Введение и реализация сетей Siamese
Введение и реализация сетей Siamese' (Introduction and Implementation of Siamese Networks)
Введение
Сиамские сети предлагают увлекательный подход к классификации, позволяя точно категоризировать изображения на основе только одного примера. Эти сети используют концепцию, называемую контрастной функцией потерь, для оценки сходства между парами изображений в наборе данных. В отличие от традиционных методов, сосредоточенных на расшифровке содержимого изображений, сиамские сети сосредоточены на понимании вариаций и сходств между изображениями. Этот особый метод обучения способствует их устойчивости в условиях ограниченных данных, улучшая производительность даже без специфических знаний в области.
Эта статья углубляется в увлекательный мир верификации подписей через призму сиамских сетей. Мы расскажем вам о создании функциональной модели с использованием PyTorch, предоставляя понимание и практические шаги по реализации.
Цели обучения
- Понять концепцию сиамских сетей и их уникальную архитектуру, включающую две подсети-близнеца.
- Различить функции потерь, используемые в сиамских сетях, включая бинарную перекрестную энтропийную функцию потерь, контрастную функцию потерь и триплетную функцию потерь.
- Определить и описать реальные приложения, где сиамские сети могут быть эффективно использованы, такие как распознавание лиц, распознавание отпечатков пальцев и оценка сходства текста.
- Суммировать преимущества и недостатки сиамских сетей в отношении обучения по одному примеру, универсальности и производительности в разных областях.
Эта статья была опубликована в рамках блогосферы Data Science.
Что такое сиамские сети?
Сиамские сети относятся к категории сетей, которые используют две идентичные подсети для классификации по одному примеру. Эти подсети имеют одинаковую структуру, параметры и веса, но работают с разными входными данными. Сиамская сеть обучается функции сходства, в отличие от обычных сверточных нейронных сетей, которые обучаются на большом количестве данных для предсказания нескольких классов. Эта функция позволяет нам различать классы с использованием минимального количества данных, что делает их особенно эффективными для классификации по одному примеру. Благодаря этой уникальной способности, во многих случаях одного примера достаточно для точной классификации изображений сетями такого типа.
- Поддержка устойчивости, цифрового здоровья и будущего труда
- Представляем предварительный просмотр Amazon SageMaker Profiler Отслеживайте и визуализируйте подробные данные о производительности аппаратного обеспечения для рабочих нагрузок обучения вашей модели.
- 5 Общих проблем управления данными для аналитиков и специалистов по данным
Одно из реальных применений сиамских сетей – это распознавание лиц и верификация подписей. Представьте себе компанию, внедряющую автоматизированную систему учета на основе фотографий лиц. С тысячами сотрудников и только одним изображением каждого из них, традиционные сверточные нейронные сети столкнулись бы с трудностями при точной классификации. В этом случае сиамская сеть проявляет выдающиеся результаты.

Исследование обучения по одному примеру
В обучении по одному примеру модели обучаются делать предсказания на основе ограниченного количества примеров. Это отличается от традиционного подхода, который требует большого объема размеченных данных для обучения. Значимость обучения по одному примеру проявляется, когда получение достаточного количества размеченных данных становится сложным или дорогостоящим.
Архитектура моделей обучения по одному примеру использует нюансы небольшого количества образцов, позволяя им делать предсказания на основе только нескольких или даже одного примера. Различные архитектуры, такие как сиамские сети, мета-обучение и подобные подходы, обеспечивают эту возможность. Эти архитектуры позволяют модели извлекать значимые представления данных и использовать их для новых, незнакомых образцов.
Несколько практических примеров, где обучение по одному примеру является эффективным:
- Обнаружение объектов в системе наблюдения: Обучение по одному примеру позволяет эффективно идентифицировать объекты на видеозаписях системы наблюдения, даже когда доступно всего несколько примеров этих объектов. После обучения модели на небольшом наборе размеченных примеров она может обнаруживать эти объекты на новых видеозаписях, даже если раньше с ними не сталкивалась.

