Как построить и управлять портфелем данных
Управление данными в портфеле
Пошаговый подход
Данные (или продукты), представляющие собой набор подготовленных данных или информации, которые легко использовать для определенных случаев использования, являются главным трендом в области управления данными. Умение определить, создать и управлять отдельным продуктом данных — это одно, но как начать делать это на предприятии? С чего начать?
Лидеры в области использования данных, в частности главные директора по данным, сталкиваются с этой проблемой мобилизации. В этой точке зрения мы рассмотрим, как можно подойти к данным в виде портфеля. Фигура 1 ниже представляет пошаговый подход, а остальная часть этой статьи будет подробно описывать 7 шагов. В ходе изложения мы объясним как сам подход, так и методологию, включая примеры.
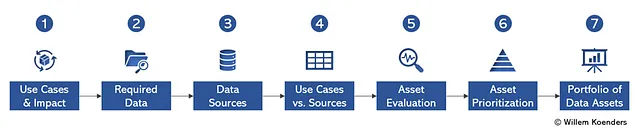
В различных примерах из реальной жизни я использовал этот подход, но чтобы избежать подозрений, что данные поступают от конкретного клиента, показывая при этом, как можно использовать генеративный искусственный интеллект для действенного применения, я использовал ChatGPT 4.0 для создания примеров. Полный диалог доступен здесь.
Шаг 1: Случаи использования и влияние
Первым шагом является определение случаев использования данных, которые имеют значение для вашей организации. Вам не нужно делать это для всего предприятия сразу — вы можете начать с одной области или бизнес-линии, и это может быть даже рекомендовано.
- Использование React для создания интерактивных интерфейсов к захватывающим наборам данных.
- AccelData приобретает Bewgle крупный шаг в области видимости данных AI Pipeline
- Важная роль аннотации данных в успехе машинного обучения
Случаи использования представляют собой конкретные механизмы, с помощью которых может быть реализована общая стратегия организации. Стратегия данных и управление данными не приносят пользы самы по себе — они приносят пользу только в том случае, если достигаются более широкие стратегические цели. Поэтому случаи использования должны быть первым шагом.
Существует несколько способов действовать. Вы можете внутренне создать инвентарь случаев использования, проведя интервью с бизнес-лидерами и аналитиками. Для вашего сектора вы можете составить обзор случаев использования из внешних источников. Чаще всего успех достигается с помощью гибридного подхода — привлекайте внешний список случаев использования, а затем уточняйте этот список с внутренними лидерами.
Как уже объяснялось выше, для целей этой статьи я использовал ChatGPT 4.0 для создания инвентаря, который представлен на Фигуре 2 ниже. Например, в разделе “Финансы и бухгалтерия” случай использования обнаружение и предотвращение мошенничества использует аналитику в режиме реального времени и модели машинного обучения на основе комбинации данных о клиентах и транзакциях для распознавания паттернов и выявления подозрительных событий. Или, например, в разделе “Маркетинг и продажи”, как часть моделирования маркетингового микса, исследуется историческая связь между маркетинговыми усилиями и результатами продаж для оптимизации распределения маркетинговых бюджетов и использования каналов и тактик.
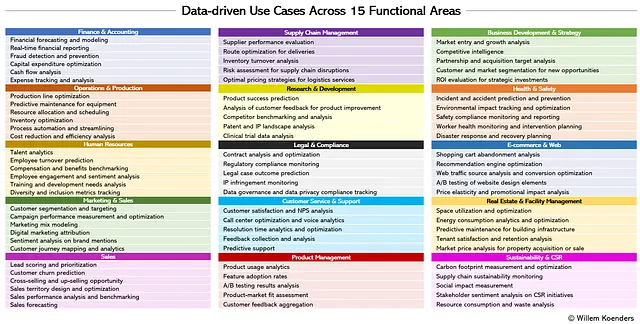
Наличие случаев использования недостаточно — нам нужно понимание их важности. Существует 4 основных способа, которыми случаи использования могут приносить пользу:
- Увеличение доходов
- Снижение затрат
- Улучшение опыта клиента
- Снижение рисков
Некоторые перечисляют “стимулирование инноваций” как пятый фактор, но на мой взгляд это лишь вопрос времени, потому что любая инновация в конечном итоге должна приносить пользу через вышеупомянутые 4 механизма.
