От сырых данных до улучшенных путешествие через предварительную обработку данных — Часть 3 Дублирование данных
От сырых данных до улучшенных путешествие через предварительную обработку данных — Часть 3 Дублирование данных' -> 'Предварительная обработка данных Часть 3 — Дублирование данных
Эта статья расскажет, как определить дублирующие записи в данных и различные способы решения проблемы дублирующих записей.
Почему наличие дублирующих записей в данных является проблемой?
Наличие дублирующих значений в данных часто игнорируется многими программистами. Однако, работа с дублирующими записями в данных является важной.
Наличие дублирующих записей может привести к неправильному анализу данных и принятию решений.
Например, что происходит, когда вы заменяете пропущенные значения (импьютацию) средним значением в данных с дублирующимися записями?
- Фиктивные данные о жалобах на банк
- Обнаружение строк и столбцов таблиц на изображениях с использованием трансформеров
- Как я создал каскадную систему обработки данных на основе AWS (Часть 2)
В этом случае, может быть использовано неправильное среднее значение для импьютации. Рассмотрим пример.
Рассмотрим следующие данные. Данные содержат два столбца, а именно Имя и Вес. Обратите внимание, что значение веса для ‘John’ повторяется. Кроме того, значение веса для ‘Steve’ отсутствует.
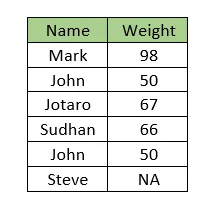
Если вы хотите заменить пропущенное значение веса для Steve средним значением всех значений веса, то импьютация будет выполнена с использованием неправильного среднего значения, т.е.,
(98 + 50 + 67 + 66 + 50)/5 = 66.2
Но фактическое среднее значение данных с игнорированием дублирующегося значения равно
(98 + 50 + 67 + 66)/4 = 70.25
Таким образом, пропущенное значение будет неправильно замещено, если мы ничего не сделаем с дублирующими записями.
Более того, дублирующиеся значения могут повлиять на бизнес-решения, принимаемые на основе таких ошибочных данных.
В итоге, дублирующиеся записи из данных следует устранить, чтобы данные были свободны от проблем.
Теперь давайте рассмотрим различные методы работы с дублирующими записями в данных.
Определение дублирующих значений в данных
Мы можем использовать метод duplicated из библиотеки pandas, чтобы определить строки, которые дублируются в данных.
Теперь давайте разберемся с дублирующимися значениями на примере.
## Импорт необходимых библиотекimport numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')## Создание фрейма данныхName = ['Mark', 'John', 'Jotaro', 'Mark', 'John', 'Steve']Weight = [98, 50, 67, 66, 50, np.nan]Height = [170, 175, 172, 170, 175, 166]df = pd.DataFrame()df['Name'] = Namedf['Weight'] = Weightdf['Height'] = Heightdf
Определение дублирующих значений:
## Определение дублирующих значений (поведение по умолчанию)df.duplicated()
Мы получаем значение True, где присутствует дублирующая запись, и False, где присутствуют уникальные записи.
Обратите внимание, что по умолчанию метод duplicated() использует все столбцы для поиска дублирующих записей. Однако, мы также можем использовать подмножество столбцов для поиска дубликатов. Для этого у метода duplicated() есть параметр с именем subset. Параметр subset принимает список имен столбцов, которые мы хотим использовать для поиска дубликатов.
## Параметр subset метода duplicated()df.duplicated(subset=['Name','Height'])
Кроме того, метод duplicated() имеет еще один важный параметр с именем keep. Значение параметра keep определяет, будем ли мы считать первую запись или последнюю запись в качестве уникальной среди всех дублированных записей. У нас также есть вариант, когда мы можем считать все дублирующиеся записи как непринадлежащие к уникальным.
keep = ‘first’: Первая запись среди всех дублирующихся записей считается уникальной.
keep = ‘last’: Последняя запись среди всех дублирующихся записей считается уникальной.
keep = False: Все дублирующиеся записи считаются непринадлежащими к уникальным.
## параметр keep метода duplicated()df.duplicated(keep='first')
Обратите внимание, что первое дублирующееся значение (с индексом 1) считается уникальным, а все остальные (с индексом 4) считаются дубликатами.
## параметр keep метода duplicated()df.duplicated(keep='last')
Обратите внимание, что последнее дублирующееся значение (с индексом 4) считается уникальным, а все остальные (с индексом 1) считаются дубликатами.
## параметр keep метода duplicated()df.duplicated(keep=False)
Обратите внимание, что показаны все дублирующиеся записи (с индексом 1 и индексом 4).
Как обрабатывать дублирующиеся записи в данных
Следующий шаг после определения дублирующихся записей – обработка их.
