Использование SQL для понимания тенденций карьеры в области науки о данных
Использование SQL в анализе карьеры в науке о данных.

В мире, где данные являются новой нефтью, понимание тонкостей карьеры в области науки о данных становится более важным, чем когда-либо. Будь то энтузиаст данных, ищущий или ветеран, исследующий возможности, использование SQL может предложить идеи о рынке труда в области науки о данных.
Надеюсь, вам интересно узнать, какие названия должностей в области науки о данных являются наиболее привлекательными, или какие из них предлагают самые высокие зарплаты. Или, возможно, вы задаетесь вопросом, как уровень опыта связан с средними зарплатами в области науки о данных?
В этой статье мы рассмотрим все эти вопросы (и не только), проникая в глубь рынка труда в области науки о данных. Поехали!
- Геопространственная наука о данных анализ шаблонов точек
- 10 лучших курсов временных рядов для освоения этого важного навыка в области науки о данных
- Топ-10 проектов по веб-скрапингу, которые можно выполнить в 2023 году
Тенденция зарплат по наборам данных
Набор данных, который мы будем использовать в этой статье, разработан для прояснения шаблонов зарплат в области науки о данных с 2021 по 2023 год. Подробно рассматривая такие элементы, как история работы, должности и корпоративные местоположения, он предлагает важные идеи о разбросе заработных плат в этом секторе.
В этой статье мы найдем ответы на следующие вопросы:
- Какова средняя зарплата в разных уровнях опыта?
- Какие наиболее распространенные названия должностей в области науки о данных?
- Как меняется распределение зарплат в зависимости от размера компании?
- Где находятся основные географические местоположения вакансий в области науки о данных?
- Какие названия должностей предлагают наивысшие зарплаты в области науки о данных?
Вы можете скачать эти данные с Kaggle.
1. Как выглядит средняя зарплата в разных уровнях опыта?
В этом SQL-запросе мы находим среднюю зарплату для разных уровней опыта. Клауза GROUP BY группирует данные по уровню опыта, а функция AVG вычисляет среднюю зарплату для каждой группы.
Это помогает понять, как опыт в этой области влияет на потенциал заработка, что является важным для планирования вашей карьеры в области науки о данных. Давайте посмотрим на код.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
Теперь давайте визуализируем этот вывод, используя Python.
Вот код.
# Импорт необходимых библиотек для построения графиков
import matplotlib.pyplot as plt
import seaborn as sns
# Настройка стиля для графиков
sns.set(style="whitegrid")
# Инициализация списка для хранения графиков
graphs = []
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Средняя зарплата по уровню опыта')
plt.xlabel('Уровень опыта')
plt.ylabel('Средняя зарплата (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Теперь давайте сравним зарплаты для уровней Entry_Level и Experienced, а также Mid-Level и Senior.
Начнем с уровней Entry_Level и Experienced. Вот код.
# Фильтрация данных для уровней Entry_Level и Experienced
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# Фильтрация данных для уровней Mid-Level и Senior
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# Построение графика Entry_Level vs Experienced
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Средняя зарплата: Entry_Level vs Experienced')
plt.xlabel('Уровень опыта')
plt.ylabel('Средняя зарплата (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Вот график.
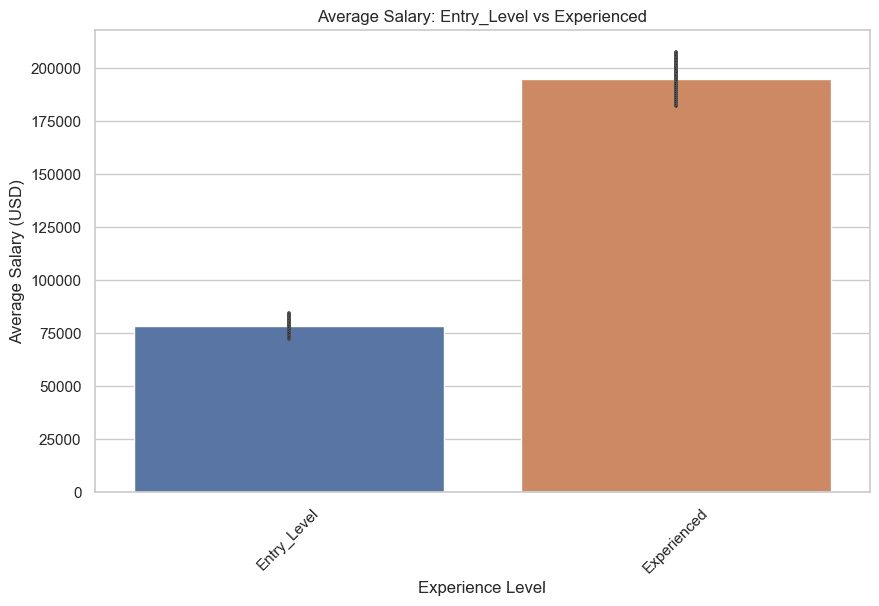
Теперь давайте построим график для уровней Mid-Level и Senior. Вот код.
