Представляем Würstchen быстрое распространение для генерации изображений
Würstchen - быстрое распространение для генерации изображений'

Что такое Würstchen?
Würstchen – это модель диффузии, компонент условного текста которой работает в сильно сжатом латентном пространстве изображений. Почему это важно? Сжатие данных может снизить вычислительные затраты как на обучение, так и на вывод на несколько порядков. Обучение на изображениях размером 1024×1024 гораздо дороже, чем обучение на 32×32. Обычно другие работы используют относительно небольшое сжатие в диапазоне 4x – 8x пространственного сжатия. Würstchen идет на крайности. Благодаря своему новаторскому дизайну, он достигает 42-кратного пространственного сжатия! Это никогда раньше не наблюдалось, потому что общепринятые методы не могут точно восстановить детализированные изображения после 16-кратного пространственного сжатия. Würstchen использует двухэтапное сжатие, которое мы называем этапом A и этапом B. Этап A – это VQGAN, а этап B – это диффузионный автоэнкодер (подробнее можно найти в статье). Вместе этапы A и B называют Декодером, потому что они декодируют сжатые изображения обратно в пиксельное пространство. Третья модель, этап C, обучается в этом сильно сжатом латентном пространстве. Это обучение требует долей вычислительных ресурсов, используемых для текущих моделей с лучшей производительностью, позволяя при этом более дешевый и быстрый вывод. Мы называем этап C Приором.

Зачем еще одна модель текст-в-изображение?
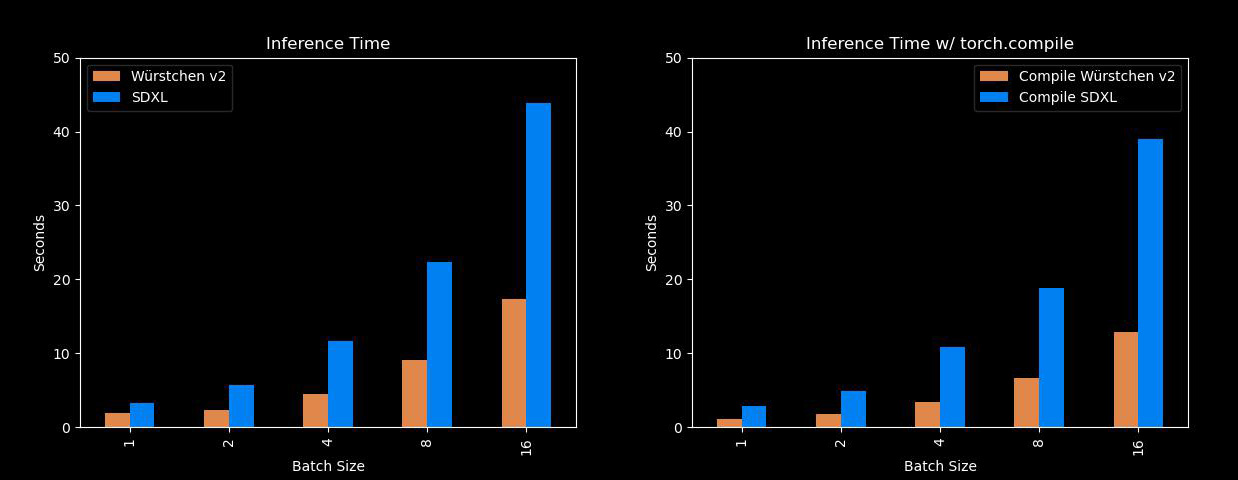
Ну, эта модель довольно быстрая и эффективная. Основные преимущества Würstchen заключаются в том, что она может генерировать изображения намного быстрее, чем модели, такие как Stable Diffusion XL, при этом используя гораздо меньше памяти! Так что для всех нас, у кого нет A100, это будет очень удобно. Вот сравнение с SDXL при разных размерах пакетов:
- Генеративное искусственное интеллект в индустрии здравоохранения нуждается в доле объяснимости
- AnomalyGPT Обнаружение промышленных аномалий с использованием LVLM
- MLCommons представил новый бенчмарк-тест скорости для запуска моделей искусственного интеллекта.