Существует два способа обработки дублирующихся записей в данных.
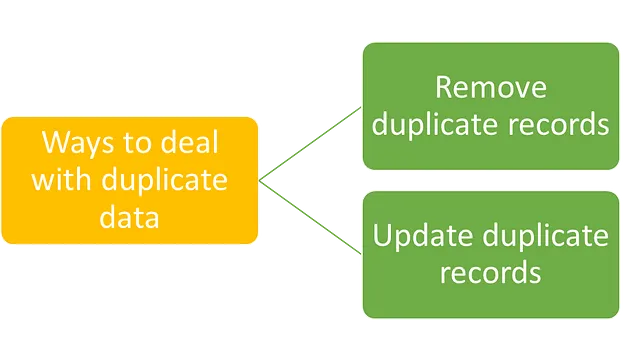
Удаление дублирующихся записей
Давайте начнем с подхода, при котором мы удаляем дублирующиеся записи.
Мы можем использовать метод drop_duplicates() из библиотеки pandas для этого.
По умолчанию метод drop_duplicates() сохраняет первую запись из набора всех дублирующихся записей и затем удаляет остальные из данных. Кроме того, по умолчанию метод drop_duplicates() использует все столбцы для определения дублирующихся записей.
Но это поведение по умолчанию можно изменить с помощью двух параметров метода drop_duplicates(). Они являются:
- keep
- subset
Они работают точно так же, как параметры keep и subset метода duplicated().
"""удаление дублирующихся значений с использованием метода drop_duplicates() из библиотеки pandas (поведение по умолчанию)"""df1 = df.drop_duplicates()df1
"""удаление дублирующихся значений с использованием метода drop_duplicates() из библиотеки pandas с параметрами subset и keep (настраиваемое поведение)"""df2 = df.drop_duplicates(subset=['Weight'], keep='last')df2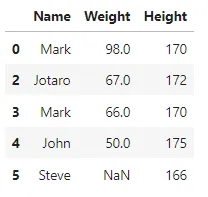
Обновление дублирующихся записей
Иногда мы хотим заменить дублирующиеся записи некоторым значением. Допустим, мы нашли две дублирующиеся записи, а затем узнали, что человек, получивший данные, случайно указал неправильное имя в одной из дублирующихся записей. Таким образом, мы бы хотели вставить имя правильного человека. Таким образом, мы решаем проблему дублирующихся значений.
df.duplicated(keep=False)
Здесь у нас есть дублирующиеся записи в индексах 1 и 4. Теперь, если мы изменим значение столбца ‘Name’ в индексе 1, у нас больше не будет повторяющихся значений.
## изменяем значение 'Name' для первой дублирующейся записиdf.iloc[1, 0] = 'Dio' df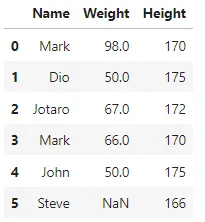
Мы изменили значение ‘Name’ для первой дублирующейся записи. Теперь давайте снова проверим, есть ли дублирующиеся записи в данных или нет.
df.duplicated()
Теперь у нас нет дублирующихся записей.
Спасибо за чтение! Если у вас есть мысли по поводу статьи, пожалуйста, дайте мне знать.
Вы испытываете затруднения с выбором следующей статьи для чтения? Не волнуйтесь, я знаю статью, которая, по моему мнению, вам будет интересна.
От сырых данных к улучшенным: путешествие по предобработке данных — Часть 2: Пропущенные значения
Почему заниматься обработкой пропущенных значений?
pub.towardsai.net
и еще одна…
От сырых данных к улучшенным: путешествие по предобработке данных — Часть 1: Масштабирование признаков
Иногда данные, которые мы получаем для наших задач машинного обучения, не имеют подходящего формата для кодирования с использованием Scikit-Learn…
pub.towardsai.net
Шивам Шинде
- Свяжитесь со мной в LinkedIn
- Также вы можете следить за мной на VoAGI
Хорошего дня!
Ссылки:
Обработка дублирующихся значений в Pandas DataFrame
Как аналитику данных нашей ответственностью является обеспечение целостности данных для получения точных и надежных исследований. Данные…
stackabuse.com
Поиск дублирующихся строк в DataFrame на основе всех или выбранных столбцов – GeeksforGeeks
Портал по компьютерным наукам для гиков. Здесь вы найдете хорошо написанные, продуманные и подробно объясненные статьи по компьютерным наукам…
www.geeksforgeeks.or
Метод duplicated() в Pandas DataFrame
W3Schools предлагает бесплатные онлайн-учебники, справочники и упражнения на всех основных языках веба. Охватывает…
www.w3schools.com