2. Персонализированная медицина: В рамках персонализированной медицины медицинские специалисты могут иметь ограниченный набор медицинских данных пациента, включающий несколько компьютерных томографий или анализов крови. Использование модели обучения по одному примеру позволяет делать прогнозы относительно будущего состояния пациента на основе таких данных. Это может включать прогнозирование возможного начала конкретного заболевания или вероятной реакции на определенный терапевтический подход.

Архитектура сиамских сетей
Дизайн сети Сиамских близнецов включает две идентичные подсети, каждая обрабатывает один из входов. Сначала входные данные проходят обработку через сверточную нейронную сеть (СНС), которая извлекает значимые особенности из предоставленных изображений. Затем эти подсети генерируют закодированные выходные данные, часто через полностью связанный слой, что приводит к сжатому представлению входных данных.
СНС состоит из двух ветвей и общего компонента извлечения признаков, состоящего из слоев свертки, нормализации пакетов и активации ReLU, за которыми следуют слои максимальной пулинга и отсева. Завершающий сегмент включает полностью связанный слой, который сопоставляет извлеченные признаки с конечными классификационными результатами. Функция определяет линейный слой, за которым следует последовательность активаций ReLU и серия последовательных операций (свертка, нормализация пакетов, активация ReLU, максимальная пулинг и отсев). Функция прямого распространения направляет входные данные через оба подразделения сети.
Слой разности служит для выявления сходств между входами и усиления различий между непохожими парами, что достигается с помощью функции евклидова расстояния:
Расстояние(x₁, x₂) = ∥f(x₁) – f(x₂)∥₂
В этом контексте,
- x₁, x₂ – два входа.
- f(x) – представляет вывод кодирования.
- Расстояние – обозначает функцию расстояния.
Это свойство позволяет сети приобретать эффективные представления данных и применять их к новым, невидимым образцам. В результате сеть генерирует кодирование, часто представленное в виде оценки сходства, которая помогает в дифференциации классов.
Иллюстрируйте архитектуру сети на сопутствующей фигуре. Отметим, что эта сеть работает как однократный классификатор, не требуя множества примеров для каждого класса.
Функции потерь, используемые в сетях Сиамских близнецов
Функция потерь – это математический инструмент для измерения различия между ожидаемым и фактическим выводом в модели машинного обучения при заданном входе. При обучении модели целью является минимизация этой функции потерь путем настройки параметров модели.
Существует множество функций потерь, которые подходят для различных типов задач. Например, среднеквадратичная ошибка подходит для задач регрессии, в то время как перекрестная энтропия подходит для задач классификации.
В отличие от нескольких других типов сетей, Сиамская сеть использует несколько функций потерь, которые будут рассмотрены ниже.
Функция потерь бинарной кросс-энтропии
Функция потерь бинарной кросс-энтропии используется для бинарных задач классификации, где целью является предсказание одного из двух возможных результатов. В контексте сети Сиамских близнецов целью является классификация изображения либо как “похожего”, либо как “непохожего” на другое изображение.
Эта функция количественно оценивает расхождение между прогнозируемой вероятностью положительного класса и фактическим результатом. В сети Сиамских близнецов прогнозируемая вероятность относится к вероятности сходства изображений, а фактический результат принимает бинарную форму: 1 для сходства изображений и 0 для их различия.
Формула функции включает отрицательный логарифм истинной вероятности класса, вычисляемый как: −(ylog(p)+(1−y)log(1−p))
Здесь,
- y обозначает истинную метку.
- p обозначает прогнозируемую вероятность.
При обучении модели с функцией потерь бинарной кросс-энтропии стремятся минимизировать эту функцию путем настройки параметров. При такой минимизации модель становится способной к точному предсказанию класса.
Контрастная функция потерь
Контрастная функция потерь исследует различия между парами изображений, используя расстояние в качестве меры сходства. Эта функция полезна, когда количество образцов обучения для каждого класса ограничено. Важно отметить, что контрастная функция потерь требует пар негативных и позитивных образцов для обучения. Визуализация этой функции потерь представлена на сопутствующей фигуре.

