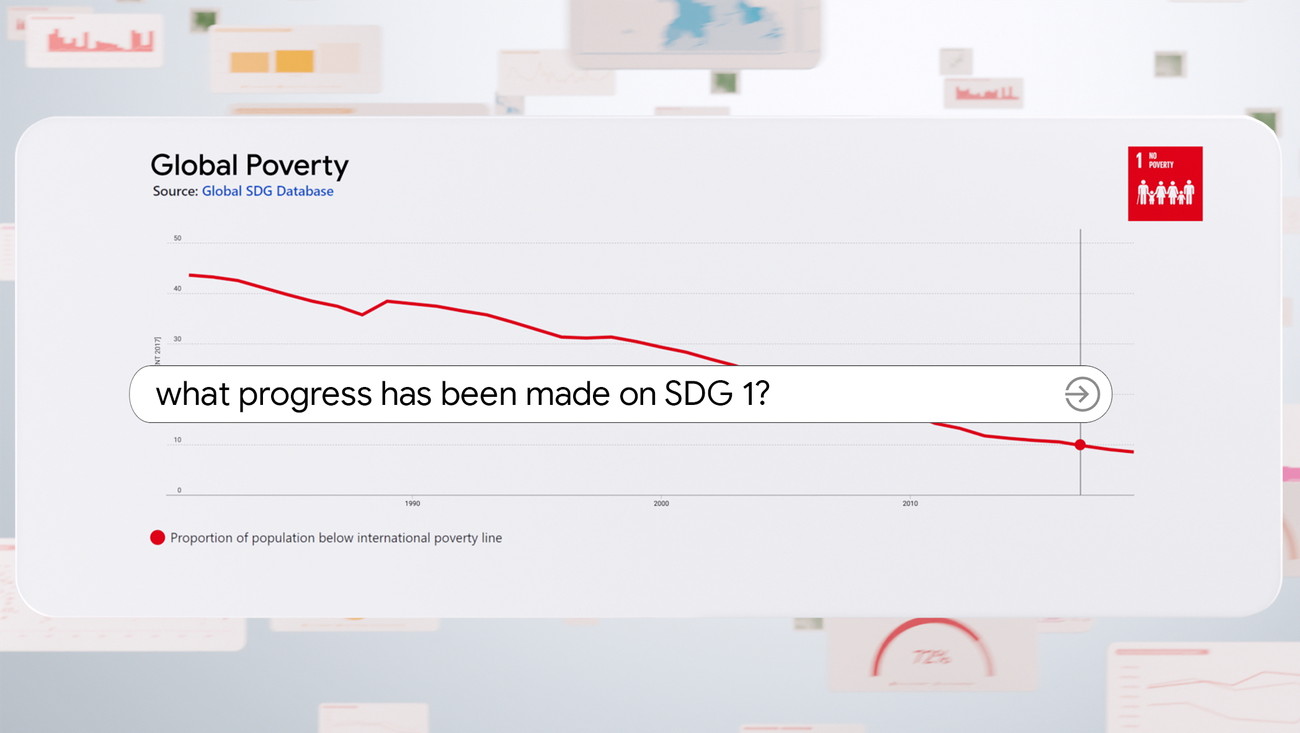
Оптимизация инвентаризации с помощью науки о данных Практическое руководство с использованием Python
Оптимизация инвентаризации с помощью науки о данных' - 'Optimizing inventory with data science' 'Практическое руководство с использованием Python' - 'Practical guide using Python
Часть 1: Понятное введение в реализацию марковского процесса для оптимизации запасов.

Вступление
Оптимизация запасов похожа на решение сложной головоломки. Как широкая проблема, она возникает во многих областях и сводится к определению количества продуктов для заказа в вашем магазине.
Представьте себе владельца веломагазина, который заказывает новые велосипеды для продажи. Но здесь возникает сложная ситуация. Если он заказывает слишком много велосипедов для магазина, то будет тратить слишком много на их обслуживание и хранение. С другой стороны, если он заказывает меньше велосипедов, то может не хватить велосипедов для удовлетворения потребностей клиентов, что приведет к потере прибыли и репутации.
Ему нужна оптимальная “стратегия”, которая поможет ему принимать лучшее ежедневное решение о том, сколько заказывать, чтобы обеспечить долгосрочную прибыль для его запасов.