# Построение графика Mid-Level vs Senior
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Средняя зарплата: Mid-Level vs Senior')
plt.xlabel('Уровень опыта')
plt.ylabel('Средняя зарплата (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show() 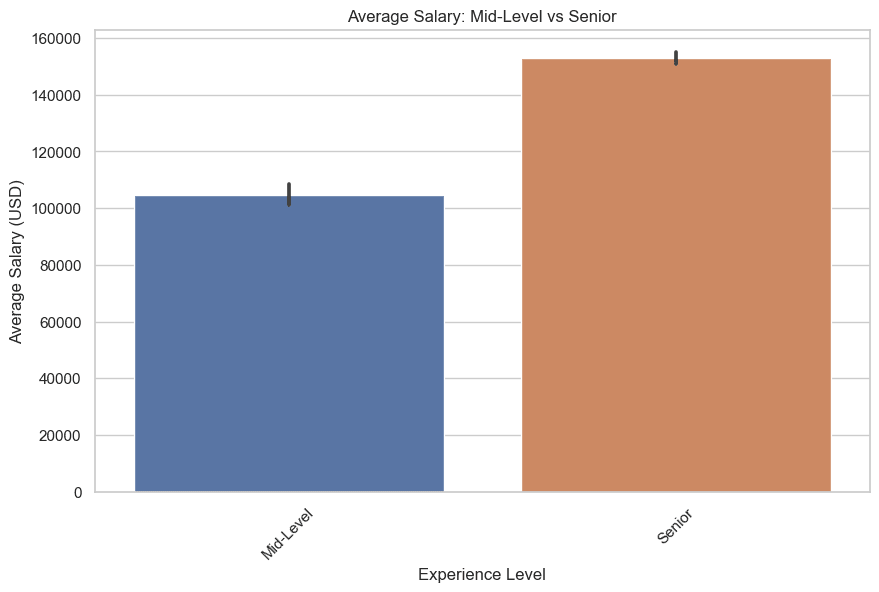
2. Какие наиболее распространенные названия должностей в области науки о данных?
Здесь мы извлекаем 10 наиболее распространенных названий должностей в области науки о данных. Функция COUNT подсчитывает количество вхождений каждого названия должности, а результаты упорядочиваются в порядке убывания, чтобы получить наиболее распространенные названия вверху.
Эта информация дает вам представление о спросе на рынке труда, что помогает вам определить потенциальные роли, на которые вы можете нацелиться. Давайте посмотрим на код.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
Хорошо, пришло время визуализировать этот запрос, используя Python.
Вот код.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Наиболее распространенные названия должностей в области науки о данных')
plt.xlabel('Количество должностей')
plt.ylabel('Название должности')
graphs.append(plt.gcf())
plt.show()
Давайте посмотрим на график.