Уравнение контрастной функции потерь может быть:
(1 – Y) * 0.5 * D^2 + Y * 0.5 * max(0, m – D^2)
Разберемся подробнее:
- Y представляет собой входной параметр.
- D обозначает евклидово расстояние.
- Когда Y равно 0, входы принадлежат к одному классу. С другой стороны, значение Y, равное 1, означает, что они принадлежат к разным классам.
- Параметр ‘m’ определяет отступ для функции расстояния, помогая определить пары, вносящие вклад в потерю. Стоит отметить, что значение ‘m’ всегда больше 0.
Triplet Loss
Функция потерь триплета использует тройки данных. На графике ниже иллюстрируются эти тройки.

Функция потери триплета направлена на улучшение разделения между якорными и отрицательными образцами, одновременно уменьшая разрыв между якорными и положительными образцами.
Математически функция потери триплета определяется как максимальная разница между расстоянием от якоря до положительного образца (d(a,p)) и расстоянием от якоря до отрицательного образца (d(a,n)), вычитаемая из значения порога. Когда эта разница положительна, вычисленное значение становится потерей; в противном случае, оно устанавливается в ноль.
Вот разбор компонентов:
- d обозначает евклидово расстояние.
- a представляет якорный ввод.
- p обозначает положительный ввод.
- n означает отрицательный ввод.
Основная цель – убедиться, что положительный ввод ближе к якорному вводу, чем отрицательный ввод, с сохранением отступа между ними.
Построение модели на основе сети Сиамских близнецов для проверки подписей
Проверка подписи включает различение контрафактных подписей среди коллекции подлинных. В этом сценарии модель должна улавливать нюансы между многочисленными подписями. Затем она должна отличать аутентичные и поддельные подписи при предъявлении любого из них. Достижение этой цели проверки представляет собой значительный вызов для обычных сверточных нейронных сетей из-за сложных вариаций и ограниченного количества обучающих примеров. Усложняя задачу, зачастую у каждого человека имеется только одна подпись, требуя от модели умения проверять подписи тысяч людей. В следующих разделах рассматривается создание модели на основе PyTorch для решения этой сложной задачи.
Набор данных
В качестве набора данных мы будем использовать набор данных, связанный с проверкой подписей, и это ICDAR 2011. Эта коллекция включает в себя голландские подписи, включая подлинные и контрафактные. Пример данных представлен здесь для справки. Ссылка на набор данных.

Описание постановки задачи
Эта статья рассматривает задачу обнаружения контрафактных подписей в контексте проверки подписей. Наша цель заключается в использовании набора данных подписей и применении сети Сиамских близнецов для прогнозирования подлинности тестовых подписей – отличия подлинных от поддельных. Для достижения этой цели нам необходимо установить пошаговый процесс. Это включает в себя получение данных из набора данных, создание пар изображений и их последующую обработку с помощью сети Сиамских близнецов. После обучения сети с использованием предоставленного набора данных мы разрабатываем функции прогнозирования.
Импорт необходимых библиотек
Построение сети Сиамских близнецов требует включения нескольких ключевых библиотек. Мы вводим библиотеку Pillow (PIL) для работы с изображениями, matplotlib для визуализации, numpy для числовых операций и tqdm для утилиты индикатора выполнения. Кроме того, мы используем мощь PyTorch и torchvision для облегчения обучения и построения сети.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.utils as tv_utils
from torch.autograd import Variable
from torch.utils.data import DataLoader, Dataset
import PIL.Image as Image
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import torch.utils.data as custom_data
from tqdm import tqdmВспомогательные функции
Для визуализации выходов сети создайте вспомогательную функцию. Эта функция принимает изображения и соответствующие им метки в качестве входных данных и располагает их в сетке для удобной визуализации.