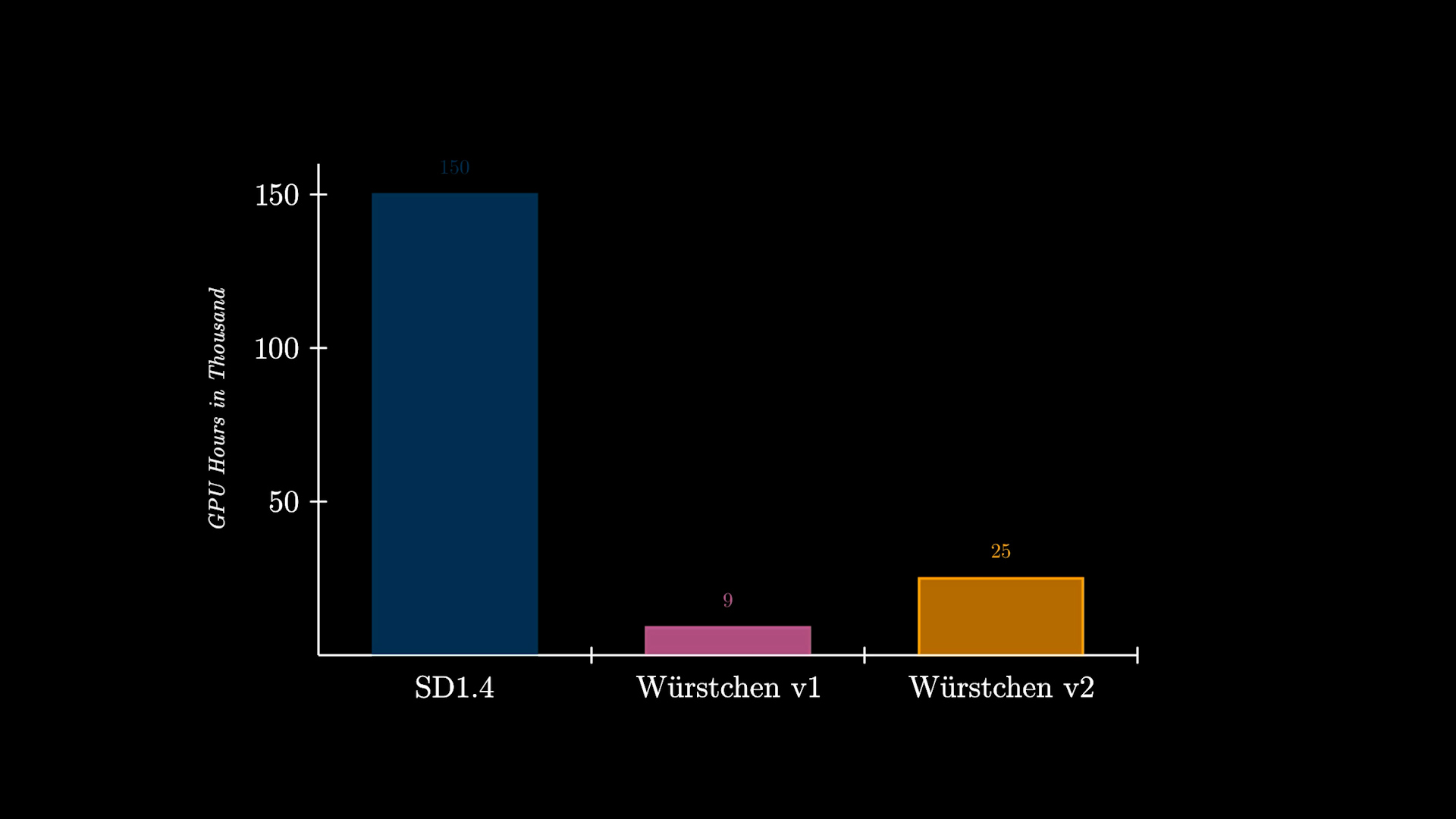
В дополнение к этому, еще одно важное преимущество Würstchen связано с снижением затрат на обучение. Würstchen v1, который работает на 512×512, требовал всего 9 000 часов работы GPU для обучения. Сравнивая это с 150 000 часами работы GPU, затраченными на Stable Diffusion 1.4, можно сделать вывод, что это снижение затрат в 16 раз не только пользует исследователям при проведении новых экспериментов, но также открывает двери для более многих организаций для обучения таких моделей. Würstchen v2 использовал 24 602 часа работы GPU. При разрешениях до 1536 это все равно на 6 раз дешевле, чем SD1.4, который обучался только на 512×512.