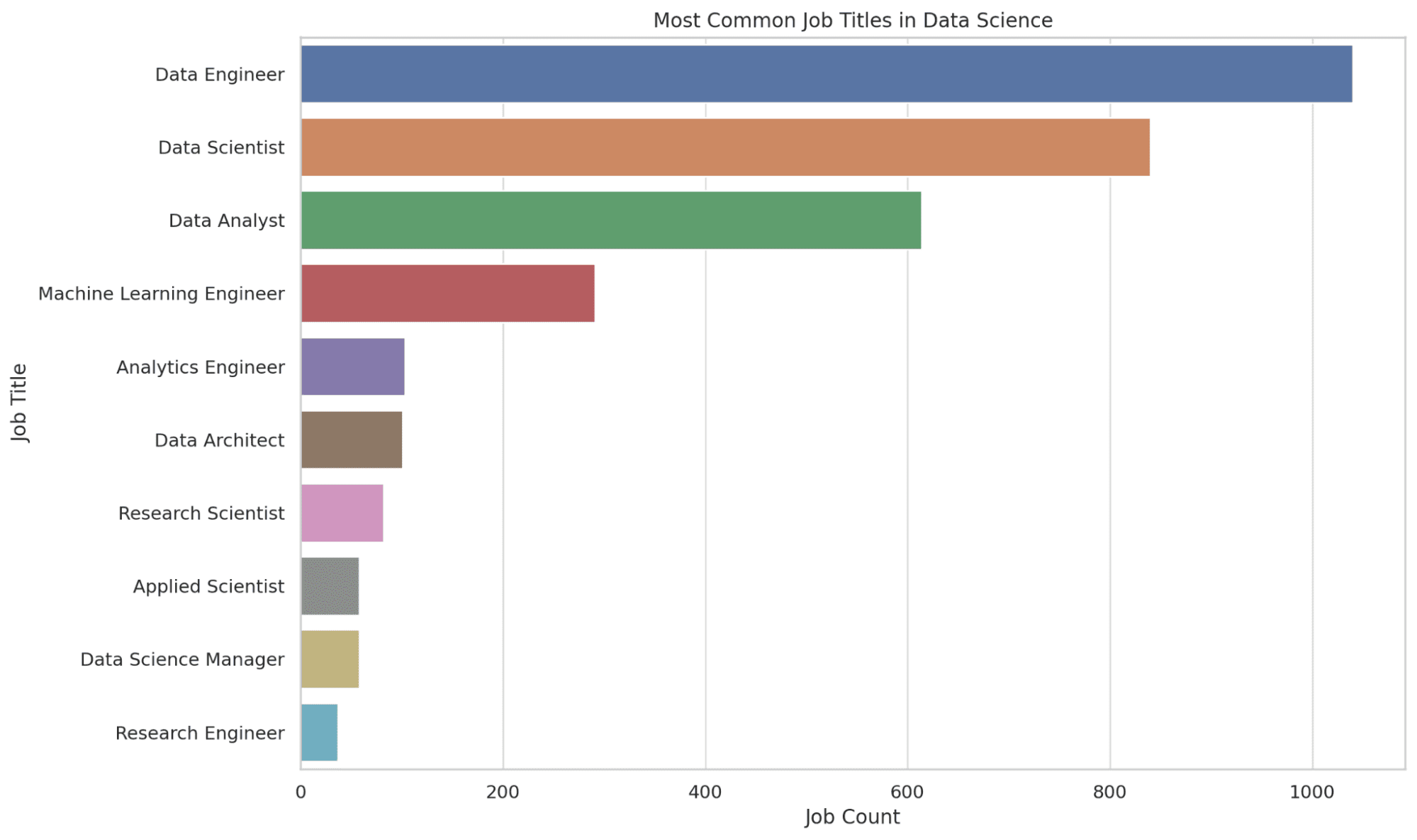
3. Как меняется распределение зарплаты в зависимости от размера компании?
В этом запросе мы извлекаем среднюю, минимальную и максимальную зарплаты для каждой группы размера компании. Использование агрегатных функций, таких как AVG, MIN и MAX, помогает получить всестороннее представление о зарплатном ландшафте в связи с размером компании.
Эти данные важны, поскольку они помогают вам понять потенциальный уровень заработной платы, который вы можете ожидать в зависимости от размера компании, в которую вы собираетесь присоединиться, давайте посмотрим на код.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
Теперь давайте визуализируем этот запрос с помощью Python.
Вот код.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Маленькая', 'VoAGI', 'Большая'])
plt.title('Распределение зарплаты в зависимости от размера компании')
plt.xlabel('Размер компании')
plt.ylabel('Средняя зарплата (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Вот результат.