Таким образом, в контексте этой проблемы ученые-данные с знаниями программирования и моделирования могут сыграть важную роль в определении этой лучшей “стратегии”. Однако нам нужны некоторые основные знания, чтобы достичь этой цели (ответить на этот вопрос). Нам нужно иметь базовое понимание о:
- Не упустите возможность! Запишитесь на БЕСПЛАТНЫЕ курсы до окончания 2023 года
- Раскрывая знания в эпоху данных
- Ведение с данными искусство рассказа с Анандом С.
- Марковском процессе,
- Марковском процессе вознаграждений
- и Марковских процессах принятия решений.
- Наконец, мы объединим эти три концепции и свяжем их с
- Динамическим программированием и
- Обучением с подкреплением
Чтобы прийти к оптимальной “стратегии”, о которой я ранее говорил. Этот блог направлен на понимание и моделирование “марковских процессов” на Python, которые будут строительным блоком для следующих шагов.
Оптимизация запасов: Могут ли Out-the-Box модели машинного обучения решить это?
Честно говоря, я написал этот блог “из-за разочарования”, чтобы увидеть, как моделируется и решается оптимизация запасов в онлайн-ресурсах. В своей докторской диссертации мне пришлось заниматься оптимизацией запасов (так как моя тема связана с последовательным принятием решений). Я провел некоторое исследование, прочитал статьи и книги и смог найти правильный подход к моделированию и “постоянному” решению этой проблемы.
Дело в том, что проблемы типа “Оптимизация запасов” являются динамическими проблемами, в которых, исходя из состояния (ситуации с запасами), необходимо адаптироваться к этой ситуации и иметь адаптивную стратегию.
Оптимизация запасов не является статической проблемой, которую можно решить статическим аналитическим методом, и ее нельзя решить с помощью готовых моделей машинного обучения / глубокого обучения. Это динамический процесс, где его компоненты должны быть поняты и моделированы, позволяя вам динамически адаптировать ежедневные решения.
Марковский процесс
Если вы являетесь аналитиком (будь то Data Scientist, Аналитик и т.д.), вы часто будете иметь дело с Процессами, которые индексируются по времени и следуют неопределенному пути. Подумайте о Data Scientist, который работает в энергетической компании. Его задача заключается в отслеживании неопределенного пути цен на товары.
Цена товара (например, нефти) будет следовать пути на временных шагах t=0,1,2,⋯. Это неопределенный процесс, который индексируется по времени. Однако, если мы хотим провести анализ, нам нужно внутренне представить процесс.
Состояние
Представьте себе Состояние как инструмент для внутреннего представления неопределенного процесса. Вернемся к примеру цен на нефть. Допустим, сегодняшняя цена на нефть составляет 100$. Я могу представить эту информацию, сказав, что S_0=100, затем цена завтра будет отличаться, и может быть представлена как S_1, и так далее S_0, S_1, S_2. Процесс представляет собой последовательность случайных состояний St∈S, где t=0,1,2,3,.. — Мы можем представить процесс следующим образом:
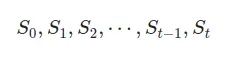
Свойство Маркова
Здесь, в этом небольшом блоге, я хочу поговорить о Процессе Маркова. Мы называем процесс (марковский), если у него есть Свойство Маркова, что означает, что переход состояний имеет следующее (свойство):
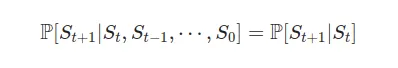
Что означает эта уравнение в более простых терминах?
Мы можем подумать о простом примере погоды. Предположим, что в один день может быть три возможных погодных условия: «Солнечно», «Дождливо» и «Снежно». Тогда, если сегодня «Солнечно»,
- Есть 70% вероятность того, что завтра будет также «Солнечно»,
- 20% шанс того, что погода завтра станет «Дождливой», и
- 10% вероятность того, что погода завтра будет «Снежной».
В этом примере погоды мы видим, что вероятность погодных условий завтрашнего дня, «Только» зависит от «Сегодняшнего дня», поэтому история погодных условий «не имеет значения». Пока погода сегодня солнечная (St=“Солнечно”), вероятность погоды завтра быть P(S_{t+1}=“Солнечно”)=0.7, P(S_{t+1}=“Дождливо”)=0.2 и P(S_{t+1}=“Снежно”)=0.1.