Теперь, на Фигуре 3, у нас есть обзор маркетинговых случаев использования и типичного “влияния на верхнюю линию”, связанного с ними. Фактически, для случая использования моделирования маркетингового микса (“MMM”), который мы только что ввели, мы видим “1–2% влияния на верхнюю линию”. Если ваша компания в среднем имеет $1 миллиардов доходов, эти оценки показывают, что моделирование маркетингового микса может приносить $10–20 миллионов сверх этого.

По окончании шага 1 у вас есть набор сценариев использования вместе с оценкой их влияния на организацию.
Шаг 2: Требуемые данные
На этом шаге мы исследуем, какие данные необходимы для реализации выявленных сценариев использования. Первым шагом является определение критических входных данных для сценариев использования. Например, для оптимизации линейки продуктов в рамках Операций требуются данные о объеме производства, журналы работы машин и наличие сырья. Или, для прогнозирования текучести кадров в рамках кадровой службы требуются данные из опросов удовлетворенности сотрудников, обратной связи из собеседований на уход и показателей текучести в отрасли.
Когда у вас есть частичный или полный список сценариев использования, соответствующие эксперты или владельцы процессов могут помочь уточнить, какие данные необходимы. По мере роста списка критических входных данных вы достигнете точки, где сможете начать группировать данные по типам или областям данных. В пределах отраслей и, в меньшей степени, между отраслями эти типы и области данных фактически довольно стабильны. Почти всегда применимы следующие области данных: Клиент (или эквивалент клиента, такой как студент, пациент или участник), Сотрудник и Финансы, поскольку большинство организаций обслуживает определенную группу людей, имеет сотрудников для этого и нуждается в управлении бюджетами. Некоторые другие области, такие как Цепь поставок или Исследования и безопасность, более специфичны и могут применяться только в случае управления организацией физической цепью поставок продуктов и материалов.
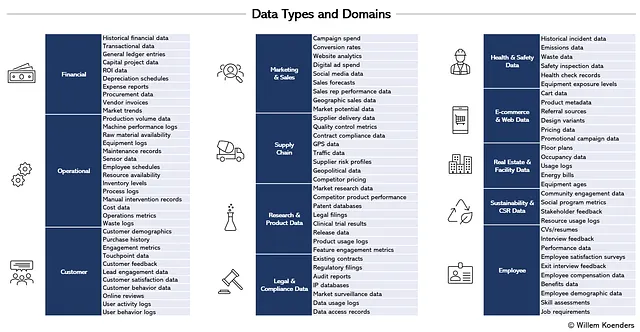
Рисунок 4 показывает, каким может быть результат. Там представлены 12 областей данных с примерно 100 подобластями. Все данные организации могут быть отнесены к перечисленным здесь типам данных. Например, данные о затратах на кампанию в рамках маркетинга и продаж могут включать данные о мероприятиях и затратах на цифровую рекламу, традиционные медиа-кампании и спонсорство, а данные с датчиков в рамках операций могут включать данные с датчиков температуры, установленных в зонах хранения, и датчиков вибрации для контроля состояния оборудования на производстве.
Как только вы начнете определять критические входные данные для сценариев использования и сопоставлять эти данные с типами или областями данных, вы можете начать создавать матрицу, подобную Рисунок 5. В приведенном примере сценарий использования оптимизации линейки продуктов сопоставлен с областью данных Операций, так как он действительно требует операционных данных. В Рисунке 5 сценарии использования сопоставлены с более широкими областями данных, чтобы обеспечить их визуализацию, но на практике вы можете (и должны) сопоставлять сценарии использования с более подробными подобластями данных.