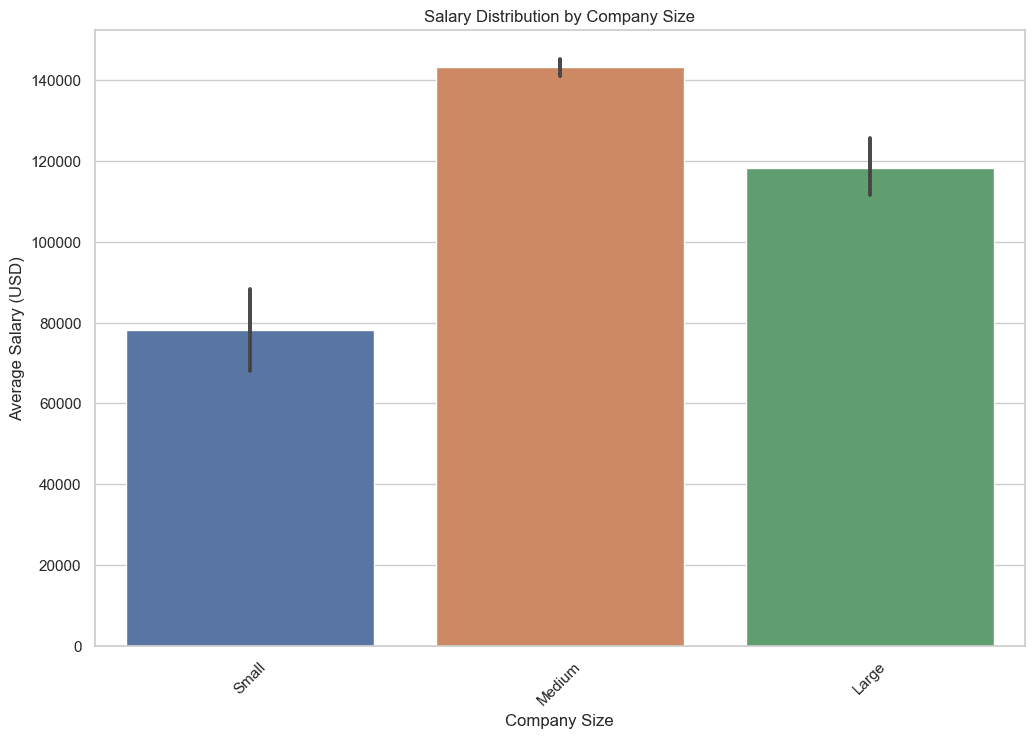
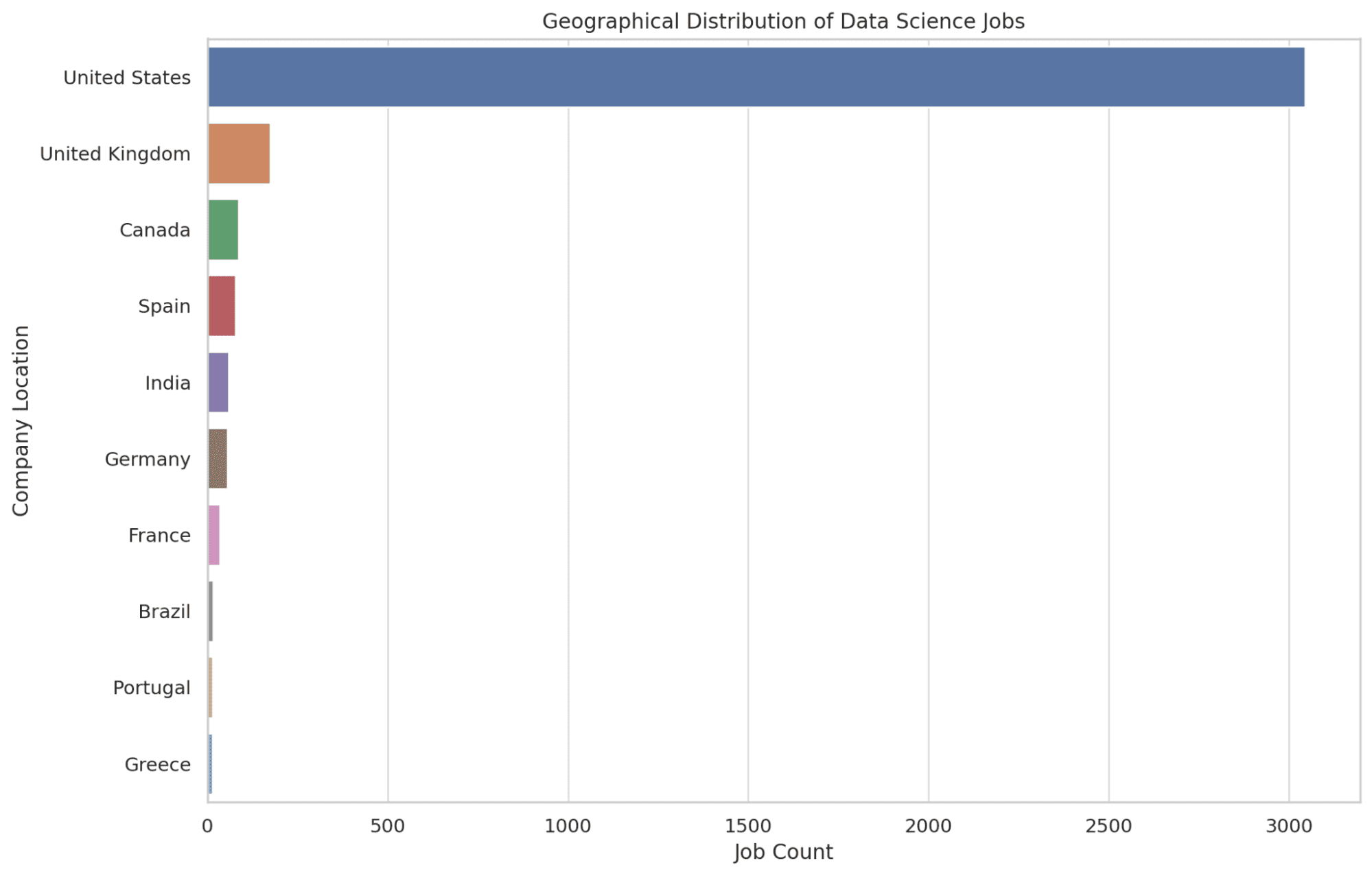
4. Где находятся основные места работы в области науки о данных с географической точки зрения?