import numpy as np
import matplotlib.pyplot as plt
def display_image(img, caption=None, save=False):
image_array = img.numpy()
plt.axis("off")
if caption:
plt.text(
75,
8,
caption,
style="italic",
fontweight="bold",
bbox={"facecolor": "white", "alpha": 0.8, "pad": 10},
)
plt.imshow(np.transpose(image_array, (1, 2, 0)))
plt.show()Предварительная обработка данных
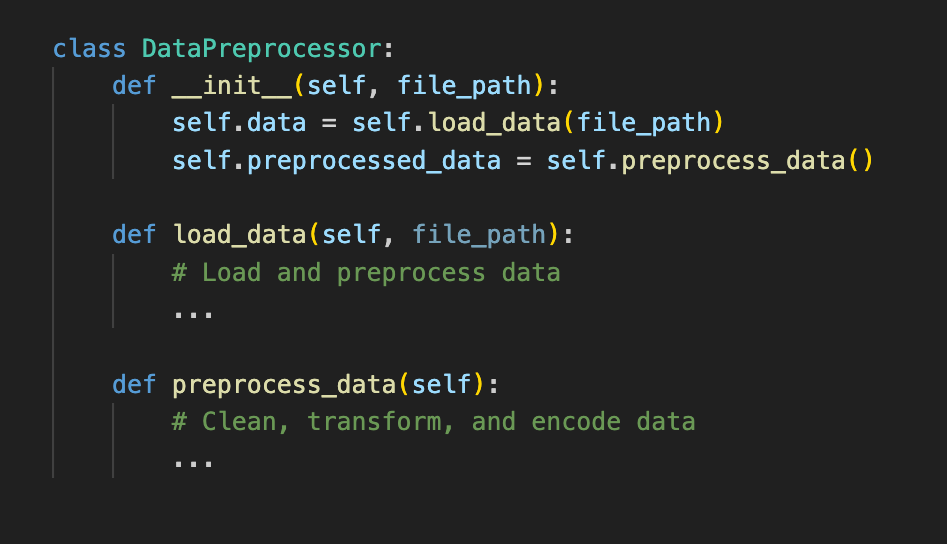
Структура данных, используемая сетью Сиамских близнецов, существенно отличается от структуры данных, используемой в обычных сетях классификации изображений. В отличие от предоставления одной пары изображение-метка, Генератор набора данных для сети Сиамских близнецов требует предоставления пар изображений. Эти пары проходят процесс преобразования, включающий преобразование в черно-белое изображение, последующее изменение размера и окончательное преобразование в тензоры. Две различные категории пар – положительные пары, характеризующиеся идентичными входными изображениями, и отрицательные пары с несходными изображениями. Кроме того, функция предоставляет размер набора данных при вызове.
import os
import pandas as pd
import torch
import torch.utils.data as data
from PIL import Image
import numpy as np
class PairedDataset(data.Dataset):
def __init__(self, df_path=None, data_dir=None, transform=None, subset=None):
self.df = pd.read_csv(df_path)
if subset is not None:
self.df = self.df[:subset]
self.df.columns = ["image1", "image2", "label"]
self.data_dir = data_dir
self.transform = transform
def __getitem__(self, index):
pair1_path = os.path.join(self.data_dir, self.df.iat[index, 0])
pair2_path = os.path.join(self.data_dir, self.df.iat[index, 1])
pair1 = Image.open(pair1_path).convert("L")
pair2 = Image.open(pair2_path).convert("L")
if self.transform:
pair1 = self.transform(pair1)
pair2 = self.transform(pair2)
label = torch.tensor([int(self.df.iat[index, 2])], dtype=torch.float32)
return pair1, pair2, label
def __len__(self):
return len(self.df)Краткий обзор функций
Входные данные сети состоят из изображений, включающих положительные и отрицательные пары данных. Мы представляем эти пары в виде изображений и преобразуем их в формат Tensor, эффективно инкапсулируя информацию об изображении. Метки, связанные с сетью Сиамского типа, являются категориальными.