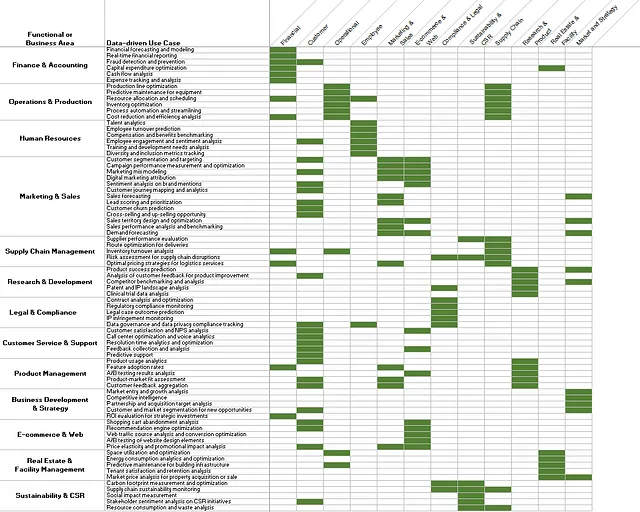
Панорамное понимание только этого — ключевых сценариев использования, сопоставленных с требуемыми ими типами данных входа — уже бесценно для разработки стратегии данных и приоритизации конкретных областей данных… но мы собираемся пойти еще дальше и сделать это еще более действенным.
Шаг 3: Источники данных
Прежде чем мы перейдем к шагу идентификации источников данных на основе (логических) требований данных из Шага 2, давайте возьмем одну группу сценариев использования и оценим необходимые для них данные. Рисунок 6 ниже показывает обзор сценариев использования в маркетинге и продажах и критические данные, на которых они основаны. Это соответствует тому, что показано на Рисунке 5, только на более высоком уровне детализации.
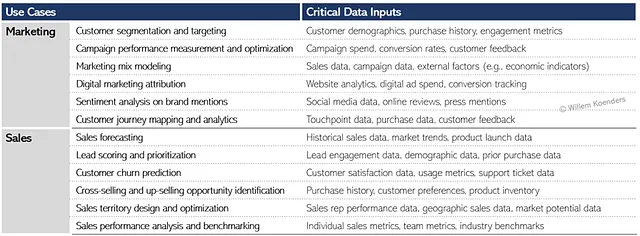
Например, мы видим, что для первого варианта использования сегментации и таргетинга клиентов требуются данные о демографии клиентов. Для данной компании эти данные хранятся в физической системе под названием Global CRM. Аналогично, данные о истории покупок, необходимые тому же варианту использования, хранятся в двух системах: истории электронной коммерции и системе розничных точек продаж.
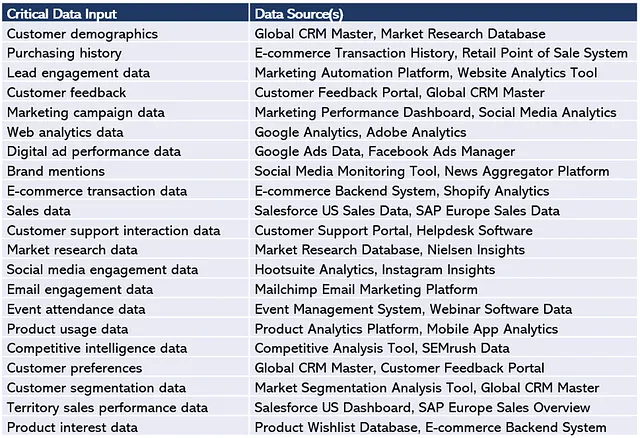
И так далее. Если мы возьмем все критические входные данные из Рисунка 6 выше и определим источники данных, мы получим таблицу Рисунка 7. Как видите, некоторые источники данных содержат несколько типов критических данных. Например, Global CRM Master содержит данные о демографии клиентов, а также предпочтения клиентов, отзывы клиентов и данные о сегментации клиентов.
Шаг 4: Варианты использования по отношению к источникам данных
Мы определили требуемые данные для вариантов использования (Шаг 2) и затем сопоставили их с источниками данных (Шаг 3). Следующий вид, который может быть создан, – это сопоставление вариантов использования с источниками данных, которое для маркетинга и продаж показано на Рисунке 8 ниже.