Здесь мы указываем 10 основных мест, где находится наибольшее количество вакансий в области науки о данных. Мы используем функцию COUNT, чтобы определить количество объявлений о вакансиях в каждом месте, упорядочивая их в порядке убывания, чтобы обратить внимание на области с наибольшими возможностями.
Имея эту информацию, читатели получают представление о географических областях, которые являются центрами для должностей в области науки о данных, что помогает принимать решения о возможной релокации. Давайте посмотрим на код.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
Теперь давайте создадим графики для вышеуказанного кода с помощью Python.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Географическое распределение вакансий в области науки о данных')
plt.xlabel('Количество вакансий')
plt.ylabel('Место компании')
graphs.append(plt.gcf())
plt.show()
Давайте посмотрим на график ниже.
5. Какие должности предлагают самую высокую зарплату в области Data Science?
Здесь мы определяем 10 самых высокооплачиваемых должностей в секторе Data Science. Используя AVG, мы рассчитываем среднюю зарплату для каждой должности, сортируя их в порядке убывания на основе средней зарплаты, чтобы выделить самые прибыльные позиции.
Вы можете стремиться к этому в своем карьерном пути, изучая эти данные. Давайте продолжим, чтобы понять, как читатели могут создать визуализацию на Python для этих данных.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
Вот результат.
(Здесь мы не можем использовать фотографии, потому что мы добавили 4 фотографии выше, а одну оставили для миниатюры. Есть ли у нас шанс использовать таблицу, как показано ниже, чтобы продемонстрировать результат?)
| Ранг | Должность | Средняя зарплата (USD) |
| 1 | Data Science Tech Lead | 375,000.00 |
| 2 | Cloud Data Architect | 250,000.00 |
| 3 | Data Lead | 212,500.00 |
| 4 | Data Analytics Lead | 211,254.50 |
| 5 | Principal Data Scientist | 198,171.13 |
| 6 | Director of Data Science | 195,140.73 |
| 7 | Principal Data Engineer | 192,500.00 |
| 8 | Инженер программного обеспечения машинного обучения | 192,420.00 |
| 9 | Data Science Manager | 191,278.78 |
| 10 | Applied Scientist | 190,264.48 |
На этот раз давайте попробуем создать график самостоятельно.
Советы: Вы можете использовать следующую подсказку в ChatGPT для генерации кода на Python для этого графика:
<SQL-запрос здесь>
Создайте график на Python для визуализации 10 самых высокооплачиваемых должностей в Data Science, аналогично выводам, полученным из указанного выше SQL-запроса.
Итоги
По мере завершения нашего путешествия по разнообразным просторам карьеры в области Data Science, мы надеемся, что SQL окажется надежным проводником, помогая вам обнаружить ценные идеи для поддержки ваших карьерных решений.
Надеюсь, теперь вы чувствуете себя более подготовленными, не только в формировании своего карьерного пути, но и в использовании SQL для превращения необработанных данных в мощные истории. Так что вот мы и ступаем в будущее, полное возможностей, с данными в качестве вашего компаса и SQL в качестве вашей направляющей силы!
Спасибо за чтение! Нэйт Росиди – это дата-сайентист и стратег в области продуктов. Он также внештатный преподаватель аналитики и основатель StrataScratch, платформы, помогающей дата-сайентистам подготовиться к собеседованиям с реальными вопросами от ведущих компаний. Свяжитесь с ним в Twitter: StrataScratch или LinkedIn.