Процесс стандартизации признаков
Важным шагом является стандартизация признаков и преобразование изображений в черно-белый формат. Кроме того, мы равномерно изменяем размер всех изображений до квадратного формата (105×105), так как Сеть Сиамского типа требует такого размера. Затем мы преобразуем все изображения в тензоры, что повышает вычислительную эффективность и позволяет использовать GPU.
data_transform = transforms.Compose([
transforms.Resize((105, 105)),
transforms.ToTensor()
])Разделение набора данных
Мы разделяем набор данных на отдельные обучающие и тестовые сегменты, чтобы облегчить как обучение, так и тестирование модели. Для удобства иллюстрации мы сосредоточимся на первых 1000 точках данных. Если значение функции ‘load_subset’ равно None, это означает использование полного набора данных, но это может затянуть обработку. Рассмотрите возможность использования аугментации данных для повышения долгосрочной производительности сети.
train_dataset = PairedDataset(
df_train,
dir_train,
transform=transforms.Compose([
transforms.Resize((105, 105)),
transforms.ToTensor()
]),
subset=1000
)
evaluation_dataset = PairedDataset(
df_val,
dir_val,
transform=transforms.Compose([
transforms.Resize((105, 105)),
transforms.ToTensor()
]),
subset=1000
)Архитектура нейронной сети
Построение описанной архитектуры включает несколько шагов. Сначала мы создаем функцию, которая создает набор сверточных слоев, слоев Batch Normalization и ReLU, предлагая возможность включать или исключать слой Dropout в конце. Другая функция создает последовательности полносвязных (FC) слоев, дополненных последующими слоями ReLU. Когда компонент CNN создан с помощью вышеупомянутых функций, мы переходим к формированию сегмента FC сети. Сеть использует разные размеры отступов и ядер в разных частях.
Сегмент FC состоит из блоков, включающих линейные слои, за которыми следуют активации ReLU. Определенная архитектура позволяет выполнять прямой проход данных через сеть. Важным аспектом является функция “view”, которая изменяет форму выхода предыдущего блока, выравнивая размерности. Таким образом, после создания этого механизма можно приступить к тренировке сети Сиамского типа с использованием предоставленных данных.
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.cnn1 = nn.Sequential(
self.create_conv_block(1, 96, 11, 1, False),
self.create_conv_block(96, 256, 5, 2, True),
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(384),
nn.ReLU(inplace=True),
self.create_conv_block(384, 256, 3, 1, True),
)
self.fc1 = nn.Sequential(
self.create_linear_relu(30976, 1024),
nn.Dropout2d(p=0.5),
self.create_linear_relu(1024, 128),
nn.Linear(128, 2)
)
def create_linear_relu(self, input_channels, output_channels):
return nn.Sequential(nn.Linear(input_channels, output_channels),
nn.ReLU(inplace=True))
def create_conv_block(self, input_channels, output_channels, kernel_size,
padding, dropout=True):
if dropout:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size,
stride=1, padding=padding),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2),
nn.Dropout2d(p=0.3)
)
else:
return nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size,
stride=1),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2)
)
def forward_once(self, x):
output = self.cnn1(x)
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
out1 = self.forward_once(input1)
out2 = self.forward_once(input2)
return out1, out2Функция потерь
Функция контрастной потери служит основной функцией потерь для сети Сиамских. Определение этой функции потерь включает использование уравнений, объясненных ранее в статье. Для повышения эффективности кода, вместо определения функции потерь как простой функции, альтернативный подход предполагает наследование от класса nn.Module. Это позволяет создать настраиваемый класс, который предоставляет выходные данные функции. Такая обертка позволяет PyTorch оптимизировать выполнение кода, тем самым улучшая общую производительность.