Вы также можете найти подробное видео-объяснение здесь:
Как использовать Würstchen?
Вы можете попробовать его с помощью Демо здесь:
В противном случае, модель доступна через библиотеку Diffusers, поэтому вы можете использовать уже знакомый вам интерфейс. Например, вот как выполнить вывод, используя AutoPipeline:
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Антропоморфный кот в костюме пожарного"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images
На каких размерах изображений работает Würstchen?
Würstchen был обучен на разрешениях изображений между 1024×1024 и 1536×1536. Иногда мы также наблюдаем хорошие результаты при разрешениях, например, 1024×2048. Пожалуйста, попробуйте. Мы также заметили, что Приор (этап C) быстро адаптируется к новым разрешениям. Так что настройка его на 2048×2048 должна быть вычислительно дешевой. 
Модели на Hub
Все контрольные точки также можно увидеть на Huggingface Hub. Там можно найти несколько контрольных точек, а также будущие демонстрации и веса моделей. В настоящее время доступно 3 контрольные точки для Prior и 1 контрольная точка для Decoder. Ознакомьтесь с документацией, где объясняются контрольные точки и для чего они могут быть использованы.
Интеграция Diffusers
Поскольку Würstchen полностью интегрирован в diffusers, он автоматически поставляется с различными дополнительными функциями и оптимизациями из коробки. Это включает в себя:
- Автоматическое использование ускоренного внимания PyTorch 2
SDPA, описанного ниже. - Поддержка реализации внимания xFormers flash, если вам нужно использовать PyTorch 1.x вместо 2.
- Отключение модели для перемещения неиспользуемых компонентов на CPU во время их неиспользования. Это экономит память с незначительным влиянием на производительность.
- Последовательное отключение CPU для ситуаций, где память действительно драгоценна. Использование памяти будет минимизировано, но это повлияет на скорость вывода.
- Взвешивание запросов с использованием библиотеки Compel.
- Поддержка устройства
mpsна компьютерах Apple Silicon. - Использование генераторов для воспроизводимости.
- Разумные значения по умолчанию для вывода, чтобы получить высококачественные результаты в большинстве ситуаций. Конечно, вы можете настраивать все параметры по своему усмотрению!
Техника оптимизации 1: Flash Attention
Начиная с версии 2.0, PyTorch интегрировал высокооптимизированную и ресурсоэффективную версию механизма внимания, называемую torch.nn.functional.scaled_dot_product_attention или SDPA. В зависимости от характера входных данных, эта функция использует несколько оптимизаций. Ее производительность и эффективность использования памяти превосходят традиционную модель внимания. Замечательно, что функция SDPA отражает характеристики техники внимания flash attention, описанной в исследовательской работе Fast and Memory-Efficient Exact Attention with IO-Awareness, написанной Дао и его командой.
Если вы используете Diffusers с PyTorch 2.0 или более поздней версией, и функция SDPA доступна, эти улучшения автоматически применяются. Начните с настройки torch 2.0 или новой версии, следуя официальным руководствам!
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesДля более подробного изучения того, как diffusers использует SDPA, ознакомьтесь с документацией.
Если вы используете версию PyTorch ранее 2.0, вы все равно можете добиться экономичного использования памяти с помощью библиотеки xFormers:
pipeline.enable_xformers_memory_efficient_attention()Техника оптимизации 2: Torch Compile
Если вам нужно дополнительное повышение производительности, вы можете использовать torch.compile. Лучше всего применять его к основной модели Prior и Decoder для наибольшего увеличения производительности.
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)Учтите, что первый шаг вывода займет длительное время (до 2 минут), пока модели будут компилироваться. После этого вы можете выполнять вывод как обычно:
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesИ хорошая новость в том, что эта компиляция выполняется один раз. После этого вы получите более быстрые выводы при одинаковых разрешениях изображений. Время, затраченное на компиляцию, быстро окупится благодаря последующим преимуществам в скорости. Для более подробного изучения torch.compile и его тонкостей ознакомьтесь с официальной документацией.
Ресурсы
- Дополнительную информацию об этой модели можно найти в официальной документации diffusers.
- Все контрольные точки можно найти на Hub
- Вы можете попробовать демонстрацию здесь.
- Присоединяйтесь к нашему Discord, если хотите обсудить будущие проекты или даже внести свои идеи!