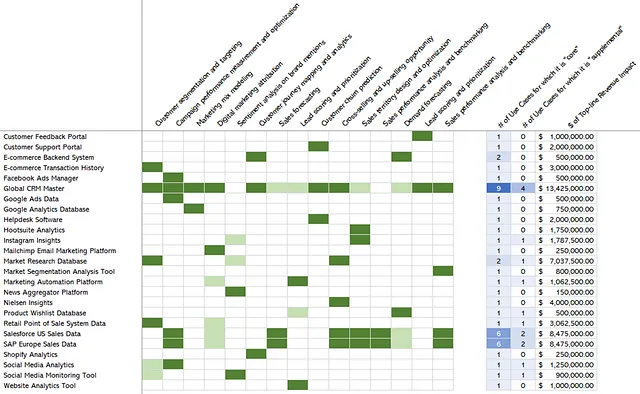
Здесь темно-зеленым цветом обозначается, что данные являются критическими для варианта использования, а светло-зеленым цветом они являются “приятными” или вспомогательными. Например, для сегментации и таргетинга клиентов данные из Global CRM Master являются критическими, но данные из аналитики социальных медиа являются “приятными”.
Но мы уже знаем гораздо больше о вариантах использования. Фактически, на Шаге 1 выше первое, что мы сделали, – это определили варианты использования и инкрементальные доходы, которые эти варианты использования могут принести. Это позволяет нам сказать что-то о создании стоимости, которая зависит от конкретных источников данных. Потому что если мы знаем, что определенный набор данных критичен для 3 вариантов использования, которые оцениваются в 2, 3 и 5 миллионов долларов инкрементального дохода соответственно, мы можем утверждать, что 10 миллионов долларов дохода зависит от этого набора данных.
Вы не можете завершить это упражнение в изоляции – вам нужно вовлечь соответствующих экспертов и владельцев вариантов использования и бизнес-процессов. Потребуется некоторое время, чтобы найти этих людей, но как только вы их найдете, вы обычно обнаружите, что они готовы сотрудничать, потому что они заинтересованы в успехе варианта использования и, следовательно, в уточнении того, какие данные являются критическими и какую повышенную эффективность они могут обеспечить.
По мере продвижения вы можете начать создавать обзор, как показано справа на Рисунке 8, где оценивается влияние на общий доход всех источников данных, критических для вариантов использования в маркетинге и продажах. Здесь будьте осторожны с двойным учетом и убедитесь, что вы ясно объясняете и квалифицируете соответствующие числа; например, если для данного варианта использования с потенциалом создания стоимости в 1 миллион долларов зависят от 2 источников данных, вы не можете сказать, что два источника данных вместе обеспечивают 2 миллиона долларов.
Шаг 5: Оценка активов
На предыдущем этапе мы сопоставили использование случаев и их ценность с набором источников данных. Теперь мы знаем, что эти источники данных (могут) создавать ценность, что означает, что они имеют внутреннюю ценность для компании и, следовательно, могут считаться активами данных.
Хотя рисунок 8 уже очень показателен, он пока не позволяет нам определить приоритеты для определенных активов данных (и инвестиций в них) по сравнению с другими. Если определенный актив данных может создавать много ценности, но он уже на месте и “пригоден для использования”, дальнейшие действия могут быть не нужны.
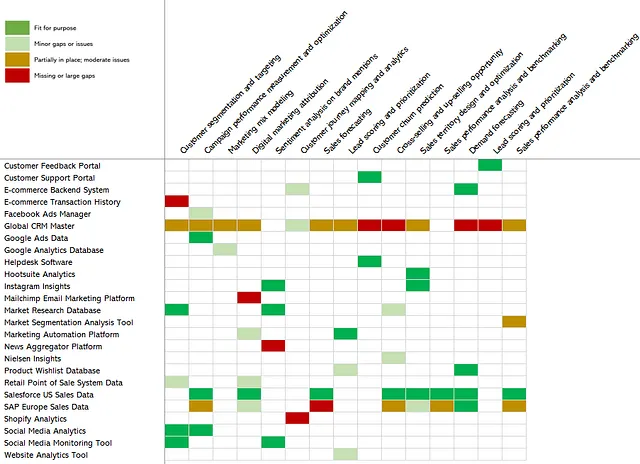
На рисунке 9 представлены четыре статуса оценки активов данных, от “пригоден для использования” до “отсутствует или большие пробелы”, которые позволяют последовательно оценивать активы данных. Здесь “пригодность для использования” следует понимать широко. В положительном смысле это означает, что правильные данные легко доступны в нужной гранулярности и своевременности; они имеют высокое качество и надежность, и источник данных никогда не отключается. В другом случае это означает, что либо актив данных вообще отсутствует, либо, если он есть, то данные в нем крайне недостаточны, ненадежны и/или неполны.