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_positive = (1 - label) * torch.pow(euclidean_distance, 2)
loss_negative = label * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2)
total_loss = torch.mean(loss_positive + loss_negative)
return total_lossОбучение сети Сиамских
С загруженными и предобработанными данными установлены условия для начала обучения сети Сиамских. Для запуска этого процесса мы начинаем с определения загрузчиков данных для обучения и тестирования. Отметим, что загрузчик данных для оценки настроен с размером пакета 1 для облегчения индивидуальных оценок. Затем модель развертывается на GPU, и определяются ключевые компоненты, такие как функция контрастной потери и оптимизатор Adam.
train_loader = DataLoader(train_dataset,
shuffle=True,
num_workers=8,
batch_size=bs)
eval_loader = DataLoader(evaluation_dataset,
shuffle=True,
num_workers=8,
batch_size=1)
siamese_net = SiameseNetwork().cuda()
loss_function = ContrastiveLoss()
optimizer = torch.optim.Adam(siamese_net.parameters(), lr=1e-3, weight_decay=0.0005)Затем создается функция, принимающая загрузчик данных для обучения в качестве входных данных. Внутри этой функции поддерживается массив для отслеживания потерь и счетчик для упрощения последующей визуализации. Последующий итеративный процесс проходит через точки данных в загрузчике данных. Для каждой точки изображения пары переносятся на GPU, подвергаются обработке сетью, и вычисляется контрастная потеря. Последующие шаги включают выполнение обратного прохода, что приводит к получению общей потери для пакета данных.
def train(train_loader, model, optimizer, loss_function):
total_loss = 0.0
num_batches = len(train_loader)
model.train()
for batch_idx, (pair_left, pair_right, label) in
enumerate(tqdm(train_loader, total=num_batches)):
pair_left, pair_right, label = pair_left.cuda(),
pair_right.cuda(), label.cuda()
optimizer.zero_grad()
output1, output2 = model(pair_left, pair_right)
contrastive_loss = loss_function(output1, output2, label)
contrastive_loss.backward()
optimizer.step()
total_loss += contrastive_loss.item()
mean_loss = total_loss / num_batches
return mean_lossМодель может быть обучена в течение нескольких эпох с использованием нашей разработанной функции. В этой демонстрации статья охватывает только ограниченное число эпох. Если оценочная потеря, достигнутая во время обучения, представляет собой лучшую производительность, наблюдаемую в течение всего обучения, модель сохраняется для последующего использования на этой конкретной эпохе.
best_eval_loss = float('inf')
for epoch in tqdm(range(1, num_epoch)):
train_loss = train(train_loader)
eval_loss = evaluate(eval_loader)
print(f"Epoch: {epoch}")
print(f"Training loss: {train_loss}")
print(f"Evaluation loss: {eval_loss}")
if eval_loss < best_eval_loss:
best_eval_loss = eval_loss
print(f"Best Evaluation loss: {best_eval_loss}")
torch.save(siamese_net.state_dict(), "model.pth")
print("Model Saved Successfully")Тестирование модели
После обучения модели следует этап оценки, который позволяет оценить ее производительность и провести выводы для отдельных точек данных. Аналогично функции обучения, создается функция оценки, принимающая загрузчик тестовых данных в качестве входных данных. Загрузчик данных проходится, обрабатывая один экземпляр за раз. Затем извлекаются изображения пар для тестирования. Эти пары затем отправляются на GPU, что позволяет выполнить модель. Полученные выходы модели используются для вычисления контрастной потери, которая затем сохраняется в специальном списке.
def evaluate(eval_loader):
loss_list = []
counter_list = []
iteration_number = 0
for i, data in tqdm(enumerate(eval_loader, 0), total=len(eval_loader)):
pair_left, pair_right, label = data
pair_left, pair_right, label = pair_left.cuda(), pair_right.cuda(), label.cuda()
output1, output2 = siamese_net(pair_left, pair_right)
contrastive_loss = loss_function(output1, output2, label)
loss_list.append(contrastive_loss.item())
loss_array = np.array(loss_list)
mean_loss = loss_array.mean() / len(eval_loader)
return mean_lossМы можем выполнить код, чтобы выполнить единичную оценку для всех точек тестовых данных. Чтобы оценить производительность визуально, мы сгенерируем графики, изображающие изображения и отобразим попарные расстояния, определенные моделью между точками данных. Представьте эти результаты в виде сетки.