Давайте поработаем над простым примером из реального мира, чтобы лучше понять Процесс Маркова. Здесь пример связан с управлением запасами веломагазина и будет дополнен практическим кодированием на Python.
Простой пример управления запасами веломагазина
Вернемся к примеру веломагазина: Представьте, что у вас есть веломагазин с запасами, которые могут вместить только определенное количество велосипедов (ограниченная вместимость). Например, предположим, что ваш магазин может вместить максимум 5 велосипедов.
Каждый день в ваш магазин приходят покупатели, чтобы купить велосипеды. Предположим, что сегодня (среда) у вас в магазине есть три велосипеда. Однако вы также знаете, что завтра (четверг) будет спрос на ваш магазин, то есть некоторые из ваших велосипедов будут проданы. Вы не знаете, сколько покупателей будет завтра, что означает, что точный спрос на велосипеды завтра неизвестен. Нам нужно более точно смоделировать этот процесс, смоделировать, как меняется состояние запасов и как он развивается. ¹
Описание проблемы
В этом блоге наша основная цель – Процесс Маркова. Это означает, что в этом блоге у нас будет (предположим) фиксированная политика (в этом случае политика – это количество велосипедов, которые заказываются каждый день). Чтобы смоделировать Процесс Маркова в этом примере, сначала нам нужно определить эту проблему (что такое состояние?). Во-вторых, нам нужно построить модель перехода состояний.
Состояние (внутреннее представление процесса) можно описать двумя компонентами:
- α : количество велосипедов, которые уже есть в магазине
- β : количество велосипедов, которые были заказаны в предыдущий день и прибудут завтра утром (эти велосипеды находятся на грузовике)
Последовательность цикла 24 часа
Последовательность событий в цикле 24 часа для этого веломагазина выглядит следующим образом:
- В 18:00: вы наблюдаете состояние S_t:(α,β)
- В 18:00: вы заказываете новые велосипеды, равные max(C−(α+β),0)
- В 6:00: Вы получаете велосипеды, которые вы заказали 36 часов назад
- В 8:00: Вы открываете магазин
- С 8:00 до 18:00 вы испытываете спрос i в течение дня (моделируется с использованием распределения Пуассона) подробнее ниже.
- В 18:00 вы закрываете магазин
Диаграмма ниже визуализирует эту последовательность:

Аналогично объяснению выше, St=(αt+βt) является внутренним представлением этого стохастического процесса, и в Марковском процессе мы хотим моделировать, как этот стохастический процесс развивается.
Пример, демонстрирующий 24-часовую последовательность запасов.
Давайте приведу пример. Допустим, Дэвид является владельцем веломагазина. В среду (18:00) у него в магазине есть 2 велосипеда, и один велосипед он заказал в понедельник в 18:00. Его состояние будет:
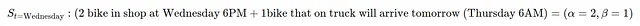
Таким образом, состояние в момент времени среда 20:00 составляет S=(α=2,β=1). Затем каждый день есть случайный (неотрицательный целый) спрос на велосипеды, спрос моделируется с помощью распределения Пуассона (с параметром λ∈R>). Спрос на i велосипедов для каждого i=0,1,2⋯ происходит с вероятностью:
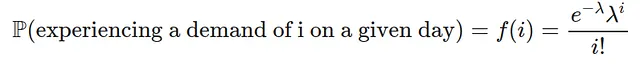
Мы можем визуализировать это распределение, чтобы увидеть вероятность различных спросов при выборе λ=2
# import matplotlib and some desired stylingimport matplotlib.pyplot as plt%matplotlib inlineplt.style.use("ggplot")plt.rcParams["figure.figsize"] = [10, 6]# need numpy to do some numeric calculationimport numpy as np# poisson is used to find pdf of Poisson distribution from scipy.stats import poisson
x_values = np.arange(0,10)# pdf Poisson distri with lambda = 1pdf_x_values = poisson.pmf(k=x_values,mu=2)plt.bar(x_values, pdf_x_values, edgecolor='black')plt.xticks(np.arange(0, 10, step=1))plt.xlabel("Спрос покупателей")plt.ylabel("Вероятность спроса покупателей")plt.title("Распределение вероятности спроса покупателей с $\lambda = 1$ ")plt.savefig("fig/poisson_lambda_2.png", dpi=300)plt.show()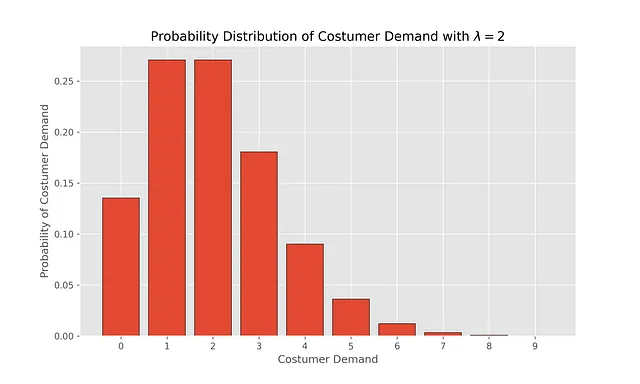
Построение вероятностного перехода Марковского процесса:
Теперь, когда у нас есть начальное понимание того, что такое состояние, St=(α,β), неопределенность, которую вводит понятие стохастического процесса, является спросом покупателей (i). Мы можем продолжить развитие вероятностного перехода в этой задаче. Я сделаю кодирование для этого, но сначала объясним это более простыми словами.