Теперь у нас есть инструменты, которые необходимы для создания так называемой “тепловой карты”, где “горячие зоны” (то есть красные или оранжевые части) указывают на возможности создания ценности, потому что там использование случаев не может полагаться на критически необходимые данные — см. рисунок 10 ниже.
Шаг 6: Приоритизация активов
Следующий шаг — приоритизация активов данных на основе всего, что мы о них сейчас знаем. На рисунке 11 представлена та же тепловая карта, что и на рисунке 10, но я добавил обратно влияние на доход и количество зависимых использования случаев. Затем я переупорядочил активы данных, организовав их в порядке убывания на основе общего влияния на доход, который они генерируют.
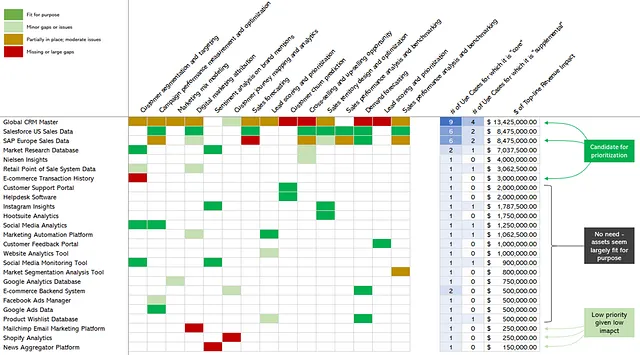
Теперь становится яснее, какие активы данных можно приоритезировать для улучшений и инвестиций. Например, становится ясно, что Глобальная CRM-система — большая проблема, так как она не оптимально обслуживает 9 (!) использования случаев, с влиянием более 13 миллионов долларов. Различные активы данных, такие как Instagram Insights, портал поддержки клиентов и данные Google Ads, пригодны для использования и, следовательно, не требуют восстановления. А также у нас есть несколько активов внизу, таких как Shopify Analytics и платформа новостного агрегатора, которые могут не быть на своем месте, но поддерживают только 1 использование случая каждый с ограниченным влиянием.
Если бы вы были главным директором по данным и этот панорамный вид отражал активы данных и случаи использования вашей организации для определенной области, для вас открывается дорожная карта, основанная на влиянии. Здесь ясно видна возможность взять один или два актива данных и использовать их как стратегическое место для улучшения управления стратегически важными данными. Это может быть использовано для внедрения и операционализации различных возможностей управления данными, таких как владение и управление данными, управление метаданными и качество данных, поскольку каждое из них является критическим для обеспечения адекватного управления активами данных.
Шаг 7: Портфель активов данных
Часто говорят, что ожидаемый срок службы лидеров данных, таких как главные директоры по данным, короток и в среднем составляет менее 2,5 лет. Это в значительной степени объясняется тем, что главные директоры по данным борются за достижение значимого бизнес-влияния в коротком или среднесрочном периоде.
Вот почему подход, описанный в этой точке зрения, настолько мощный – если вы приоритизируете данные с использованием логики, представленной в шагах 1-6, вы почти гарантированно создадите влияние. И так как вы начинаете с использования случаев и их влияния, вы вовлекаете бизнес и функциональные области с самого начала, и, следовательно, избегаете попадания в ловушку “работы с данными ради работы с данными”, что поможет избежать восприятия управления данными как издержек и помех для бизнеса.
Вы здесь еще не закончили. Данные активы, которые вы идентифицировали, аналогичны свойствам в портфеле недвижимости – вам необходимо активно управлять ими, обеспечивая их поддержку, удовлетворение пользователей данных, включение новых требований по мере их возникновения и явное отслеживание генерации стоимости со временем.