for i, data in enumerate(dl_eval, 0):
x0, x1, label = data
concat_images = torch.cat((x0, x1), 0)
out1, out2 = siamese_net(x0.to('cuda'), x1.to('cuda'))
euclidean_distance = F.pairwise_distance(out1, out2)
print(label)
if label == torch.FloatTensor([[0]]):
label_text = "Оригинальная пара подписей"
else:
label_text = "Поддельная пара подписей"
display_images(torchvision.utils.make_grid(concat_images))
print("Предсказанное евклидово расстояние:", euclidean_distance.item())
print("Фактическая метка:", label_text)
if i == 4:
breakРезультат

Преимущества и недостатки сетей Сиамских близнецов
Недостатки
- Один из заметных недостатков сетей Сиамских близнецов заключается в их выходных данных, которые предоставляют сходство, а не вероятностное распределение, суммирующееся до 1. Эта характеристика может вызывать проблемы в некоторых приложениях, где предпочтительны выходы на основе вероятности.
Преимущества
- Сети Сиамских близнецов обладают устойчивостью при работе с разным количеством примеров в разных классах. Эта адаптивность обусловлена способностью сети эффективно функционировать с ограниченной информацией о классе.
- Производительность классификации сети не зависит от предоставления специфичной для области информации, что способствует ее универсальности.
- Сети Сиамских близнецов могут делать предсказания, даже если есть только одно изображение на класс.
Применения сетей Сиамских близнецов
Сети Сиамских близнецов находят применение в различных приложениях, некоторые из которых описаны ниже.
Распознавание лиц: Сети Сиамских близнецов оказывают преимущества в задачах распознавания лиц с одним выстрелом. Используя контрастную потерю, эти сети отличают непохожие лица от похожих, обеспечивая эффективную идентификацию лиц с минимальным количеством образцов данных.

Распознавание отпечатков пальцев: Используйте сети Сиамских близнецов для распознавания отпечатков пальцев. Предоставляя пары предварительно обработанных отпечатков пальцев сети, она научится различать допустимые и недопустимые отпечатки, повышая точность аутентификации на основе отпечатков пальцев.

Проверка подписи: В данной статье в основном рассматривается реализация проверки подписи с помощью сетей Сиамских близнецов. Как показано, сеть обрабатывает пары подписей для определения подлинности подписей, отличая их от поддельных.

Оценка сходства текста: Сети Сиамских близнецов также находят применение при оценке сходства текста. С помощью сопоставленного ввода сеть может определить сходства между разными текстовыми фрагментами. Практические применения включают идентификацию аналогичных вопросов в банке вопросов или поиск аналогичных документов в текстовом хранилище.

Заключение
Сиамская нейронная сеть, часто сокращаемая до SNN, относится к категории нейронных сетей, включающих две или более подсети, имеющие одинаковую структуру. В этом контексте “одинаковая” означает наличие совпадающих конфигураций, параметров и весов. Синхронизация обновления параметров между этими подсетями определяет сходства между входными данными путем сравнения векторов признаков.
Основные выводы
- Сиамские сети отлично справляются с классификацией наборов данных с ограниченным количеством примеров для каждого класса, что делает их ценными для сценариев с ограниченными тренировочными данными.
- В ходе этого исследования мы получили представление о основных принципах, лежащих в основе сиамских сетей, включая их архитектуру, используемые функции потерь и процесс тренировки таких сетей.
- Наш путь охватывал практическое применение сиамских сетей в контексте проверки подписей с использованием набора данных ICDAR 2011. Это включало создание модели, способной обнаруживать поддельные подписи.
- Стало ясным процесс тренировки и тестирования сиамских сетей, что предоставило всеобъемлющее понимание их работы. Мы углубились в представление сопряженных данных, являющихся важным аспектом их эффективности.
Часто задаваемые вопросы
Медиа, показанное в этой статье, не является собственностью Analytics Vidhya и используется по усмотрению автора.