Вероятностный переход этой задачи имеет два случая, случай 1 и 2.
- Случай 1)
Если спрос i меньше общего имеющегося запаса в этот день, начальный запас = α+β
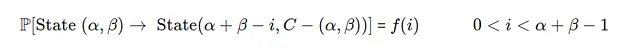
- Случай 2)
Если спрос i больше общего имеющегося запаса в этот день, начальный запас = α+β
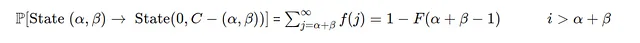
Где F(α+β−1) – это функция распределения Пуассона.
Поняв фоновую информацию по этой проблеме, мы можем написать некоторый код на Python, чтобы лучше ее понять. Основной аспект этого кода на Python – разработка структуры данных для хранения переходов процесса Маркова. Для этого я разрабатываю структуру данных в виде Словаря, который я называю “MarkovProcessDict”. Ключи этого словаря соответствуют текущему состоянию, а значения (представленные в виде словаря) – следующим состояниям, вместе с вероятностями, связанными с каждым следующим состоянием. Вот пример того, как выглядит структура данных MarkovProcessDict:
from typing import DictMarkovProcessDict = {"Текущее состояние A":{"Следующее состояние 1, от A": "Вероятность следующего состояния 1, от A", "Следующее состояние 2, от A": "Вероятность следующего состояния 2, от A"}, "Текущее состояние B":{"Следующее состояние 1, от B": "Вероятность следующего состояния 1, от B", "Следующее состояние 2, от B": "Вероятность следующего состояния 2, от B" }}MarkovProcessDict
Давайте разберем, что означает структура данных MarkovProcessDict. Например, начальное состояние – “Текущее состояние A”, которое может перейти к двум новым состояниям:
- 1) “Следующее состояние 1, от A”, с вероятностью “Вероятность следующего состояния 1, от A“
- 2) “Следующее состояние 2, от A”, с вероятностью “Вероятность следующего состояния 2, от A“.
Практическое программирование
Давайте напишем код для создания структуры данных MarkovProcessDict, с учетом двух различных случаев этого процесса, объясненных ранее.
