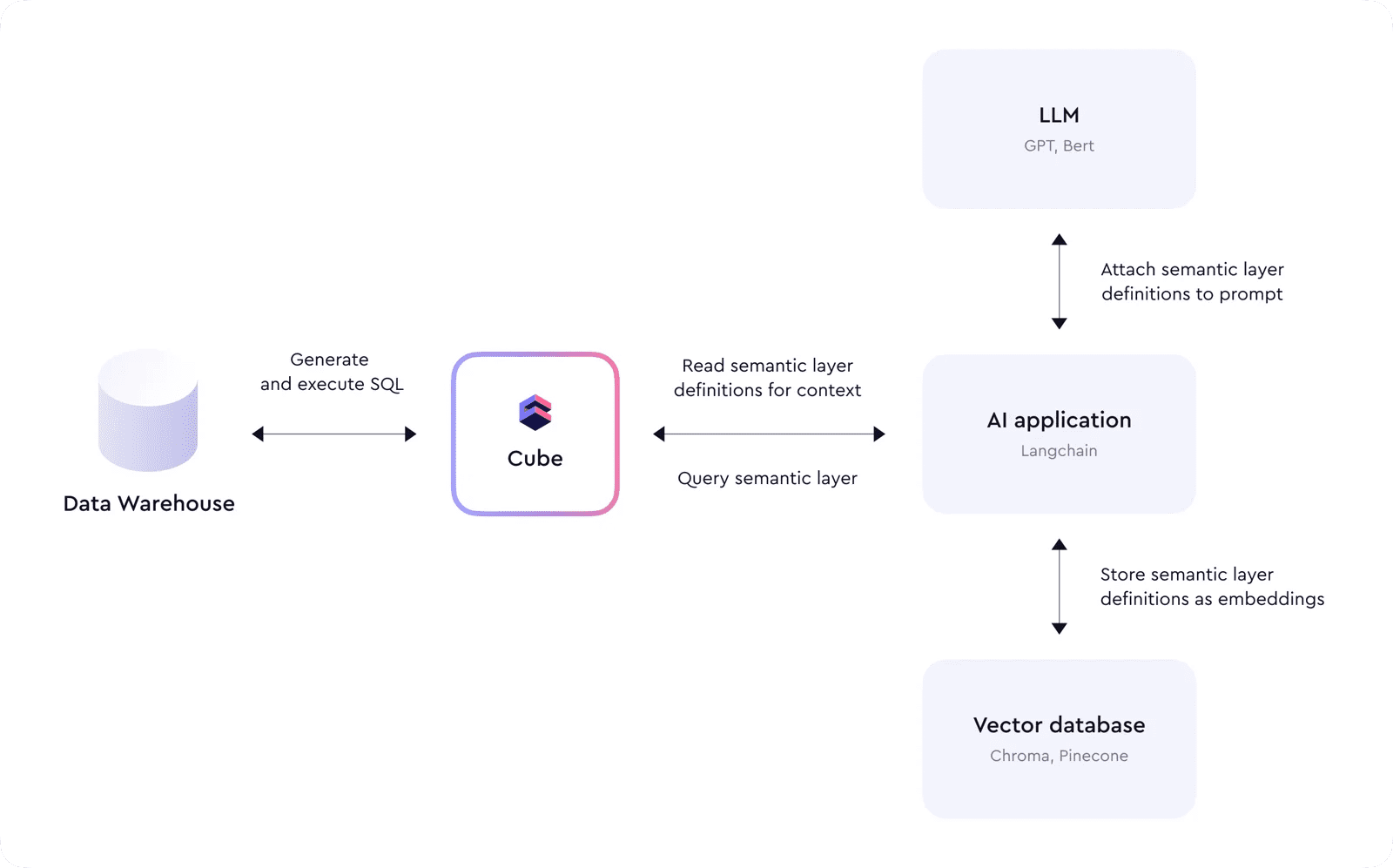
Модель данных Cube предоставляет структуру и определения, используемые в качестве контекста для понимания данных и генерации правильных запросов LLM. LLM больше не нужно разбираться в сложных операциях объединения и расчетах метрик, потому что Cube абстрагирует их и предоставляет простой интерфейс, работающий на уровне деловых терминов, а не на основе имен таблиц и столбцов SQL. Это упрощение помогает снизить вероятность ошибок LLM и избежать “фантазий”.
Например, приложение на основе ИИ сначала считывает метаданные из API Cube, загружает все определения семантического слоя и сохраняет их в векторной базе данных. Затем, когда пользователь отправляет запрос, эти векторы используются в промпте для LLM, чтобы предоставить дополнительный контекст. LLM отвечает сгенерированным запросом к Cube, и приложение выполняет его. Этот процесс может быть продолжен и повторен несколько раз для ответов на сложные вопросы или создания сводных отчетов.
Производительность
Что касается времени отклика – при выполнении сложных запросов и задач система ИИ может проделывать несколько запросов к семантическому слою с применением разных фильтров.
Чтобы обеспечить приемлемую производительность, такие запросы должны быть кэшированы и не всегда отправляться в основные хранилища данных. Cube предоставляет реляционный кэш-движок для построения предварительных агрегатов на основе необработанных данных и реализует механизм агрегатного распознавания для направления запросов к этим агрегатам при возможности.
Безопасность
И, наконец, безопасность и контроль доступа никогда не должны быть побочными задачами при создании приложений на основе ИИ. Как уже упоминалось выше, генерация необработанного SQL-кода и его выполнение в хранилище данных могут привести к неправильным результатам.
Однако ИИ представляет дополнительную угрозу: поскольку его невозможно контролировать и он может генерировать произвольный SQL, прямой доступ между ИИ и хранилищем данных также может быть значительной уязвимостью безопасности. Вместо этого, генерация SQL через семантический уровень может обеспечить наличие детализированных политик контроля доступа.
И многое другое…
У нас есть множество захватывающих интеграций с экосистемой искусственного интеллекта и мы с нетерпением ждем возможности поделиться ими с вами. Тем временем, если вы работаете над приложением на базе искусственного интеллекта, рекомендуем протестировать Cube Cloud бесплатно.
Скачайте руководство “Пять важных особенностей каждого семантического уровня“, чтобы узнать больше.