На рисунке 12 ниже показана панель управления портфелем данных для организации, которую мы анализировали в этой точке зрения. Она показывает количество подтвержденных данных, количество связанных с ними случаев использования и созданный ими доход и смягчение рисков.
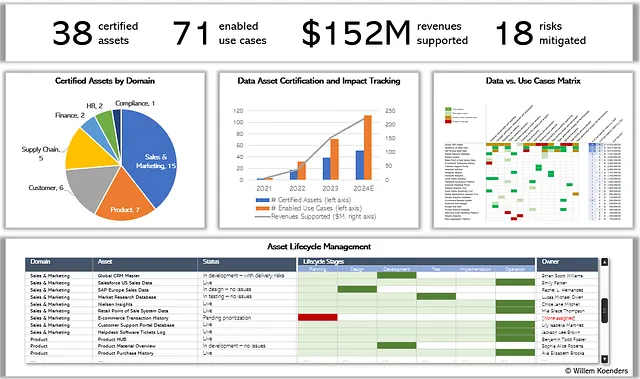
В центре вы видите график, отслеживающий количество подтвержденных данных со временем и, что более важно, количество включенных случаев использования и связанное с ними влияние на доходы. Это важно для долговечности карьеры главного данных (CDO), чтобы иметь возможность доказать создаваемую ценность через целенаправленное использование данных и управление.
Внизу вы можете увидеть представление конвейера данных. Некоторые из них проходят структурированный жизненный цикл активации, в то время как другие уже работают. Вы увидите, что глобальный мастер CRM, который мы рассматривали ранее, действительно был приоритетным – в настоящее время он находится в фазе “разработки”.
Анекдот с рынка
Как упоминалось в начале этой точки зрения, я использовал и усовершенствовал этот подход, работая с несколькими компаниями в Европе и США, а также в банковском, страховом, розничном, технологическом и производственном секторах.
В одном примере из сектора производства мы следовали слегка измененной версии 7 шагов, описанных здесь. Учитывая, что это была сложная глобальная компания, идентификация случаев использования по всей организации была невозможна. Вместо этого мы выбрали одну деловую область в качестве нашего основного фокуса, а именно коммерческое подразделение, а затем подразделы маркетинга и продаж (подобно объему случаев использования в шаге 3 выше).
Мы определили набор из ~30 случаев использования, большинство из которых уже были определены в других целях. Мы выполнили легкую, ускоренную версию шагов 2-4, чтобы определить необходимые данные и соответствующие источники и сопоставить случаи использования с источниками. Мы перешли к шагу 5 и вовлекли владельцев исследуемых случаев использования и специалистов по предметной области, спрашивая их, имеют ли они доступ к подходящим данным. Если нет, то какие данные или источник отсутствуют – в чем проблема?
Довольно быстро мы определили набор из 8 случаев использования, которым не хватало нужных данных, и обнаружили, что 6 из 8 этих случаев использования имели проблемы с 2 конкретными источниками данных. Мы не продолжали дальнейшую работу, а приступили к действию. Вместе с центральной командой данных и коммерческой командой мы согласовали владельцев для 2 источников данных, оценили их по набору формальных критериев сертификации и разработали план для устранения проблем.
Пройдя несколько месяцев, первый набор данных был улучшен и сертифицирован для удовлетворения потребностей зарегистрированных случаев использования. На момент написания точного влияния еще не было измерено (так как требуется время для реализации влияния), но первоначальное анекдотическое доказательство свидетельствовало о том, что эффективность маркетинга может увеличиться на двузначное число или даже двойное число. В любом случае, интересующийся CDO смог представить и уточнить подход, достичь скромной победы и запустить широкую дорожную карту с дополнительными активами, случаями использования и областями.
Удачи!
Создание и управление портфелем данных не всегда просто и быстро, но стоит усилий. Надеюсь, что описанные здесь шаги окажутся вам полезными. Я бы хотел услышать о ваших успехах, поэтому, если у вас есть отзывы или свои истории, не стесняйтесь делиться ими в комментариях.
Безопасных путешествий в вашем пути активации данных!