MarkovProcessDict: Dict[tuple, Dict[tuple, float]] = {}user_capacity = 2user_poisson_lambda = 2.0
# Мы рассматриваем все возможные состояния# С которыми мы можем столкнуться в работе этого веломагазинаfor alpha in range(user_capacity+1): for beta in range(user_capacity + 1 - alpha): # Это St, текущее состояние state = (alpha, beta) # Это начальный инвентарь, общее количество велосипедов у вас в 8 утра initial_inventory = alpha + beta # beta1 - это beta в следующем состоянии, независимо от #текущего состояния (поскольку политика принятия решений постоянна) beta1 = user_capacity - initial_inventory # Список всех возможных спросов, с которыми вы можете столкнуться for i in range(initial_inventory +1): # если начальный спрос может удовлетворить спрос if i <= (initial_inventory-1): # вероятность того, что возникнет конкретный спрос transition_prob = poisson.pmf(i,user_poisson_lambda) # Если мы уже определили состояние в наших данных # (MarkovProcessDict) if state in MarkovProcessDict: MarkovProcessDict[state][(initial_inventory - i, beta1)]= transition_prob else: MarkovProcessDict[state] = {(initial_inventory - i, beta1):transition_prob } # если начальный спрос не может удовлетворить спрос else: # вероятность того, что не будет удовлетворен спрос transition_prob = 1- poisson.cdf(initial_inventory -1, user_poisson_lambda) if state in MarkovProcessDict: MarkovProcessDict[state][(0, beta1)]= transition_prob else: MarkovProcessDict[state] = {(0, beta1 ):transition_prob }В приведенном выше коде цикл for перебирает все возможные комбинации состояний, и каждое состояние (St) переходит в следующее состояние (S_{t+1}) с вероятностью “transition_prob”. Мы можем вывести динамику системы с помощью следующего кода:
or (state, value) in MarkovProcessDict.items(): print("Текущее состояние: {}".format(state)) for (next_state, trans_prob) in value.items(): print("Следующее состояние: {} с вероятностью {:.2f}".format(next_state, trans_prob))
Визуализация конечной структуры данных
Один из способов понять эти динамики — использовать пакет graphviz для Python, где каждый узел представляет собой текущее состояние, а ребра показывают вероятность перехода из одного состояния в другое.
# импорт пакетаimport graphviz # определение начальной структуры графа визуализации d = graphviz.Digraph(node_attr={'color': 'lightblue2', 'style': 'filled'}, )d.attr(size='10,10')d.attr(layout = "circo")for s, v in MarkovProcessDict.items(): for s1, p in v.items(): # представление альфы и беты с помощью s[0] и s[1] d.edge("(\u03B1={}, \u03B2={})".format(s[0],s[1]), # представление p как вероятности перехода из текущего состояния в новое состояние "(\u03B1={}, \u03B2={})".format(s1[0],s1[1]), label=str(round(p,2)), color="red") print(d)
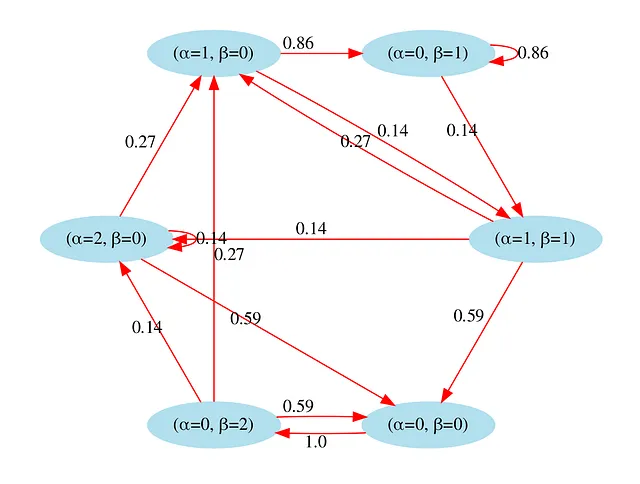
На нижеприведенном графике я визуализировал графики этого перехода. Например, если мы находимся в состоянии St = (α=1,β=0) (круг в верхнем левом углу), то существует 86% вероятность, что следующее состояние будет S(t+1):(α=0,β=1), и 14% вероятность, что следующее состояние будет S(t+1):(α=1,β=1).
Заключительные заметки
- Оптимизация запасов — это не статическая оптимизационная задача; скорее, это последовательное принятие решений, требующее адаптивной политики для принятия наилучшего решения с учетом неопределенности на каждом временном этапе.
- В этой статье я попытался построить математическую модель для отслеживания процесса управления запасами (с использованием состояний и процесса Маркова) и визуализировал динамику процесса с помощью практического программирования на Python.
- Эта статья является основой для работы с проблемами оптимизации запасов, где на следующих этапах мы будем работать с Марковским вознаграждением и Марковским процессом принятия решений.
[1] Вы можете прочитать этот пример более подробно в книге «Основы обучения с подкреплением с применением в финансах». Однако я переписал коды Python в этой статье, чтобы его было проще понять.
Спасибо за чтение до конца!
Я надеюсь, что этот материал предоставил понятное руководство по оптимизации запасов с помощью Python.
Если вы считаете, что этот материал помог вам узнать больше о оптимизации запасов и процессе Маркова, пожалуйста, поставьте 👏 и подпишитесь!